歡迎來到《小5講堂》,大家好,我是全棧小5。
這是《Sql Server》系列文章,每篇文章將以博主理解的角度展開講解,
特別是針對知識點的概念進行敘說,大部分文章將會對這些概念進行實際例子驗證,以此達到加深對知識點的理解和掌握。
溫馨提示:博主能力有限,理解水平有限,若有不對之處望指正!

目錄
- 前言
- 創建表
- 模擬數據
- 分組查詢
- 城市分組
- 城市區縣分組
- 代理商維度
- 不同代理
- 小知識點
- identity
- 刪除數據
- 分組查詢原則
- 文章推薦
前言
最近在做數據修改,有時候太久沒寫sql語句,突然想通過子查詢的方式去批量更新數據的時候,
還是有點不知所措,那就一步一步來吧,也寫篇文章梳理和總結下,畢竟也是基本的操作加深印象。
在做數據批量修改時,有個關鍵點,就是分組查詢后找出另外一個字段不同值得記錄,因此本篇文章就針對這個查詢梳理一遍。
創建表
假設有一張表,有三個主要字段,城市名稱、區縣名稱、代理商名稱。
創建表時,習慣性給表加一個id編號,并且是自增字段,有個序號感覺看起來舒服,hhh~~~
create table test_name
(id int identity(1,1), -- 自增編號city_name nvarchar(50), -- 城市名稱area_name nvarchar(50), -- 區縣名稱agent_name nvarchar(50) -- 代理商名稱
)
模擬數據
insert into test_name(city_name,area_name,agent_name) values
('廣州市','白云區','張三'),
('廣州市','白云區','張三'),
('廣州市','白云區','李四'),
('廣州市','白云區','王五'),
('深圳市','龍崗區','張三')
上面是一次性添加多條,所以只需要寫一個values即可,也可以分開寫。
分開寫后,就能看出來重復啰嗦,所以才會有一些簡寫的方式。
insert into test_name(city_name,area_name,agent_name)
values
('廣州市','白云區','張三')insert into test_name(city_name,area_name,agent_name)
values('廣州市','白云區','張三')insert into test_name(city_name,area_name,agent_name)
values('廣州市','白云區','李四')insert into test_name(city_name,area_name,agent_name)
values('廣州市','白云區','王五')insert into test_name(city_name,area_name,agent_name)
values('深圳市','龍崗區','張三')
分組查詢
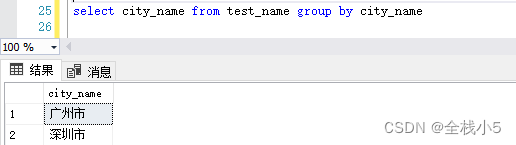
城市分組
select city_name from test_name group by city_name
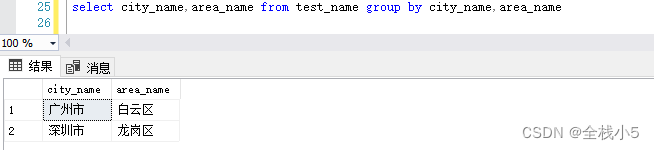
城市區縣分組
select city_name,area_name from test_name group by city_name,area_name
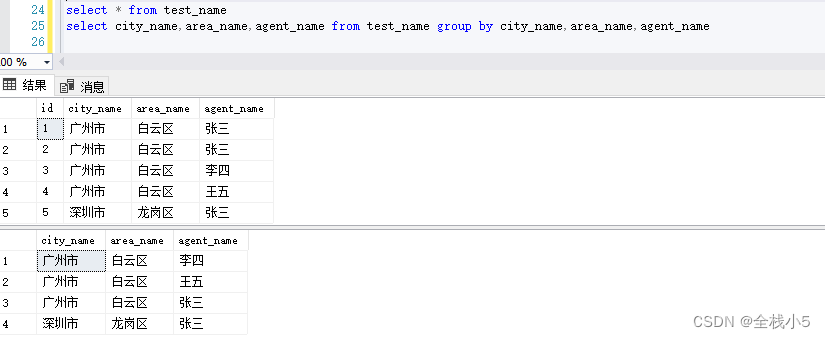
代理商維度
城市、區縣、代理商,三者組合唯一查詢
select * from test_name
select city_name,area_name,agent_name from test_name group by city_name,area_name,agent_name
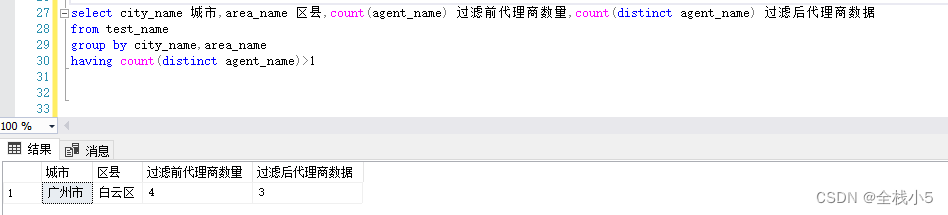
不同代理
同城市區縣,但不同代理商的記錄。
select city_name 城市,area_name 區縣,count(agent_name) 過濾前代理商數量,count(distinct agent_name) 過濾后代理商數據
from test_name
group by city_name,area_name
having count(distinct agent_name)>1
小知識點
identity
在 SQL Server 中,Identity 是一種特殊的屬性,用于指定某一列是自動生成的數字列。
通過設置 Identity 屬性,可以讓 SQL Server 自動生成唯一的數字值,并自動填充到指定的列中。
這樣可以很方便地為表中的每一行生成一個唯一的標識符。
在創建表時,可以通過以下語法向列添加 Identity 屬性:
CREATE TABLE your_table
(column_name INT IDENTITY(1,1) PRIMARY KEY,-- other columns
);在這個例子中,column_name 是指定了 Identity 屬性的列名,INT 是數據類型,IDENTITY(1,1) 表示以1為起始值,1為遞增值自動為每個新行生成一個唯一值,PRIMARY KEY 用來指定此列為主鍵。
當插入數據時,不需要為 Identity 列指定具體的值,數據庫會自動生成并填充對應的值。如果需要獲取自動生成的 Identity 值,可以使用 SCOPE_IDENTITY() 函數或者 @@IDENTITY 系統變量。
刪除數據
基于上面自增編號知識點,來了解下delete和truncate刪除數據的最大區別
delete 表名 可按條件刪除或者批量刪除記錄,并且自增id編號會繼續從當前記錄值開始算,比如最新編號為10,即使刪除編號10的記錄,那么新插入一條記錄,編號為11
truncate table 表名,全表刪除,id自增編號重新開始從1或者指定規則計算
分組查詢原則
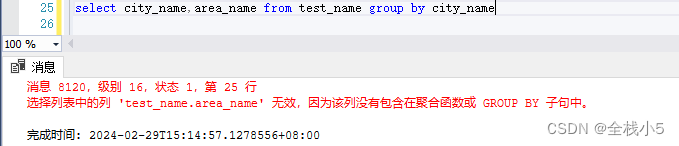
選擇列表中的列 ‘test_name.area_name’ 無效,因為該列沒有包含在聚合函數或 GROUP BY 子句中。
基本原則就是,查詢的字段值必須要在分組里,否則無效。
文章推薦
【Sql Server】新手一分鐘看懂在已有表基礎上修改字段默認值和數據類型
【數據庫】Sql Server數據遷移,處理自增字段賦值
【數據類型】C#和Sql Server、Mysql、Oracle等常見數據庫的數據類型對應關系
總結:溫故而知新,不同階段重溫知識點,會有不一樣的認識和理解,博主將鞏固一遍知識點,并以實踐方式和大家分享,若能有所幫助和收獲,這將是博主最大的創作動力和榮幸。也期待認識更多優秀新老博主。






)




)

遞增子序列、LeetCode(46)全排列、LeetCode(47)全排列 II)

)
)


