
🤵?♂? 個人主頁:@艾派森的個人主頁
?🏻作者簡介:Python學習者
🐋 希望大家多多支持,我們一起進步!😄
如果文章對你有幫助的話,
歡迎評論 💬點贊👍🏻 收藏 📂加關注+
喜歡大數據分析項目的小伙伴,希望可以多多支持該系列的其他文章
| 大數據分析案例-基于隨機森林算法預測人類預期壽命 |
| 大數據分析案例-基于隨機森林算法的商品評價情感分析 |
| 大數據分析案例-用RFM模型對客戶價值分析(聚類) |
| 大數據分析案例-對電信客戶流失分析預警預測 |
| 大數據分析案例-基于隨機森林模型對北京房價進行預測 |
| 大數據分析案例-基于RFM模型對電商客戶價值分析 |
| 大數據分析案例-基于邏輯回歸算法構建垃圾郵件分類器模型 |
| 大數據分析案例-基于決策樹算法構建員工離職預測模型 |
| 大數據分析案例-基于KNN算法對茅臺股票進行預測 |
| 大數據分析案例-基于多元線性回歸算法構建廣告投放收益模型 |
| 大數據分析案例-基于隨機森林算法構建返鄉人群預測模型 |
| 大數據分析案例-基于決策樹算法構建金融反欺詐分類模型 |
目錄
1.項目背景
2.項目簡介
2.1項目說明
2.2數據說明
2.3技術工具
3.算法原理
4.項目實施步驟
4.1理解數據
4.2數據預處理
4.3探索性數據分析
4.4特征工程
4.5模型構建
4.6模型預測
5.實驗總結
源代碼
1.項目背景
????????隨著科技的飛速發展和人們對通訊需求的不斷提高,手機已成為現代生活中不可或缺的電子產品。市場上手機品牌眾多、型號繁雜,價格也參差不齊,從幾百元到上萬元不等。對于消費者而言,如何在眾多手機中選擇適合自己需求和預算的產品成為了一大挑戰。
????????為了幫助消費者更好地進行手機購買決策,并為企業提供市場定價策略參考,本研究旨在構建一個基于SVM支持向量機算法的手機價格分類預測模型。通過該模型,我們希望能夠準確地將手機產品根據其價格劃分到不同的類別中,從而為消費者提供一個快速篩選符合預算范圍的手機的方法,同時也為企業分析市場競爭格局和制定價格策略提供數據支持。
????????SVM作為一種強大的監督學習算法,在處理高維數據、解決非線性分類問題以及防止過擬合等方面具有顯著優勢。通過選擇合適的核函數和調整相關參數,我們相信SVM算法能夠在手機價格分類預測問題上取得良好的效果。
2.項目簡介
2.1項目說明
????????本研究將利用SVM支持向量機算法構建手機價格分類預測模型,旨在為消費者提供便捷的購買決策支持,同時為企業市場分析和定價策略提供有價值的參考信息。
2.2數據說明
? ? ? ? 本數據集來源于Kaggle,數據集概述:手機特征的集合,包括電池電量、攝像頭規格、網絡支持、內存、屏幕尺寸和其他屬性。“price_range”列將手機按價格范圍進行分類,使該數據集適用于手機分類和價格預測任務。
2.3技術工具
Python版本:3.9
代碼編輯器:jupyter notebook
3.算法原理
????????支持向量機(Support Vector Machine,簡稱SVM)是一種常用的監督學習算法,主要用于分類和回歸分析。SVM的基本思想是在特征空間中尋找一個最優超平面,使得該超平面能夠最大程度地分隔兩個類別的樣本,并且保證分類的準確性。
SVM算法的原理可以簡要概括為以下幾個步驟:
- 初始化:選擇核函數和相關參數,如懲罰系數C、核函數參數等。核函數用于將原始特征空間映射到更高維的特征空間,以解決原始特征空間中的線性不可分問題。
- 構建最優超平面:在特征空間中,尋找一個最優超平面,使得兩個類別的樣本能夠最大程度地分隔開。這個最優超平面可以通過最大化間隔(即支持向量到超平面的距離)來實現。
- 求解支持向量:在訓練過程中,只有少數樣本點會決定最優超平面的位置,這些樣本點被稱為支持向量。支持向量是離分隔超平面最近的點,它們對于分類結果具有決定性的影響。
- 決策函數:根據最優超平面和支持向量,構建決策函數。對于新的未知樣本,可以將其特征向量代入決策函數中,根據函數值的正負來判斷其所屬的類別。
????????SVM算法具有許多優點,如分類效果好、魯棒性強、適用于高維數據等。同時,SVM也存在一些不足之處,如對參數敏感、計算復雜度高、難以處理大規模數據等。在實際應用中,需要根據具體的問題和數據特點來選擇合適的算法和參數。
4.項目實施步驟
4.1理解數據
導入第三方庫并加載數據
查看數據大小
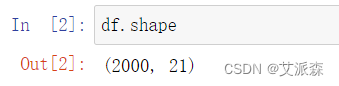
查看數據基本信息

查看描述性統計
4.2數據預處理
統計缺失值情況
結果發現數據不存在缺失值?
檢測數據是否存在重復值
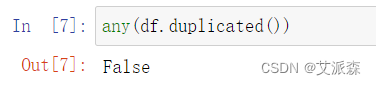
結果為False,說明不存在重復值
4.3探索性數據分析
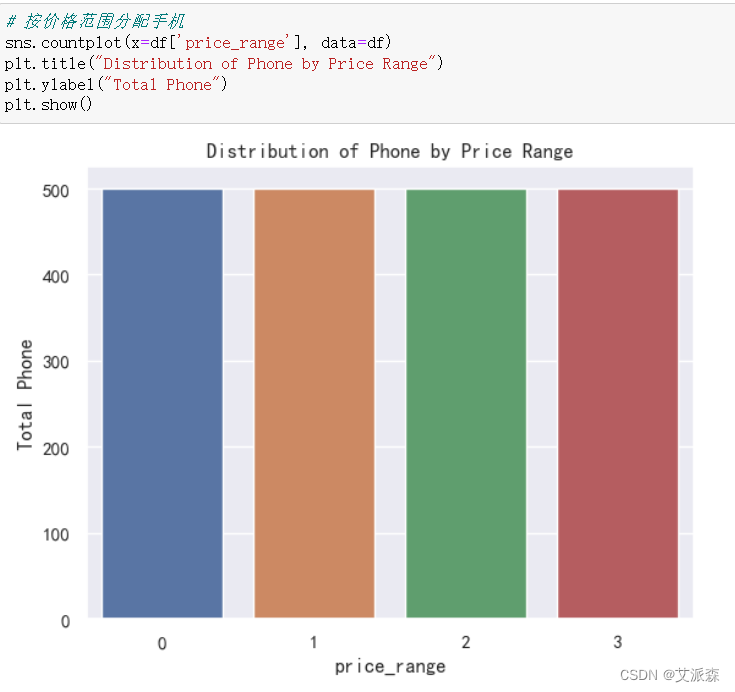
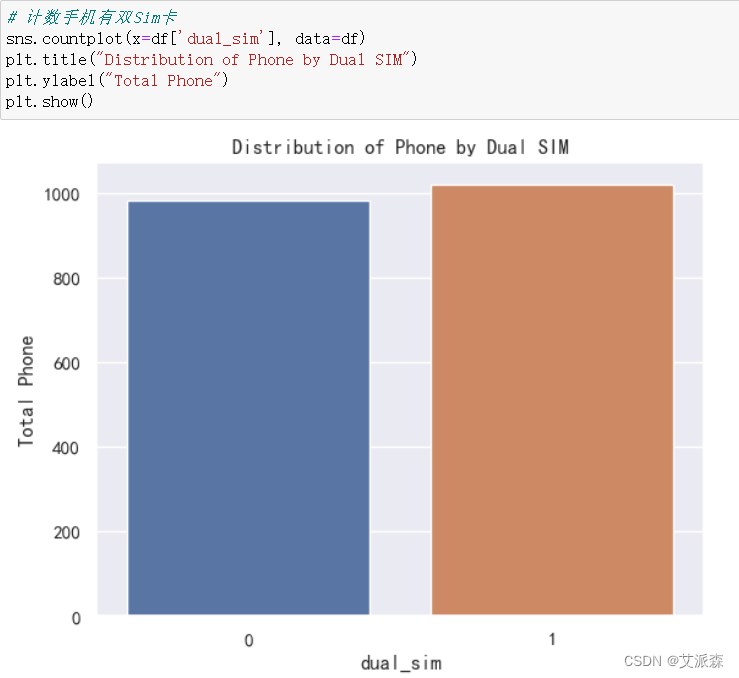
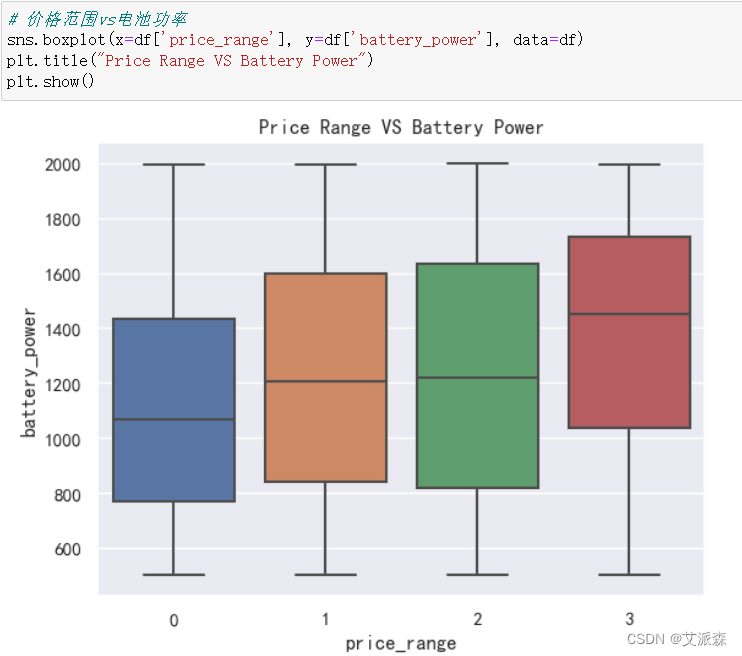
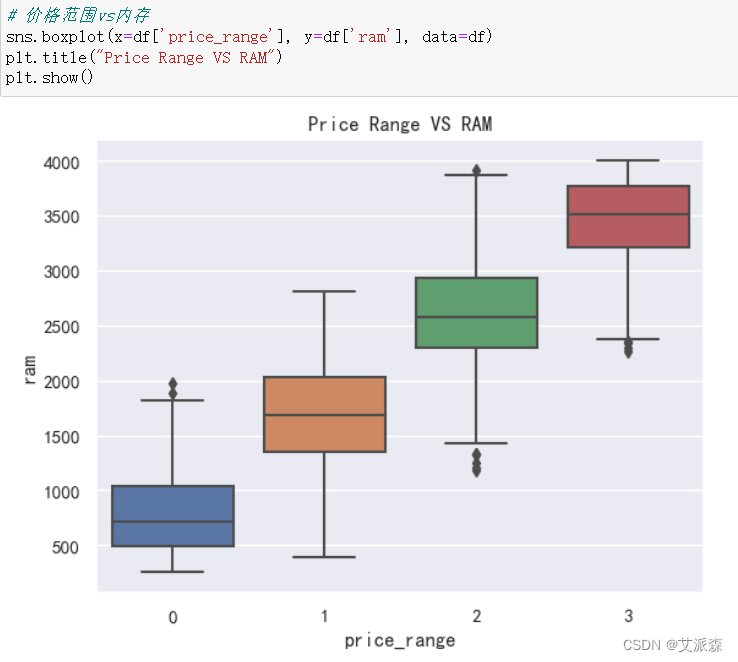
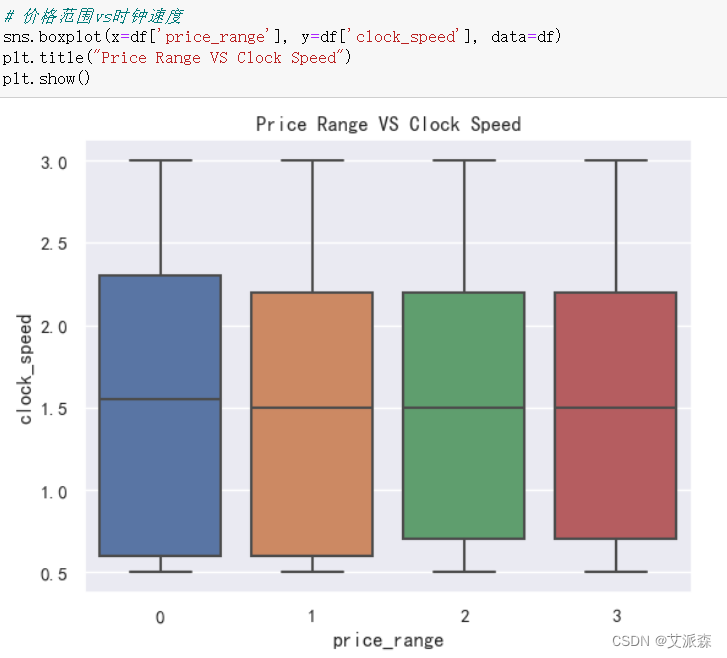
?
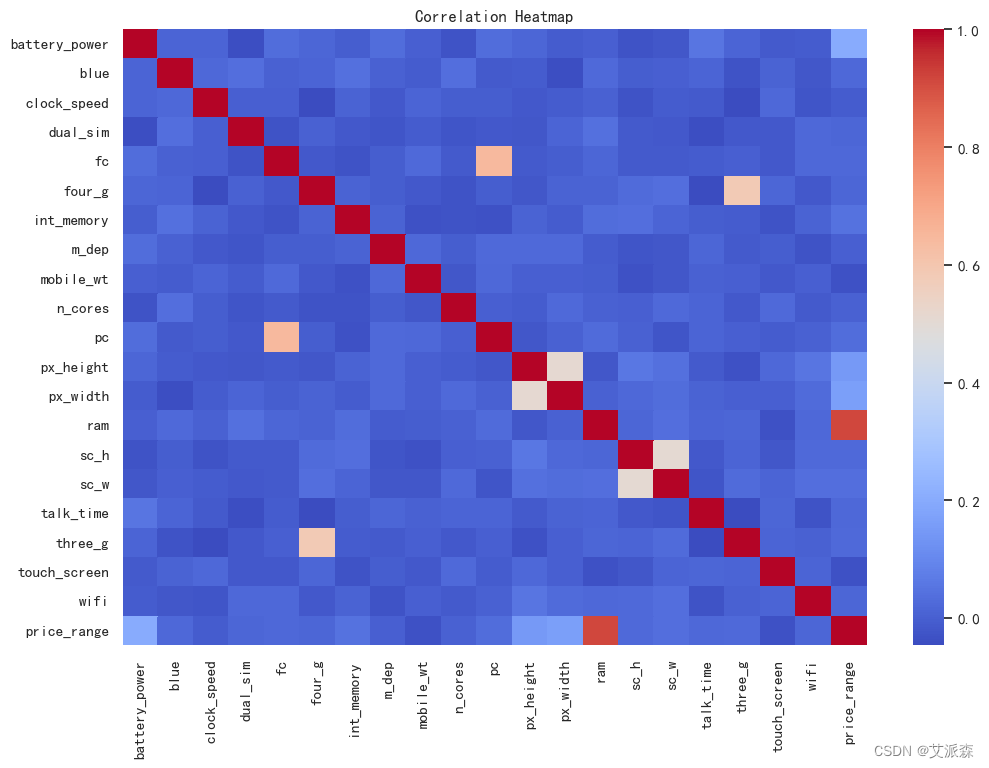
4.4特征工程
選擇特征變量和目標變量,拆分數據集為訓練集和測試集,其中測試集比例為0.3

4.5模型構建
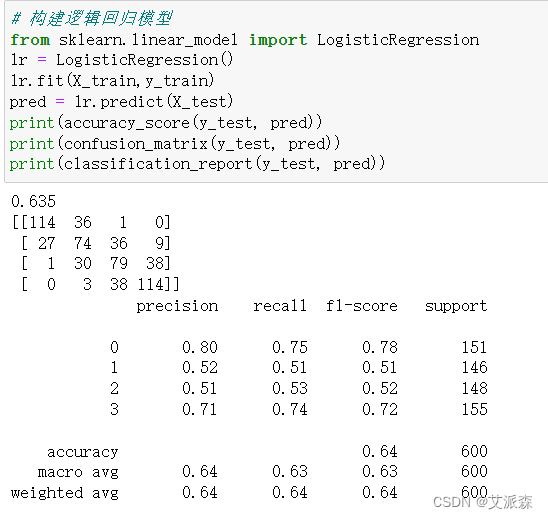
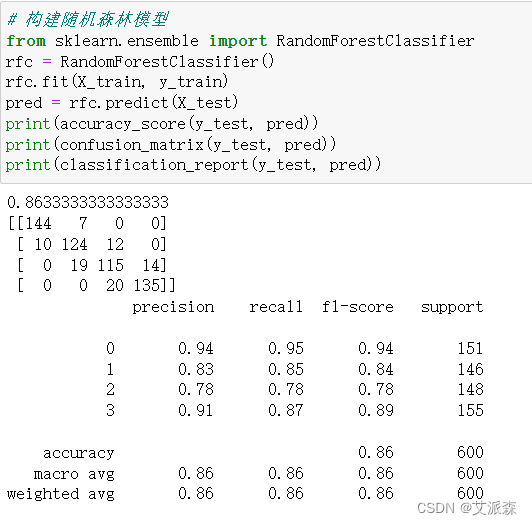
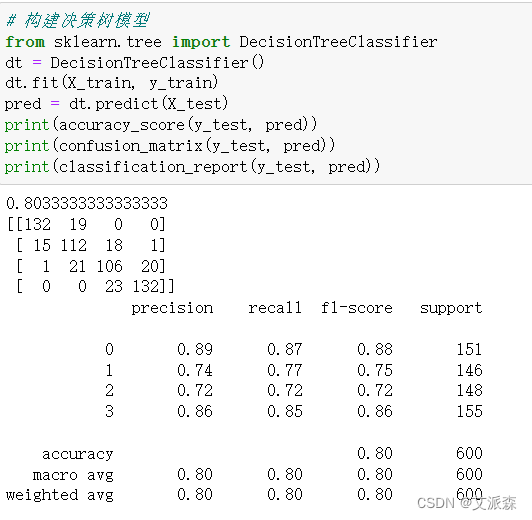
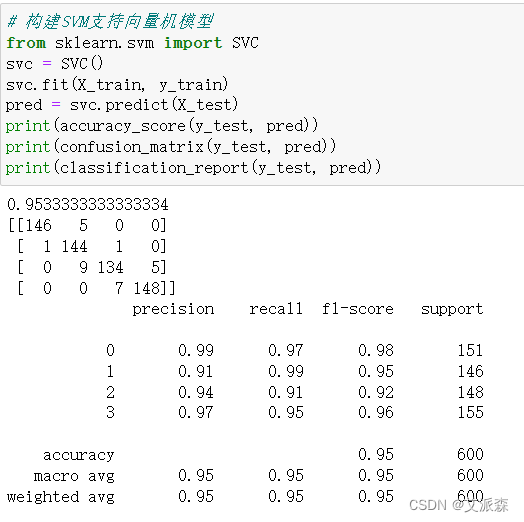
?對比三個模型,可以發現SVM支持向量機的模型準確率最高,達到0.95,模型效果最好,故我們選擇其作為最終模型。
4.6模型預測
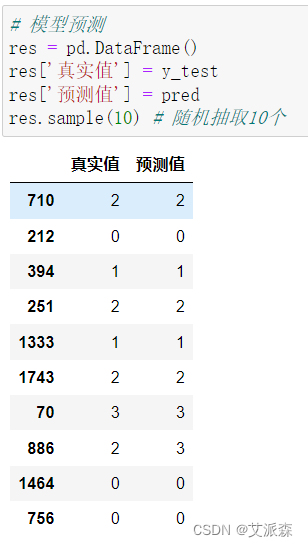
隨機抽取10中錯了1個,模型效果還不錯。
5.實驗總結
- 模型有效性:使用SVM算法構建的手機價格分類預測模型是有效的。通過訓練集的學習,模型能夠較為準確地對手機價格進行分類預測。
- 特征選擇的重要性:在模型構建過程中,特征選擇對于預測精度至關重要。選取與手機價格相關性強的特征(如品牌、配置、屏幕尺寸、電池容量等)能夠顯著提高模型的預測性能。
- 參數優化的影響:SVM算法中的參數(如懲罰系數C和核函數參數γ)對模型性能有顯著影響。通過實驗發現,通過交叉驗證等方法對參數進行優化,可以進一步提高模型的預測精度。
- 模型泛化能力:通過對比訓練集和測試集的預測結果,發現模型在測試集上的表現略遜于訓練集,但整體泛化能力良好。這表明模型對于未知數據的預測能力較強,具有一定的實用價值。
- 與其他模型的比較:將SVM模型與其他常見分類算法(如決策樹、隨機森林、神經網絡等)進行比較,發現SVM模型在本實驗中具有較高的預測精度和穩定性。這可能是因為SVM對于高維數據的處理能力較強,且對于非線性關系有較好的處理能力。
- 模型改進方向:雖然SVM模型在本實驗中表現良好,但仍有一定的改進空間。未來可以考慮引入更多的特征、優化特征提取方法、嘗試不同的核函數等方法來進一步提高模型的預測性能。
綜上所述,基于SVM算法構建的手機價格分類預測模型具有較高的預測精度和實用性,為手機價格預測提供了一種有效的方法。同時,實驗過程中也發現了模型改進的方向,為未來的研究提供了參考。
心得與體會:
通過這次Python項目實戰,我學到了許多新的知識,這是一個讓我把書本上的理論知識運用于實踐中的好機會。原先,學的時候感嘆學的資料太難懂,此刻想來,有些其實并不難,關鍵在于理解。
在這次實戰中還鍛煉了我其他方面的潛力,提高了我的綜合素質。首先,它鍛煉了我做項目的潛力,提高了獨立思考問題、自我動手操作的潛力,在工作的過程中,復習了以前學習過的知識,并掌握了一些應用知識的技巧等
在此次實戰中,我還學會了下面幾點工作學習心態:
1)繼續學習,不斷提升理論涵養。在信息時代,學習是不斷地汲取新信息,獲得事業進步的動力。作為一名青年學子更就應把學習作為持續工作用心性的重要途徑。走上工作崗位后,我會用心響應單位號召,結合工作實際,不斷學習理論、業務知識和社會知識,用先進的理論武裝頭腦,用精良的業務知識提升潛力,以廣博的社會知識拓展視野。
2)努力實踐,自覺進行主角轉化。只有將理論付諸于實踐才能實現理論自身的價值,也只有將理論付諸于實踐才能使理論得以檢驗。同樣,一個人的價值也是透過實踐活動來實現的,也只有透過實踐才能鍛煉人的品質,彰顯人的意志。
3)提高工作用心性和主動性。實習,是開端也是結束。展此刻自我面前的是一片任自我馳騁的沃土,也分明感受到了沉甸甸的職責。在今后的工作和生活中,我將繼續學習,深入實踐,不斷提升自我,努力創造業績,繼續創造更多的價值。
這次Python實戰不僅僅使我學到了知識,豐富了經驗。也幫忙我縮小了實踐和理論的差距。在未來的工作中我會把學到的理論知識和實踐經驗不斷的應用到實際工作中,為實現理想而努力。
源代碼
數據集概述:手機特征的集合,包括電池電量、攝像頭規格、網絡支持、內存、屏幕尺寸和其他屬性。“price_range”列將手機按價格范圍進行分類,使該數據集適用于手機分類和價格預測任務。
# 導入第三方庫
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
sns.set(font='SimHei')
warnings.filterwarnings('ignore')
# 讀取數據
df = pd.read_csv('train.csv')
df.head() # 查看數據前五行
df.shape
df.info()
df.describe()
df.isnull().sum()
any(df.duplicated())
# 按價格范圍分配手機
sns.countplot(x=df['price_range'], data=df)
plt.title("Distribution of Phone by Price Range")
plt.ylabel("Total Phone")
plt.show()
# 計數手機有雙Sim卡
sns.countplot(x=df['dual_sim'], data=df)
plt.title("Distribution of Phone by Dual SIM")
plt.ylabel("Total Phone")
plt.show()
# 價格范圍vs電池功率
sns.boxplot(x=df['price_range'], y=df['battery_power'], data=df)
plt.title("Price Range VS Battery Power")
plt.show()
# 價格范圍vs內存
sns.boxplot(x=df['price_range'], y=df['ram'], data=df)
plt.title("Price Range VS RAM")
plt.show()
# 價格范圍vs時鐘速度
sns.boxplot(x=df['price_range'], y=df['clock_speed'], data=df)
plt.title("Price Range VS Clock Speed")
plt.show()
# 相關系數熱力圖
plt.figure(figsize=(12,8))
sns.heatmap(df.corr(), cmap='coolwarm')
plt.title("Correlation Heatmap")
plt.show()
# 創建一個特征和目標變量
X = df.drop('price_range', axis=1)
y = df['price_range']
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
# 拆分數據集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 構建邏輯回歸模型
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train,y_train)
pred = lr.predict(X_test)
print(accuracy_score(y_test, pred))
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred))
# 構建隨機森林模型
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
pred = rfc.predict(X_test)
print(accuracy_score(y_test, pred))
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred))
# 構建決策樹模型
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier()
dt.fit(X_train, y_train)
pred = dt.predict(X_test)
print(accuracy_score(y_test, pred))
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred))
# 構建SVM支持向量機模型
from sklearn.svm import SVC
svc = SVC()
svc.fit(X_train, y_train)
pred = svc.predict(X_test)
print(accuracy_score(y_test, pred))
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred))
# 模型預測
res = pd.DataFrame()
res['真實值'] = y_test
res['預測值'] = pred
res.sample(10) # 隨機抽取10個







)



: Flutter的版本管理終極指南)







