一、
雙向循環神經網絡(Bidirectional Recurrent Neural Network,BiRNN)是一種常見的循環神經網絡結構。與傳統的循環神經網絡只考慮歷史時刻的信息不同,雙向循環神經網絡不僅考慮歷史時刻的信息,還考慮未來時刻的信息。
在雙向循環神經網絡中,輸入序列可以被看作是由兩個部分組成的:正向和反向。在正向部分中,輸入數據從前往后進行處理,而在反向部分中,輸入數據從后往前進行處理。這兩個部分在網絡中分別使用獨立的循環神經網絡進行計算,并將它們的輸出進行拼接。這樣,網絡就可以獲得正向和反向兩個方向的信息,并且能夠同時考慮整個序列的上下文信息。
雙向循環神經網絡的作用是在處理序列數據時,提供更全面、更準確的上下文信息,能夠捕獲序列中前后關系,對于很多序列處理任務(例如自然語言處理、語音識別等)的效果都有很大的提升。在本代碼中,設置了 bidirectional=True,意味著使用雙向 GRU,提取的特征包含了正向和反向的信息。在 GRU 層輸出后,通過 torch.cat() 將正向和反向的最后一個時間步的隱含狀態進行拼接,從而得到一個更全面的特征表示。
二、項目簡介:根據名字中的字符來預測其是哪個國家的人
代碼:
import csv
import time
import matplotlib.pyplot as plt
import numpy as np
import math
import gzip # 用于讀取壓縮文件
import torch
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torch.nn.utils.rnn import pack_padded_sequence# 一些超參數
HIDDEN_SIZE = 100
BATCH_SIZE = 256 # 一次訓練的樣本數,為256個名字
N_LAYER = 2 # RNN的層數
N_EPOCHS = 100
N_CHARS = 128 # ASCII碼一共有128個字符
USE_GPU = False # 不好意思,我沒GPU!# 構造數據集
class NameDataset(Dataset):def __init__(self, is_train_set=True):filename = '../Data/names_train.csv.gz' if is_train_set else '../Data/names_test.csv.gz'with gzip.open(filename, 'rt') as f: # rt表示以只讀模式打開文件,并將文件內容解析為文本形式reader = csv.reader(f)rows = list(reader) # rows是一個列表,每個元素是一個名字和國家名組成的列表self.names = [row[0] for row in rows] # 一個很長的列表,每個元素是一個名字,字符串,長度不一,需要轉化為數字self.len = len(self.names) # 訓練集:13374 測試集:6700self.countries = [row[1] for row in rows] # 一個很長的列表,每個元素是一個國家名,字符串,需要編碼成數字# 下面兩行的作用其實就是把國家名編碼成數字,因為后面要用到交叉熵損失函數self.country_list = list(sorted(set(self.countries))) # 列表,按字母表順序排序,去重后有18個國家名self.country_dict = self.getCountryDict() # 字典,key是國家名,value是country_list的國家名對應的索引(0-17)self.country_num = len(self.country_list) # 18# 根據樣本的索引返回姓名和國家名對應的索引,可以理解為(特征,標簽),但這里的特征是姓名,后面還需要轉化為數字,標簽是國家名對應的索引def __getitem__(self, index):return self.names[index], self.country_dict[self.countries[index]]# 返回樣本數量def __len__(self):return self.len# 返回一個key為國家名和value為索引的字典def getCountryDict(self):country_dict = dict() # 空字典for idx, country_name in enumerate(self.country_list):country_dict[country_name] = idxreturn country_dict# 根據索引(標簽值)返回對應的國家名def idx2country(self, index):return self.country_list[index]# 返回國家名(標簽類別)的個數,18def getCountriesNum(self):return self.country_num# 實例化數據集
trainset = NameDataset(is_train_set=True)
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True)
testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset, batch_size=BATCH_SIZE, shuffle=False)N_COUNTRY = trainset.getCountriesNum() # 18個國家名,即18個類別# 設計神經網絡模型
class RNNClassifier(torch.nn.Module):def __init__(self, input_size, hidden_size, output_size, n_layers=1, bidirectional=True):super(RNNClassifier, self).__init__()self.hidden_size = hidden_size # 隱含層的大小,100self.n_layers = n_layers # RNN的層數,2self.n_directions = 2 if bidirectional else 1 # 是否使用雙向RNN# 詞嵌入層:input_size是輸入的特征數(即不同詞語的個數),即128;embedding_size是詞嵌入的維度(即將詞語映射到的向量的維度),這里讓它等于了隱含層的大小,即100self.embedding = torch.nn.Embedding(input_size, hidden_size)# GRU層:input_size是輸入的特征數(這里是embedding_size,其大小等于hidden_size),即100;hidden_size是隱含層的大小,即100;n_layers是RNN的層數,2;bidirectional是是否使用雙向RNNself.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers, bidirectional=bidirectional)# 全連接層:hidden_size是隱含層的大小,即100;output_size是輸出的特征數(即不同類別的個數),即18self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size)def _init_hidden(self, batch_size):# 初始化隱含層,形狀為(n_layers * num_directions, batch_size, hidden_size)hidden = torch.zeros(self.n_layers * self.n_directions, batch_size, self.hidden_size)return create_tensor(hidden)def forward(self, input, seq_lengths):# input shape:B X S -> S X Binput = input.t() # 轉置,變成(seq_len,batch_size)batch_size = input.size(1) # 256,一次訓練的樣本數,為256個名字,即batch_sizehidden = self._init_hidden(batch_size)# 1、嵌入層處理,input:(seq_len,batch_size) -> embedding:(seq_len,batch_size,embedding_size)embedding = self.embedding(input)# pack them upgru_input = pack_padded_sequence(embedding, seq_lengths)# output:(*, hidden_size * num_directions),*表示輸入的形狀(seq_len,batch_size)# hidden:(num_layers * num_directions, batch, hidden_size)output, hidden = self.gru(gru_input, hidden)if self.n_directions == 2:hidden_cat = torch.cat([hidden[-1], hidden[-2]],dim=1) # hidden[-1]的形狀是(1,256,100),hidden[-2]的形狀是(1,256,100),拼接后的形狀是(1,256,200)else:hidden_cat = hidden[-1] # (1,256,100)fc_output = self.fc(hidden_cat) # 返回的是(1,256,18)return fc_output# 下面該函數屬于數據準備階段的延續部分,因為神經網絡只能處理數字,不能處理字符串,所以還需要把姓名轉換成數字
def make_tensors(names, countries):# 傳入的names是一個列表,每個元素是一個姓名字符串,countries也是一個列表,每個元素是一個整數sequences_and_lengths = [name2list(name) for name innames] # 返回的是一個列表,每個元素是一個元組,元組的第一個元素是姓名字符串轉換成的數字列表,第二個元素是姓名字符串的長度name_sequences = [sl[0] for sl in sequences_and_lengths] # 返回的是一個列表,每個元素是姓名字符串轉換成的數字列表seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths]) # 返回的是一個列表,每個元素是姓名字符串的長度countries = countries.long() # PyTorch 中,張量的默認數據類型是浮點型 (float),這里轉換成整型,可以避免浮點數比較時的精度誤差,從而提高模型的訓練效果# make tensor of name, (Batch_size,Seq_len) 實現填充0的功能seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long()for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths)):seq_tensor[idx, :seq_len] = torch.LongTensor(seq)# sort by length to use pack_padded_sequence# perm_idx是排序后的數據在原數據中的索引,seq_tensor是排序后的數據,seq_lengths是排序后的數據的長度,countries是排序后的國家seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True)seq_tensor = seq_tensor[perm_idx]countries = countries[perm_idx]return create_tensor(seq_tensor), create_tensor(seq_lengths), create_tensor(countries)# 把名字轉換成ASCII碼,返回ASCII碼值列表和名字的長度
def name2list(name):arr = [ord(c) for c in name]return arr, len(arr)# 是否把數據放到GPU上
def create_tensor(tensor):if USE_GPU:device = torch.device('cuda:0')tensor = tensor.to(device)return tensor# 訓練模型
def trainModel():total_loss = 0for i, (names, countries) in enumerate(trainloader, 1):inputs, seq_lengths, target = make_tensors(names, countries)output = classifier(inputs, seq_lengths)loss = criterion(output, target)optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()if i % 10 == 0:print(f'[{timeSince(start)}] Epoch {epoch} ', end='') # end=''表示不換行print(f'[{i * len(inputs)}/{len(trainset)}] ', end='')print(f'loss={total_loss / (i * len(inputs))}') # 打印每個樣本的平均損失return total_loss # 返回的是所有樣本的損失,我們并沒有用上它# 測試模型
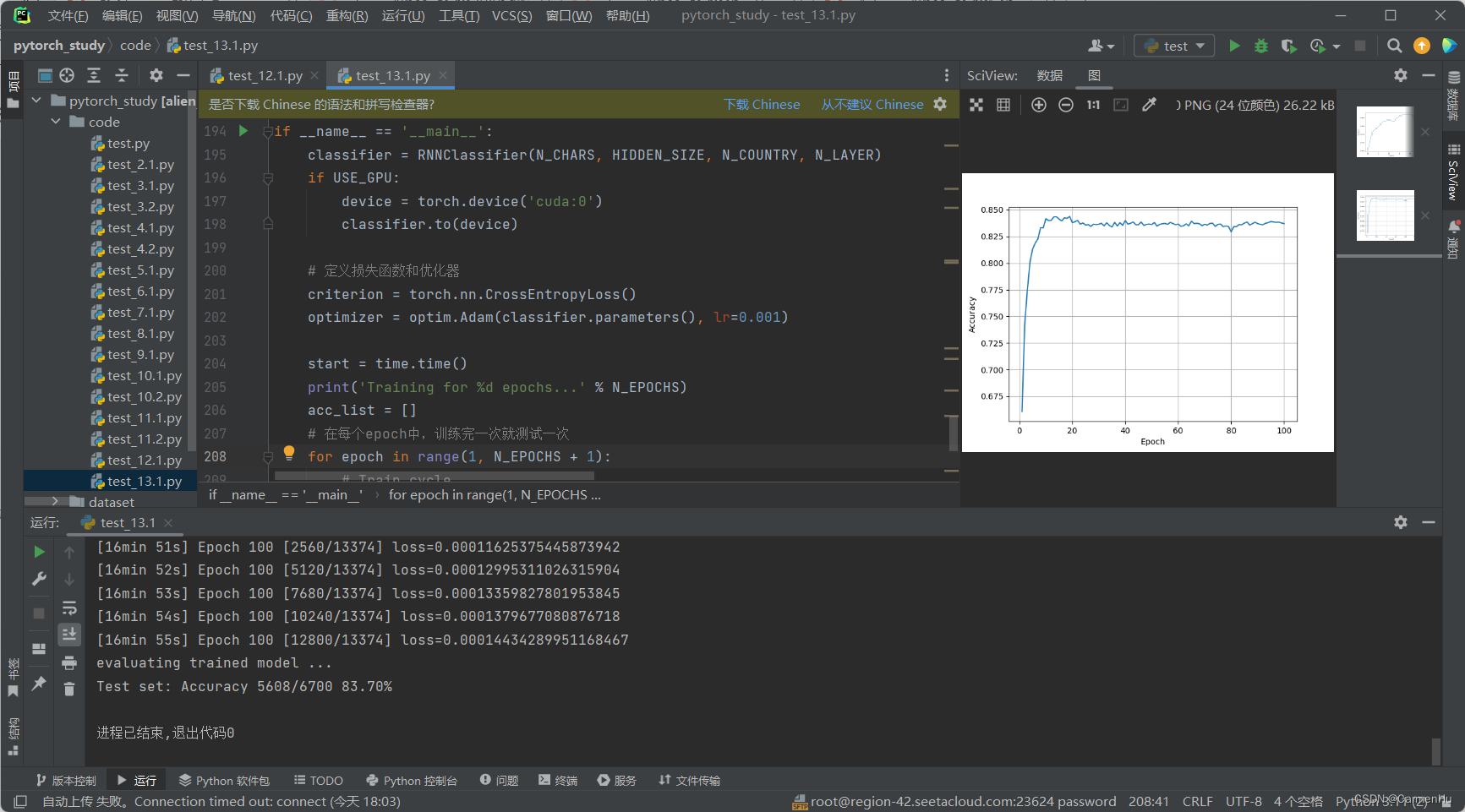
def testModel():correct = 0total = len(testset)print('evaluating trained model ...')with torch.no_grad():for i, (names, countries) in enumerate(testloader, 1):inputs, seq_lengths, target = make_tensors(names, countries)output = classifier(inputs, seq_lengths)pred = output.max(dim=1, keepdim=True)[1] # 返回每一行中最大值的那個元素的索引,且keepdim=True,表示保持輸出的二維特性correct += pred.eq(target.view_as(pred)).sum().item() # 計算正確的個數percent = '%.2f' % (100 * correct / total)print(f'Test set: Accuracy {correct}/{total} {percent}%')return correct / total # 返回的是準確率,0.幾幾的格式,用來畫圖def timeSince(since):now = time.time()s = now - sincem = math.floor(s / 60) # math.floor()向下取整s -= m * 60return '%dmin %ds' % (m, s) # 多少分鐘多少秒if __name__ == '__main__':classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)if USE_GPU:device = torch.device('cuda:0')classifier.to(device)# 定義損失函數和優化器criterion = torch.nn.CrossEntropyLoss()optimizer = optim.Adam(classifier.parameters(), lr=0.001)start = time.time()print('Training for %d epochs...' % N_EPOCHS)acc_list = []# 在每個epoch中,訓練完一次就測試一次for epoch in range(1, N_EPOCHS + 1):# Train cycletrainModel()acc = testModel()acc_list.append(acc)# 繪制在測試集上的準確率epoch = np.arange(1, len(acc_list) + 1)acc_list = np.array(acc_list)plt.plot(epoch, acc_list)plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.grid()plt.show()運行結果:


常用命令)











)




