? ? ?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?創作不易,感謝三連!!?
? ? ? 在C語言中,我們想要存儲字符串的話必須要用字符數組
char str[]="hello world"
? ? ? ?這其實是將在常量區的常量字符串拷貝到數組中,我們會在數組的結尾多開一個空間存儲\0,這樣我們如果想在訪問的時候,比如打印,我們總是認為這個字符串是會讀取到\0結束的

但是過于依賴\0也會有一系列的問題:
1、如果我是一個很長的字符串,但是中間有幾個/0,那么我很難直接打印出來全部的字符串,因為訪問到\0就會卡住

2、如果我們想通過鍵盤輸入hello world,我們把它當成一個字符串,但是cin和scanf會默認訪問到第一個空格或者是換行符就結束。

也就是說,我們的字符串如果有空格,那么還得分批次打印……
3、如果我想減少、增加、修改……這個字符串中的某些字符,也十分麻煩……如果是靜態字符數組,會面臨空間不夠的問題,如果是動態字符數組,那么我們還要時刻注意空間的管理,稍不留神就會越界訪問。
?4、雖然C語言中提供了一系列的str類的庫函數,但是這些庫函數都是以字符串分離開的,沒有把該字符串作為一個整體,并且也容易受到\0的影響。這并不符合C++面向對象的思想。
? ? ? 基于此,我們的祖師爺在想,能不能把string封裝成一個類,把它像順序表一樣管理起來,給他增設一些常用的比如增刪查改的函數接口?針對擴容進行檢查?利用構造函數和析構函數幫助我們管理內存呢??因而我們的string類就誕生了!!
一、標準庫中的string類
想要學習strling類,就要去通過他的文檔去了解
string類的文檔介紹
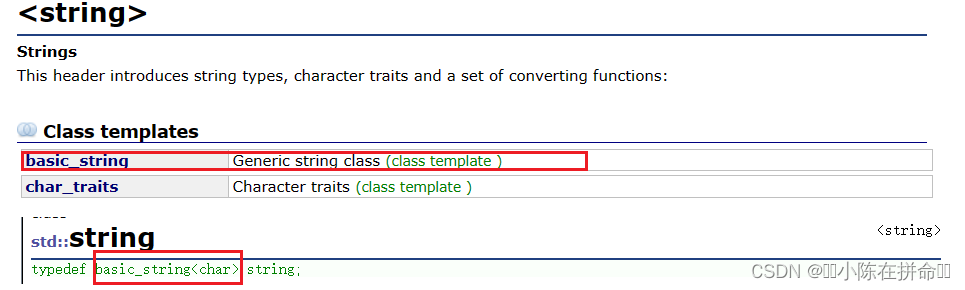
? ? ? ?誒!!我們發現string類竟然是一個叫做basic_strling的類模版生成的?難道string類還能有其他版本??沒錯!!string類有很多版本

?為什么string要有這么多版本呢??原因是這樣的:
C語言最早都是由老美發明的,他們研究出了ascii碼表

 ? ? ? ?為什么要發明這個東西呢??因為我們的語言和計算機的語言是不一樣的,計算機只能看得懂二進制的語言,所以我們為了能讓計算機看懂我們的語言,我們必須要給一個映射表,?比如我們想打印apple,那么計算機通過這個ASCII碼表來匹配,比如a對應的是97 p對應的是112 l對應的是108 e對應的是101.我們通過調試轉出10進制是可以驗證這個結果的。
? ? ? ?為什么要發明這個東西呢??因為我們的語言和計算機的語言是不一樣的,計算機只能看得懂二進制的語言,所以我們為了能讓計算機看懂我們的語言,我們必須要給一個映射表,?比如我們想打印apple,那么計算機通過這個ASCII碼表來匹配,比如a對應的是97 p對應的是112 l對應的是108 e對應的是101.我們通過調試轉出10進制是可以驗證這個結果的。

? ? ? 一個字節是8個比特位,所以最多其實可以有256個表示的方法。而美國的英文字母才26個,哪怕算上大寫,算上數字,算上一些符號,128個,也就是7bit就足夠了!!所以ASCII碼在使用英文的國家是非常友好的,每個字節都可以存儲一個字符,這樣就都可以表示出來。
? ? ? 但是老美也想把技術推廣到其他國家啊!!比如中國漢字特別多,如果全部像ASCII碼表一樣都按照一個字節的方式,那漢字遠遠不止256個啊!
? ? ? 隨著計算機的發展,不同國家也出現了很多字符編碼,但是由于字符編碼不同,計算機在不同國家之間的交流變得很困難,經常會出現亂碼的問題,比如:對于同一個二進制數據,不同的編碼會解析出不同的字符
? ? ?當互聯網迅猛發展,地域限制打破之后,人們迫切的希望有一種統一的規則, 對所有國家和地區的字符進行編碼,于是 Unicode 就出現了?
 ?unicode又有三個版本:
?unicode又有三個版本:
1、UTF-8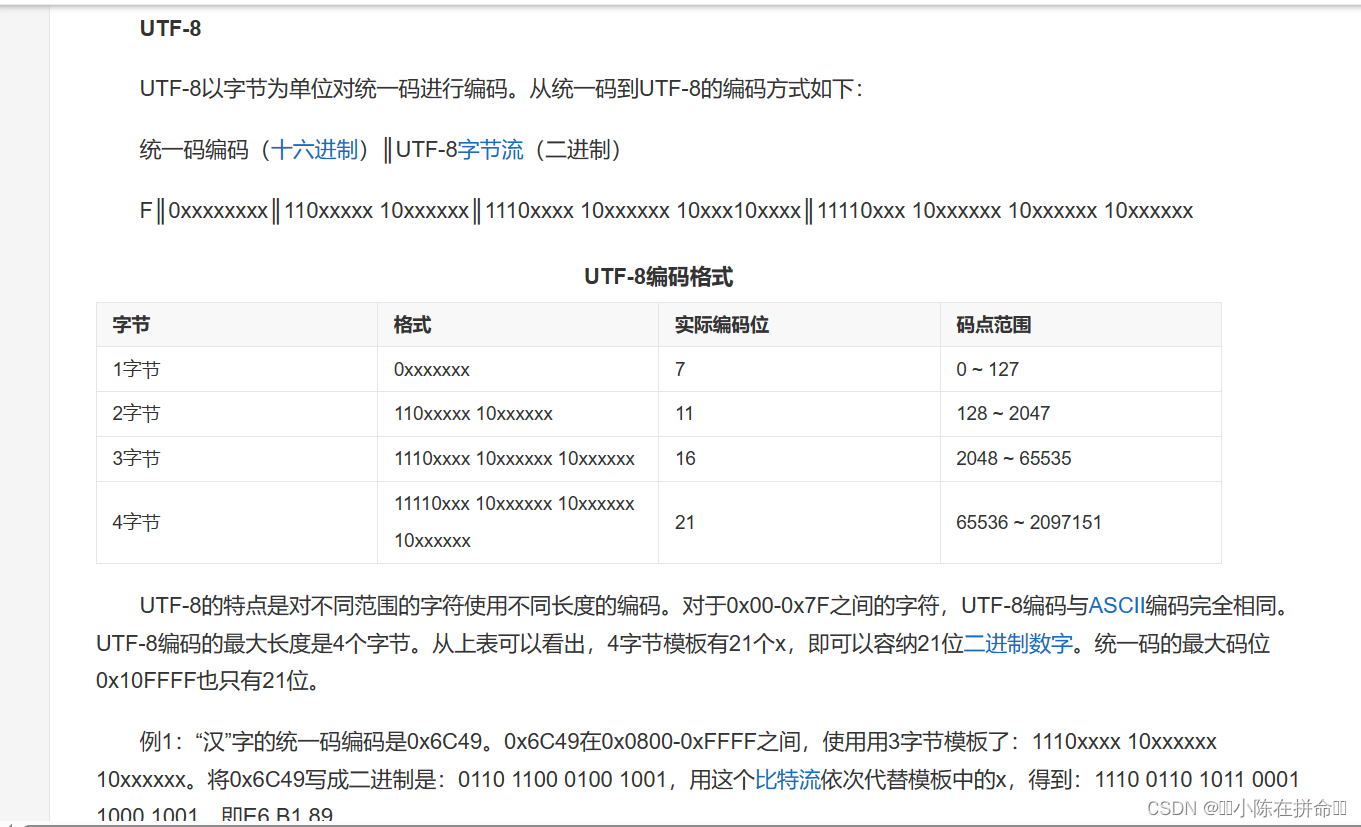
?UTF-8: 是一種變長字符編碼,被定義為將碼點編碼為 1 至 4 個字節,具體取決于碼點數值中有效二進制位的數量
UTF-8 的編碼規則:
- 對于單字節的符號,字節的第一位設為?0,后面 7 位為這個符號的 Unicode 碼。因此對于英語字母,UTF-8 編碼和 ASCII 碼是相同的, 所以 UTF-8 能兼容 ASCII 編碼,這也是互聯網普遍采用 UTF-8 的原因之一
- 對于?n?字節的符號(?n > 1),第一個字節的前?n?位都設為?1,第?n + 1?位設為?0,后面字節的前兩位一律設為?10?。剩下的沒有提及的二進制位,全部為這個符號的 Unicode 碼
?2、UTF-16
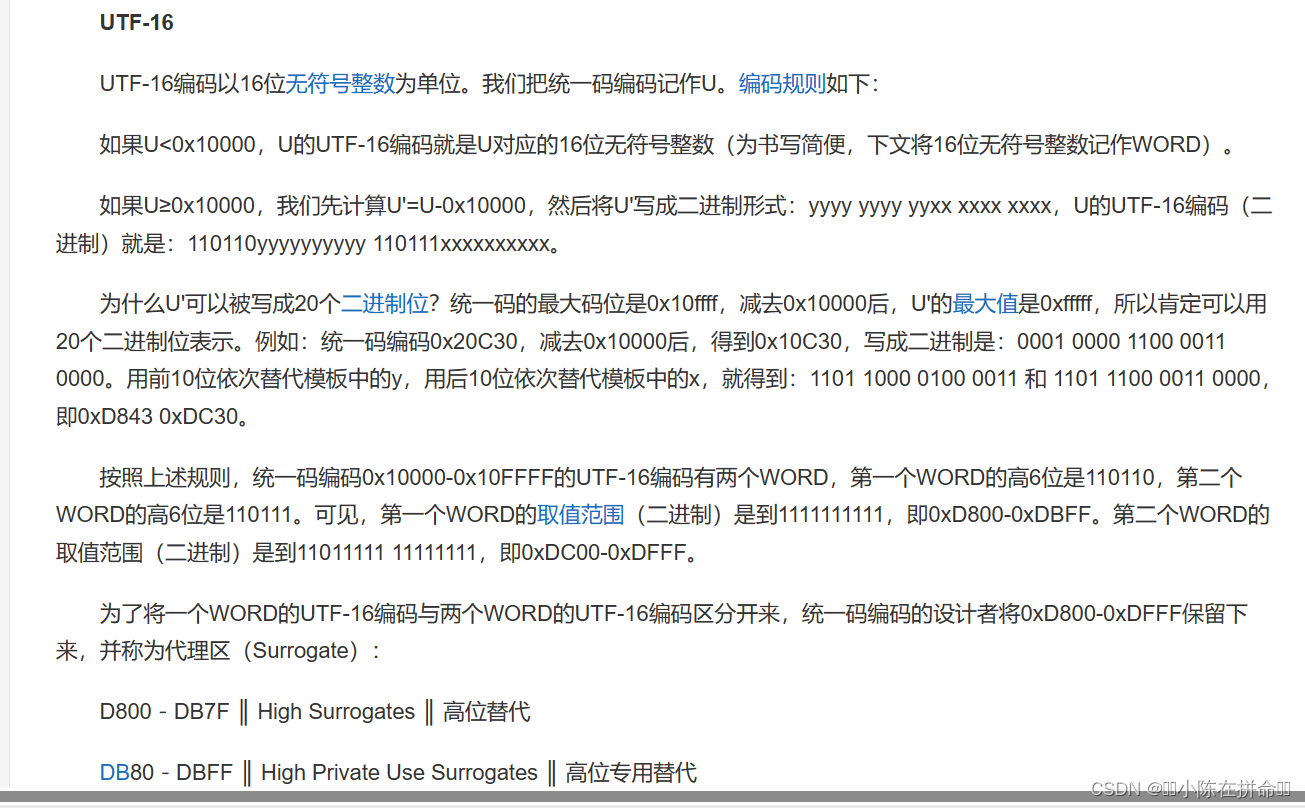
UTF-16 也是一種變長字符編碼, 這種編碼方式比較特殊, 它將字符編碼成 2 字節 或者 4 字節
具體的編碼規則如下:
- 對于 Unicode 碼小于?0x10000?的字符, 使用?2?個字節存儲,并且是直接存儲 Unicode 碼,不用進行編碼轉換
- 對于 Unicode 碼在?0x10000?和?0x10FFFF?之間的字符,使用?4?個字節存儲,這?4?個字節分成前后兩部分,每個部分各兩個字節,其中,前面兩個字節的前?6?位二進制固定為?110110,后面兩個字節的前 6 位二進制固定為?110111, 前后部分各剩余 10 位二進制表示符號的 Unicode 碼 減去?0x10000?的結果
- 大于?0x10FFFF?的 Unicode 碼無法用 UTF-16 編碼
?3、UTF-32
 ? ? ? UTF-32 是固定長度的編碼,始終占用 4 個字節,足以容納所有的 Unicode 字符,所以直接存儲 Unicode 碼即可,不需要任何編碼轉換。雖然浪費了空間,但提高了效率。
? ? ? UTF-32 是固定長度的編碼,始終占用 4 個字節,足以容納所有的 Unicode 字符,所以直接存儲 Unicode 碼即可,不需要任何編碼轉換。雖然浪費了空間,但提高了效率。
? ? ? ?UTF-8、UTF-16、UTF-32 是 Unicode 碼表示成不同的二進制格式的編碼規則,同樣,通過這三種編碼的二進制表示,也能獲得對應的 Unicode 碼,有了字符的 Unicode 碼,按照上面介紹的 UTF-8、UTF-16、UTF-32 的編碼方法 就能轉換成任一種編碼了
? ? 總結:由于UTF-8兼容ASCII,這是他的最大優勢,并且在我們日常編程中很多情況只需要一個字節就可以,雖然字節存儲的時候需要用一些比特位來區分該字符是幾個字節的,但是從效率上來說,他可以根據具體的情況去決定用幾個字節去存儲,所以互聯網大多采用UTF-8,而UTF-16也是變長,他的起點就是兩個字節,兩個字節其實可以表示完大部分國家的字符了,只有極少數古老的文字可能會需要用到4個字節。UTF-32就很粗暴,無論什么都是用4個字節,所以足夠容納所有的Unicode字符,雖然浪費了空間,但是不需要任何的編碼轉換,效率會比較高。但是使用得很少,在C11的時候引入了u32string。
?簡單介紹GBK:
? ? 但是微軟使用的主要還是GBK,Windows支持GBK的時候UTF-8還沒有普及,而微軟是一家及其看重存量客戶和兼容性的公司,形成了路徑依賴不能輕易改變。
? ? ?GBK是大部分用兩個字節表示,一些比較生僻的用三個字節表示

并且一般都是把讀音類似的編在一起
? ? ? 以上只是淺淺了解為什么string有這么多個版本,下面開始研究string類!!
二、string類的接口說明
2.1 string對象常見構造(constructor)

?我們研究幾個比較重要的
1、string()
構造空的string對象,即空字符串
2、string(const char* s)
用C-string來構造string類對象

?其實相當于將常量字符串拷貝到str中
3、string(const string&s)?
拷貝構造函數
?
拷貝構造其實是深拷貝,因為str1和str2指向的是不同的空間

4、string(size_t n, char c)
![]()
意思是用幾個相同的字符去構造

5、string (const string& str, size_t pos, size_t len = npos);

意思是,給一個string類,讀取從他的第pos個位置開始往后的len個字符。

如果len給大了,就全部打印完

?我們還注意到len如果不給,會給一個缺省值nops,nops是什么呢?

?我們可以看到npos是string類里面的一個靜態成員變量,他的值是-1,但是由于是size_t類型,所以轉化成無符號整型是一個特別大的數
所以如果我們不傳的話,也是直接拷貝完。跟傳太大是一樣的

?6、string (const char* s, size_t n);
?![]()
?給一個常量字符串,從第一個位置拷貝到第n個位置

總結: 5和6易混淆,第一個傳str類,然后從第pos個位置開始拷貝len個字符,第二個是傳常量字符串,從第一個位置拷貝到n位置。
?2.2?string類對象的容量操作(Capacity)
?1、size和length
size和length其實是一樣的, 都代表字符串的長度,但是早期STL還沒出現的時候,strling類用的是length,但是后來STL出來后,里面大部分都是用的size,所以為了保持一致性又造了一個size出來,平時用哪個都可以的。

?2、capacity
表示string當前的容量,一般來說是默認不算上/0

?這邊其實是16,但是capacity不會吧/0算進去。相當于capacity是實際容量-1
那string類究竟是如何擴容的呢?我們來用一段代碼觀察一下:

?不同編譯器存在差異,因為用的STL版本可能不一樣,我們看看g++

對比后我們可以看到區別:
? ? vs用的是PJ版STL,字符串會先被存在_Bx數組中,超過之后才會去動態開辟空間,第一次擴容是從32開始進行1.5倍擴容。而g++是SGI版STL,直接就是從0開始,然后根據情況直接開始擴容,從0開始進行2倍擴容
3、reverse

作用是提前去增加容量,擴容的效率是很低的,所以如果我們知道這個string類最多需要空間,我們一次性開好,可以減少拷貝。如果是減少的話,不會縮容。

他根據1.5倍的擴容規則,至少會擴容到超過你的要求。如果是g++的話,就是剛好到你要求的
?4、resize

會去改變size,減少的話就是變少(不會改變容量),如果增多的話就可能會擴容順便幫助我們初始化,第一個版本的話初始化補\0,第二個版本的話就是補自己想要初始化的內容



?5、empty

?字符串為空返回1,不為空返回0

6、clear
 ?清楚字符串,變成空字符串(不會縮容)
?清楚字符串,變成空字符串(不會縮容)

7、shrink_to_fit

?意思是縮容到剛好夠容納他的有效字符個數
 如上圖一開始的空間是32,然后我們將size變成5,然后進行縮容到剛好夠容納他的大小
如上圖一開始的空間是32,然后我們將size變成5,然后進行縮容到剛好夠容納他的大小

?所以前面的resize和reverse如果減少的話,都是不會改變容量大小的!!clear也不會
7、小總結
1. size()與length()方法底層實現原理完全相同,引入size()的原因是為了與其他容器的接口保持一
致,一般情況下基本都是用size()。
2. clear()只是將string中有效字符清空,不改變底層空間大小。
3. resize(size_t n) 與 resize(size_t n, char c)都是將字符串中有效字符個數改變到n個,不同的是當字符個數增多時:resize(n)用\0來填充多出的元素空間,resize(size_t n, char c)用字符c來填充多出的元素空間。注意:resize在改變元素個數時,如果是將元素個數增多,可能會改變底層容量的大小,如果是將元素個數減少,底層空間總大小不變。
4. reserve(size_t res_arg=0):為string預留空間,不改變有效元素個數,當reserve的參數小于
string的底層空間總大小時,reserver不會改變容量大小。
5.縮容的shrink_to_fit盡量不要用,意義不大,而且任何一個接口都不會幫我們縮容
2.3 string類對象的訪問及遍歷操作(Iterators)
1、operator[ ] / at
?

訪問下標為pos的字符,at和他是一樣的功能?

?2、begin+end


獲取一個字符的迭代器+獲取最后一個字符的迭代器,要用到iterator(迭代器)

可以把迭代器理解成指針,begin是開始的指針,end是指向\0的指針,注意是左閉右開!!?
如果是用const類型的迭代器,就不能修改?

至此我們知道了三種可以訪問的字符串的方法:?1、下標遍歷 2、迭代器遍歷 3、范圍for

3、rbegin+rend


跟上面差不多,只不過是從尾開始訪問

有沒有感覺string::reverse_iterator有點難寫,那用auto是不是更香

?2.4 string類對象的修改操作(Modifiers)
1、push back

尾插一個字符

2、 string::operator+=?

 ?3.append
?3.append
 (1) string& append (const string& str);
(1) string& append (const string& str);
直接尾插一個str對象

(2)string& append (const string& str, size_t subpos, size_t sublen);
從這個字符串的subpos位置往后的sublen個字符尾插

(3)string& append (const char* s)
尾插一個字符串

(4)string& append (const char* s, size_t n);
尾插字符串中的前n個字符
 ?(5)string& append (size_t n, char c);
?(5)string& append (size_t n, char c);
尾插n個字符

?一般來說我們更喜歡用+=,除非是一些特殊情況才會去用append
4,insert?

(1) string& insert (size_t pos, const string& str)和string& insert (size_t pos, const char* s);
從第pos個位置開始插入字符

(2)string& insert (size_t pos, const string& str, size_t subpos, size_t sublen)
是從被插入字符串中的subpos位置往后選len個字符插入

(3)?string& insert (size_t pos, const char* s, size_t n);
是從被插入字符串中選前n個字符插入

(4)string& insert (size_t pos, size_t n, char c);
從第pos個位置開始插入n個相同字符

5.erase?
 ?從pos位置開始往后刪除len個字符,不穿nops默認就pos后面全刪
?從pos位置開始往后刪除len個字符,不穿nops默認就pos后面全刪

一般來說insert和erase都可能設計到大量數據的移動,所以不建議使用!!?
6,pop_back

尾刪一個字符

7,replace
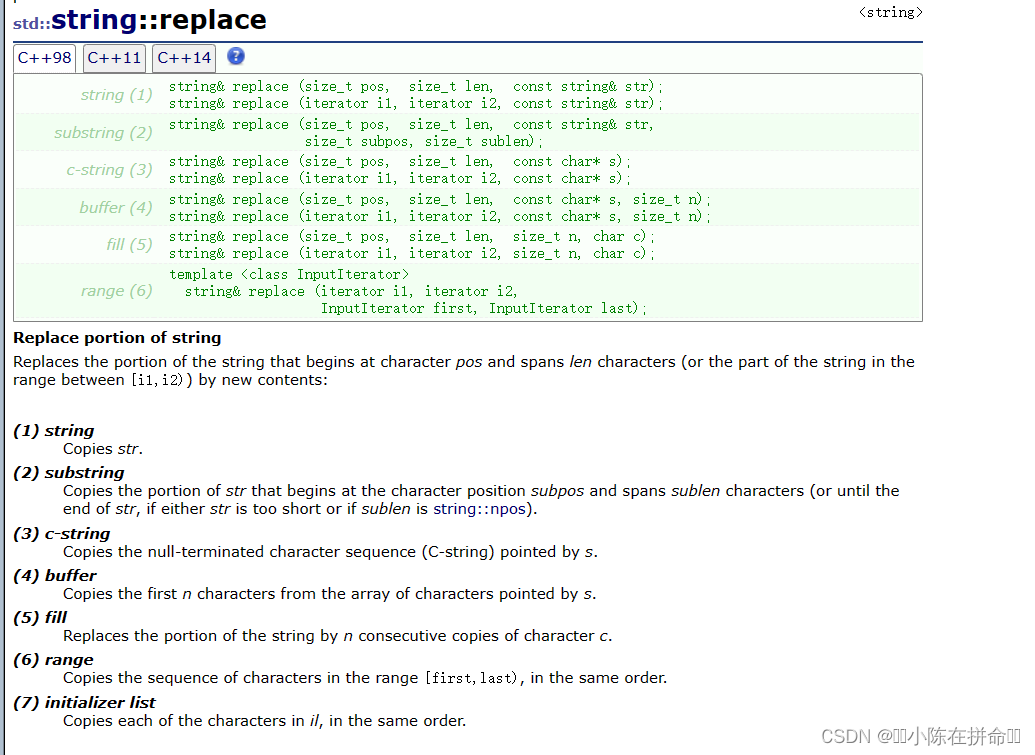
(1)string& replace (size_t pos, size_t len, const string& str)和string& replace (size_t pos, size_t len, const char* s);
將pos位置開始后面的len個字符替換成別的字符串

?(2)string& replace (size_t pos, size_t len, const string& str, size_t subpos, size_t sublen);
是從被替換字符串中的subpos位置往后選sublen個字符插入

(3)string& replace (size_t pos, size_t len, const char* s, size_t n);
是從被替換字符串中選前n個字符插入

?(4)string& replace (size_t pos, size_t len, size_t n, char c);
替換n個相同字符

8.swap

交換兩個字符串

思考:
明明全局swap也可以達到交換的效果,那string里面也實現一個swap的成員函數有必要嗎???
?
綜上,要盡量使用成員函數的swap?
2.5 string類對象的操作(operations)
1、c_str(重點)

?返回一個指向C類型的字符串指針,下面介紹他的用處:

? ? ?我們可以觀察到,s1.c_str()返回的其實是一個char*指針,但是為什么打印出來的不是地址呢??因為cout可以自動識別類型,對于char*類型的指針他會把它當成是字符串去處理,只要指針不是char*類型的,都會當成打印地址。

? ? ?我們會發現,當我們尾插‘\0’后再插入一些字符,打印出來的結果就不一樣了,因為對于c語言來說,字符串默認是讀取到\0停止,但是對于string來說,讀取多少是取決于他的成員變size!!

如果string類我們想用C語言的方法處理文件,就可以用c_str?
?2、find


?找一個字符里的子串是否存在,如果存在,返回對應的第一個字符的下標,如果不存在,就會返回string::npos。
(1)(3)(4)版本差不多,區別是一個是找string類,一個是找常量字符串,一個是找字符。pos的缺省值0,不傳的話就是從頭開始遍歷往后找,我們也可以通過pos來縮小查找的范圍。
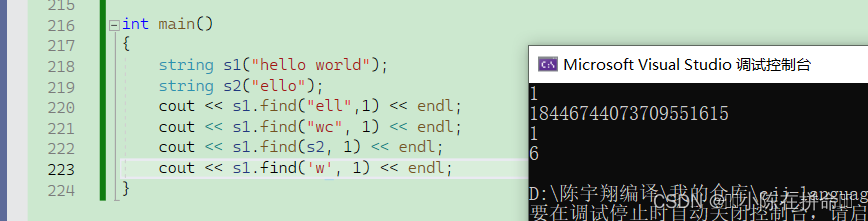
(2)版本就是 找常量字符串從pos位置開始的n個字符

?3、refind

?和find的區別就是默認是pos開始從后往前找

?4.substr

?從pos位置開始截取len個字符返回,不傳len就是默認全部返回(經常和find以及rfind配合使用)
比如我們想打印出.com,我們可以先用find去定位'.'然后再打印

?如果我們不知道幾個字符,s1.size()-pos剛好是剩下所有的字符,或者就干脆不傳,這時候相當于就是把后面的全部打印完
有些時候要從后往前找(rfind)

?如果我們想打印中間怎么辦??比如"http://www.cplusplus.com/reference/string/string/find/"我想打印出www.cplusplus.com

5.find_first_of

?找到第一個匹配的子串中任何一個字符的下標

?練習:將Please, replace the vowels in this sentence by asterisks中的abcdef全部換成*

6,find_last_of

找到最后一個與子字符串任意一個字符匹配的下標。其實可以理解從后往前找第一個
 ?7,find_first_not_of ? / find_last_not_of
?7,find_first_not_of ? / find_last_not_of
跟前兩個類似,區別就是找第一個不匹配的和找最后一個不匹配的
2.6 string類對象的非成員函數
1,operator+ (string)

盡量少用,因為傳值返回導致深拷貝效率很低
2,relational operators (string)
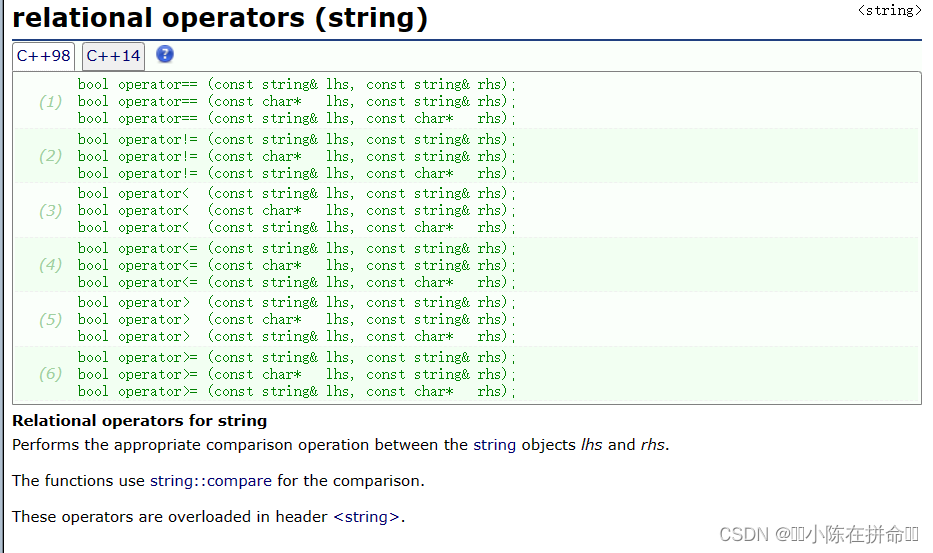
我們可以通過這些重載的操作符來比較字符串!!?
3,operator>>(string)和operator<< (string)


? ? ? ?值得注意的是,從c的字符串數組到c++的string類,原先讀取字符串是默認讀取到\0,但是封裝乘string類后他有了自己的size,所以會根據size去打印,因此是可以打印出\0的,但是>>還是跟之前的scanf一樣,默認以換行或者是空格作為標識,如果我們想打印出有空格的字符串,是行不通的!!

?因此我們想要流插入有空格的字符串,就得用getline
4.getline

?注意要包含string的頭文件




--- 函數重載)











常用命令)



