時序差分(TD)是強化學習的核心,其是蒙特卡羅(MC)和動態規劃(DP)的結合。
1、TD 預測
TD 和 MC 都是利用經驗來解決預測問題。一種非平穩環境的一般訪問蒙特卡羅方法是
V ( S t ) ← V ( S t ) + α [ G t ? V ( S t ) ] V(S_t)\leftarrow V(S_t)+\alpha\left[G_t-V(S_t)\right] V(St?)←V(St?)+α[Gt??V(St?)]
MC 方法必須等到事件結束才能確定 V ( S t ) V(S_t) V(St?) 的增量(因為結束 G t G_t Gt? 才是已知的),而 TD 方法只需要等到下一個時間步長。在時間 t + 1 t+1 t+1 時,立即生成一個目標,并使用觀察到的獎勵 R t + 1 R_{t+1} Rt+1? 和估計值 V ( S t + 1 ) V(S_{t+1}) V(St+1?) 進行有用的更新,最簡單的 TD 方法更新方式如下:
V ( S t ) ← V ( S t ) + α [ R t + 1 + γ V ( S t + 1 ) ? V ( S t ) ] V(S_t)\leftarrow V(S_t)+\alpha\left[R_{t+1}+\gamma V(S_{t+1})-V(S_t)\right] V(St?)←V(St?)+α[Rt+1?+γV(St+1?)?V(St?)]
MC 方法更新的目標是 G t G_t Gt?,而 TD 方法的目標是 R t + 1 + γ V ( S t + 1 ) R_{t+1}+\gamma V(S_{t+1}) Rt+1?+γV(St+1?)。這種 TD 方法稱為 T D ( 0 ) \mathrm{TD}(0) TD(0)。
v π ( s ) ? E π [ G t ∣ S t = s ] = E π [ R t + 1 + γ G t + 1 ∣ S t = s ] = E π [ R t + 1 + γ v π ( S t + 1 ) ] \begin{aligned} v_\pi(s)&\doteq\Bbb{E}_\pi\left[G_t|S_t=s\right]\\[1ex] &=\Bbb{E}_\pi\left[R_{t+1}+\gamma G_{t+1}|S_t=s\right]\\[1ex] &=\Bbb{E}_\pi\left[R_{t+1}+\gamma v_\pi(S_{t+1})\right] \end{aligned} vπ?(s)??Eπ?[Gt?∣St?=s]=Eπ?[Rt+1?+γGt+1?∣St?=s]=Eπ?[Rt+1?+γvπ?(St+1?)]?
由上式,MC 方法使用第二行的估計值作為目標,而 DP 方法使用第三行的估計值作為目標。MC 目標是一個估計值,因為期望值是未知的,我們是用平均樣本收益代替實際的期望收益;DP 目標也是一個估計值,雖然環境模型完全已知,但是 v π ( S t + 1 ) v_\pi(S_{t+1}) vπ?(St+1?) 是未知的,使用的當前的估計值;TD 目標也是一個估計值,因為它對第三行中的期望值進行采樣,且使用的當前的估計值而不是真實的 v π v_\pi vπ?。因此,TD 方法結合了 MC 的采樣和 DP 的自舉。
另外, T D ( 0 ) \mathrm{TD}(0) TD(0) 算法中括號內是一種誤差,即狀態 S t S_t St? 的當前估計值與更好的估計值 R t + 1 + γ V ( S t + 1 ) R_{t+1}+\gamma V(S_{t+1}) Rt+1?+γV(St+1?) 的差異,這個量稱為 T D \mathrm{TD} TD 誤差( T D e r r o r TD\ error TD?error),在強化學習中以各種形式出現:
δ t ? R t + 1 + γ V ( S t + 1 ) ? V ( S t ) \delta_t\doteq R_{t+1}+\gamma V(S_{t+1})-V(S_t) δt??Rt+1?+γV(St+1?)?V(St?)
2、TD 預測的優點
顯然,TD 方法比 DP 方法有一個優勢,因為它無需環境模型已知。TD 方法比 MC 方法的一個明顯的優勢是,它以在線、完全增量的方式實現;另外 MC 方法需要等到一個回合結束,而 TD 方法只需要等待一個時間步,這很關鍵,某些特殊情形可能回合結束時間太長,甚至回合不會結束。
3、TD(0) 的最優性
假設只有有限的經驗,例如 10 個回合或 100 個時間步長,在這種情況下,增量學習方法的常見手段是反復呈現經驗,直到收斂到一個值。給定一個近似價值函數 V V V,MC 增量和 TD 增量
4、Sarsa:同策略 TD 控制
現在我們使用 TD 預測方法來解決控制問題,與之前一樣,我們遵循廣義策略迭代(GPI)的模式,與 MC 方法一樣,我們面臨著進行探索的需要,同樣,方法分為兩大類:同策略和異策略。本節提出一種同策略上的 TD 控制方法。
第一步是學習動作價值函數而不是狀態價值函數,對于同策略方法,我們必須估計 q π ( s , a ) , ? s ∈ S , ? a ∈ A q_\pi(s,a),\forall s\in\cal S,\forall a\in\cal A qπ?(s,a),?s∈S,?a∈A,一個回合由狀態和狀態-動作對的交替序列組成:
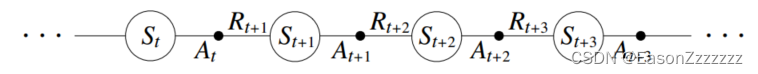
在前一章中,我們考慮從狀態到狀態的轉換,并學習了狀態的價值。現在我們考慮從狀態-動作對到狀態-動作對的轉換,并學習狀態-動作對的價值。形式上,這兩種情況是一樣的:它們都是帶有獎勵過程的馬爾可夫鏈,保證 T D ( 0 ) \mathrm{TD}(0) TD(0) 下狀態價值收斂的定理也適用于動作價值的相應算法:
Q ( S t , A t ) ← Q ( S t , A t ) + α [ R t + 1 + γ Q ( S t + 1 , A t + 1 ) ? Q ( S t , A t ) ] Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\alpha\left[R_{t+1}+\gamma Q(S_{t+1},A_{t+1})-Q(S_t,A_t)\right] Q(St?,At?)←Q(St?,At?)+α[Rt+1?+γQ(St+1?,At+1?)?Q(St?,At?)]
5、Q-learning:異策略 TD 控制
強化學習的早期突破之一就是開發了一種被稱為 Q-learning 的異策略 TD 控制算法,定義如下
Q ( S t , A t ) ← Q ( S t , A t ) + α [ R t + 1 + γ max ? a Q ( S t + 1 , a ) ? Q ( S t , A t ) ] Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\alpha\left[R_{t+1}+\gamma\max_a Q(S_{t+1},a)-Q(S_t,A_t)\right] Q(St?,At?)←Q(St?,At?)+α[Rt+1?+γamax?Q(St+1?,a)?Q(St?,At?)]


















3A5000虛擬機系統詳細教程)
