文章目錄
- SQL
- 數據完整性
- 實體完整性
- 域完整性
- 參照完整性
- default(默認值)
- comment(注釋)
- 多表設計
- 一對一
- 一對多
- 多對多
- 數據庫三大范式
- 第一范式:原子性
- 第二范式:唯一性
- 第三范式:數據的冗余
- 多表查詢
- 連接查詢
- 交叉連接
- inner join(內連接)
- outer join(外連接)
- 子查詢
- 聯合查詢
- 數據庫的備份與恢復
- cmd命令行操作
- 通過Navicat操作
SQL
數據完整性
實體完整性
列約束:MySQL可以對插入的數據進行特定的驗證,只有滿足條件才可以插入到數據表中,否則認為是非法插入。
主鍵(primary key):
- 一個表只能有一個主鍵
- 主鍵具有唯一性,主鍵不能重復
- 主鍵字段的值不能為null
- 聲明字段時,用
primary key標識 - 主鍵可以由多個字段共同組成。此時需要在字段列表后聲明的方法
eg:
create table test_primary(id int primary key,name varchar(255),address varchar(255)
);insert into test_primary values(1,"zhangsan","beijing");insert into test_primary values(1,"lisi","liaoning");select * from test_primary;出現error:
> 1062 - Duplicate entry '1' for key 'PRIMARY'
-
auto_increment(自動增長約束)
-
一些序號,沒有必須手動生成,想讓mysql自動生成。
-
自動增長必須為索引(主鍵或unique)
-
只能存在一個字段為自動增長
-
默認為1開始自動增長
-
eg:
create table test_autoincrement(id int primary key auto_increment,name varchar(255),address varchar(255)
);insert into test_autoincrement(name, address) values ("zhangsan", "beijing");insert into test_autoincrement(name, address) values ("lisi", "nanjing");insert into test_autoincrement(name, address) values ("wangwu", "jilin");-->
+----+----------+---------+
| id | name | address |
+----+----------+---------+
| 1 | zhangsan | beijing |
| 2 | lisi | nanjing |
| 3 | wangwu | jilin |
+----+----------+---------+
默認從1開始自動增長
自動增長是不是一定會連續?
- 不能
- 比如說自己手動插入了一個
id = 100的數據,則下次auto_increment從id = 101開始 - 再比如表里有
unique字段,插入了一個重復的值,導致插入失敗,會導致插入id不連續
域完整性
- null/not null
- not null:代表不允許為空,如果插入了null,則會報錯
- unique
- 不能重復
- 允許插入null
- null可以重復
unique與primary key的區別和聯系:
- 都不能存儲重復的值
primary key不能存儲null,unique能存儲null
參照完整性
- 外鍵
default(默認值)
- 如果不指定值,則使用默認值
- 如果指定了值,則就用指定的值
eg:
create table tab
( create_time timestamp default current_timestamp );-- 表示將當前時間的時間戳設為默認值。
current_date, current_time
comment(注釋)
- 給自己看的
eg:
create table test_comment(id int primary key auto_increment,name varchar(255) comment "名字",status int comment "0表示未付款,1表示已付款,2"
);
多表設計
一對一
- 一對一是指兩個表中的數據是一一對應的
- 比如:人和身份證號、用戶和用戶詳情
存儲關系:
- 一對一的情況,關系可以存儲在任意一張表上,只要新增一個字段。
- 所有的一一對應的表,在邏輯上,都可以合并為一個表,但是出于效率的考慮沒有合并
一對多
- 存在表A和表B,表A中的一條數據,對應表B中的多條數據;而表B中的一條數據,對應表A中的一條數據
- 比如:學生和班主任
存儲關系:
- 關系存儲在多的一方
多對多
- 指存在表A和表B,表A中的一條數據,對應表B中的多條數據;而表B中的一條數據,對應表A中的多條數據。
- 比如:學生和課程、訂單和商品
存儲關系:
- 需要額外一張表來存儲之間的關系
數據庫三大范式
第一范式:原子性
- 我們存儲在數據庫的列,應該保持原子性。
- 比如:地址
第二范式:唯一性
- 每一張表,需要有一個主鍵
第三范式:數據的冗余
- 數據不要冗余
- 右邊這里即存儲了班主任id又存儲了班主任姓名,造成了冗余
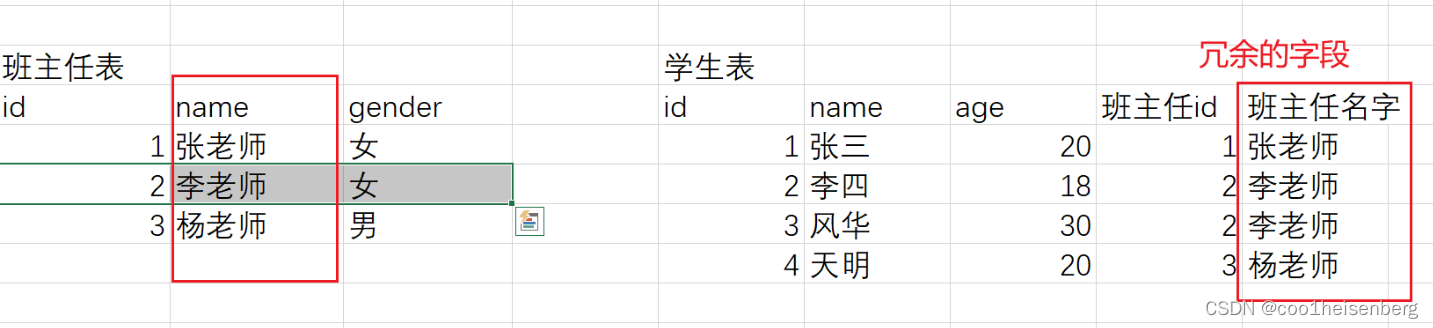
- 冗余的好處
- 查詢速度快
- 冗余的壞處
- 耗費磁盤
- 修改的時候,要修改多張表
反范式化設計:
- 如果你的需求頻繁的要根據學生找老師名
- 查詢的需求遠遠大于修改的需求
多表查詢
-- 如果user這個表存在,就去刪除
drop table if exists user;create table user(id int primary key auto_increment,name varchar(255),password varchar(255)
);
連接查詢
交叉連接
- 就是求多個表的笛卡爾積
- 交叉連接的結果沒有實際的意義
- 但是內連接和外連接都是基于交叉連接的結果去篩選的
eg:
select * from student_test cross join test_primary;-->
+------+----------+------+---------+--------+----+----------+---------+
| id | name | age | address | remark | id | name | address |
+------+----------+------+---------+--------+----+----------+---------+
| 1 | lihua | 20 | china | None | 1 | zhangsan | beijing |
| 2 | zhangsan | 18 | Asia | None | 1 | zhangsan | beijing |
| 3 | mike | 21 | china | None | 1 | zhangsan | beijing |
| 4 | Jack | 18 | china | None | 1 | zhangsan | beijing |
+------+----------+------+---------+--------+----+----------+---------+
inner join(內連接)
- 是從結果表中刪除與其他被連接表中沒有匹配行的所有行,所以內連接可能會丟失信息
eg:
-- 內連接只返回符合連接條件的數據
select * from student_test inner join test_primary on student_test.id = test_primary.id;-->
+------+-------+------+---------+--------+----+----------+---------+
| id | name | age | address | remark | id | name | address |
+------+-------+------+---------+--------+----+----------+---------+
| 1 | lihua | 20 | china | None | 1 | zhangsan | beijing |
+------+-------+------+---------+--------+----+----------+---------+-- 1. 一般會先取別名,給表取名
-- 2. 先用*來占位,最后需要什么數據,再通過 別名.屬性名拿取
select st.name,tp.address
from student_test st inner join test_primary tp on st.id = tp.id;-->
+-------+---------+
| name | address |
+-------+---------+
| lihua | beijing |
+-------+---------+outer join(外連接)
-
左外連接:會在內連接的結果的基礎之上,去和左表做并集,會保留左表的全部數據
left outer join / left join
-
右外連接:會在內連接的結果的基礎之上,去和右表做并集,會保留右表的全部數據
right outer join / right join
-
outer是可以省略的,可以寫成left join或者right join
eg:
-- 左外連接
-- 左外連接:會保存左表的全部數據
select * from student_test st left outer join test_primary tp on st.id = tp.id;-->
+------+----------+------+---------+--------+------+----------+---------+
| id | name | age | address | remark | id | name | address |
+------+----------+------+---------+--------+------+----------+---------+
| 1 | lihua | 20 | china | None | 1 | zhangsan | beijing |
| 2 | zhangsan | 18 | Asia | None | NULL | NULL | NULL |
| 3 | mike | 21 | china | None | NULL | NULL | NULL |
| NULL | Jack | 18 | china | None | NULL | NULL | NULL |
+------+----------+------+---------+--------+------+----------+---------+-- 右外連接
-- 右外連接:會保存右表的全部數據
select * from student_test st right outer join test_primary tp on st.id = tp.id;-->
+------+-------+------+---------+--------+----+----------+---------+
| id | name | age | address | remark | id | name | address |
+------+-------+------+---------+--------+----+----------+---------+
| 1 | lihua | 20 | china | None | 1 | zhangsan | beijing |
+------+-------+------+---------+--------+----+----------+---------+
每次寫數據庫的時候,在代碼前面要加上:drop table if exists 表名;,但是修改表的時候不要運行,否則寫好的數據就會清除。
inner join,left (outer) join,right (outer) join的區別:
inner join只會保留on后面條件符合的(也可以說交集)left join除了保留交集,還會保留左表的所有數據right join除了保留交集,還會保留右表的所有數據
寫關聯查詢最重要的兩件事:
- 使用什么連接
- 關聯條件
子查詢
-
又稱為嵌套查詢。
-
一個SQL語句的結果可以作為另外一個SQL語句的條件
-
子查詢很符合直覺,但是速度太慢了,能不用就盡量不要用
- 子查詢會生成臨時表
eg:
-- 首先先拿到Java的id
select id from tec_cource where name='Java';
-- 然后再把這個id=1放給第二個
select * from tec_sele_cource where cource_id=1;
select * from tec_stu where id in (1,3);---->
-- 看學生信息
select * from tec_stu where id in (-- 看哪些學生選了 Javaselect student_id from tec_sele_cource where cource_id=(-- 獲取Java的idselect id from tec_cource where name='Java')
)
聯合查詢
- SQL支持把多個SQL語句的結果拼裝起來
union將兩個SQL的結果,拼接起來返回- 兩條SQL返回的列應當一致
eg:
select * from students where class = '一班'
union
select * from students where class = '二班';等價于
select * from students where class = ('一班', '二班');數據庫的備份與恢復
cmd命令行操作
# 備份
# 1. 打開命令行
mysqldump -uroot -p dbName(數據庫的名稱) > c:/path/dbName.sql(就是要存儲的路徑名)
-- > 表示把這個數據庫輸出到哪里# 恢復
# 1. 打開命令行
# 2. 連接MySQL服務器
mysql -uroot -p# 3. 選中數據庫(假如沒有合適的數據庫,可以新建一個)
use dbName;
# 4. 執行文件中的SQL語句,恢復數據
source c:/path/dbName.sql
通過Navicat操作
- 備份
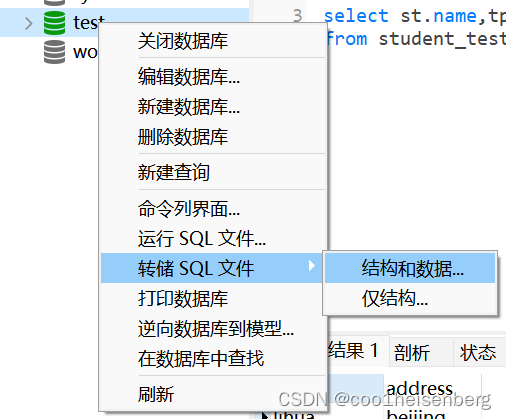
- 恢復
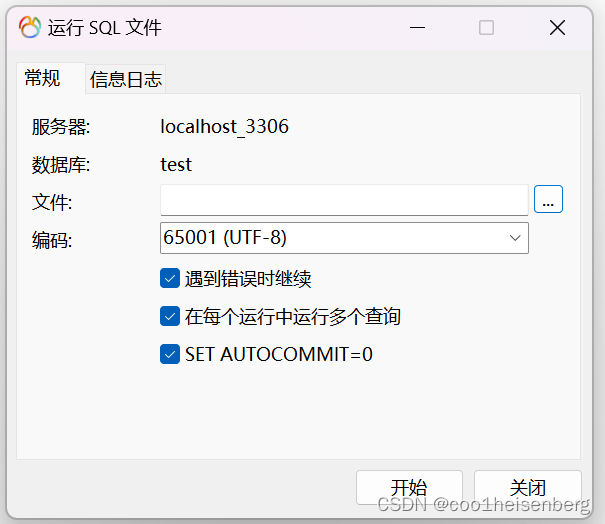





)




)

遞增子序列、LeetCode(46)全排列、LeetCode(47)全排列 II)

)
)



