近年來,不法分子利用“爬蟲”軟件收集公民隱私數據案件屢見不鮮。2023年8月23日,北京市高級人民法院召開北京法院侵犯公民個人信息犯罪案件審判情況新聞通報會,通報侵犯公民個人隱私信息案件審判情況,并發布典型案例。在這些典型案例中,不法分子多是通過社交軟件群、網站論壇等平臺買賣或交換個人信息,“爬蟲”軟件成為收集大量信息的常用軟件之一。
網絡數據爬蟲,又稱為網絡數據蜘蛛、互聯網機器人等。它通過爬取互聯網上網站的內容來工作。它是用計算機語言編寫的程序或腳本,用于自動從Internet上獲取任何信息或數據。爬蟲掃描并抓取每個所需頁面上的某些信息,自動實現對目標站點和目標信息的批量獲取,包括信息采集、數據存儲、信息提取。在利用爬蟲技術時應采用搜索引擎的爬蟲來對網頁上的信息進行搜集和存儲,應當嚴格遵守Robots協議規范爬取網頁數據(如URL)。禁止未經合法授權或超越授權去侵入它人的網站服務器,確保爬蟲程序不會突破或繞開網站服務器的防護措施。
爬蟲技術手段
爬蟲通用架構如下:
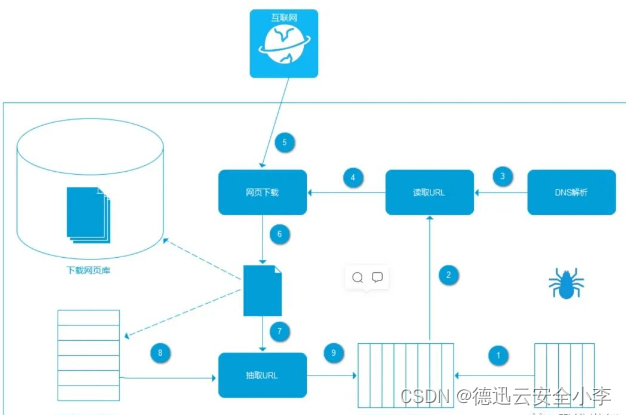
爬蟲從待抓取URL隊列依次讀取,并將URL通過DNS解析,把鏈接地址轉換為網站服務器對應的IP地址。然后將其和網頁相對路徑名稱交給網頁下載器,網頁下載器負責頁面的下載。對于下載到本地的網頁,一方面將其存儲到頁面庫中,等待建立索引等后續處理;另一方面將下載網頁的URL放入已抓取隊列中,這個隊列記錄了爬蟲系統已經下載過的網頁URL,以避免系統的重復抓取。對于剛下載的網頁,從中抽取出包含的所有鏈接信息,并在已下載的URL隊列中進行檢查,如果發現鏈接還沒有被抓取過,則放到待抓取URL隊列的末尾,在之后的抓取調度中會下載這個URL對應的網頁。如此這般,形成循環,直到待抓取URL隊列為空。
爬蟲的幾種分類:
通用爬蟲:
通用爬蟲又稱全網爬蟲,它將爬取對象從一些種子 URL擴充到整個Web上的網站,主要用途是為門戶站點搜索引擎和大型Web服務提供商采集數據。
聚焦爬蟲:
聚焦爬蟲,又稱主題網絡爬蟲,是指選擇性地爬行那些與預先定義好的主題相關的頁面的網絡爬蟲。
增量式爬蟲:
增量式網絡爬蟲是指在具有一定量規模的網絡頁面集合的基礎上,采用更新數據的方式選取已有集合中的過時網頁進行抓取,以保證所抓取到的數據與真實網絡數據足夠接近。
表層爬蟲:
爬取表層網頁的爬蟲叫做表層爬蟲。表層網頁是指傳統搜索引擎可以索引的頁面,以超鏈接可以到達的靜態網頁為主構成的Web頁面。
深層爬蟲:
爬取深層網頁的爬蟲就叫做深層爬蟲。深層網頁是那些大部分內容不能通過靜態鏈接獲取的、隱藏在搜索表單后的,只有用戶提交一些關鍵詞才能獲得的 Web 頁面。

數據防護措施方案:
不法分子利用惡意爬蟲不遵守網站的robots協議,對網站中某些深層次的、不愿意公開的數據肆意爬取,其中不乏個人隱私或者商業秘密等重要信息,并有可能給對方服務器性能造成極大損耗。未經過網站服務器的合法授權去抓取數據會干擾網站的正常運營,而非正規爬蟲自動持續且高頻次地對網站服務器發起請求,服務器負載飆升,同一時間大量的爬蟲請求會讓網站服務器過載或崩潰,尤其是中小網站可能會面臨網站打不開、網頁加載極其緩慢、甚至直接癱瘓的情況。下面我講介紹幾種防護方法:
1.Uswe-Agent?反爬蟲
User-Agent是請求頭的一部分,在用戶請求網站時會告訴網站服務器,網站服務器可以通過請求頭參數中的?User-Agent?來判斷請求方是否是瀏覽器、客戶端程序或者其他的終端,如果是通過爬蟲方式請求則為默認的請求頭信息,直接過濾拒絕訪問,如果是用戶瀏覽器,就會應答。
在網站服務器設置User-Agent,添加指定的User-Agent請求頭信息,User-Agent存放于Headers中,網站服務器就是通過查看Headers中的User-Agent字段中的值來判斷是誰在請求訪問網站。當用戶或者爬蟲程序請求訪問網站時網站服務器會自動的去檢測連接對象,如果檢測到請求頭中未包含指定的User-Agent的話,網站本身的反爬蟲程序就會識別出你是通過爬蟲程序在訪問網站,網站服務器會判斷是非法請求,從而拒絕訪問 。如果檢測對象的User-Agent為指定的請求頭信息則接受訪問。
2.黑名單策略
在網站服務器中配置黑名單策略,當請求方發起請求后網站服務器進行識別、只要編程語言出現在黑名單策略中,都視為爬蟲,對于此類請求可以不予處理或者返回相應的錯誤提示。

2.User-Agent訪問
網站服務器后臺對訪問進行統計,如果單個User-Agent訪問超過指定閾值,予以臨時封鎖或永久性封鎖。
3.單個IP訪問
網站服務器后臺對請求訪問的IP進行統計,如果單個IP訪問超過指定閾值,予以臨時封鎖或永久性封鎖。
結語?:
當前,互聯網數據作為新型生產要素,正深刻影響著國家經濟社會的發展。大量惡意爬蟲竊取網站核心數據,應當采取數據防護措施手段,保障數據得到有效保護和合法利用,并使數據持續處于安全狀態的能力以及保障網站服務器的正常運轉和降低服務器的壓力與運營成本。通過反爬蟲技術手段對網站數據進行防護,避免被那些不遵守網站robots協議的惡意爬蟲肆意高頻次的從網站爬取個人信息數據、企業非公開和國家重要等數據。??



)



: Flutter的版本管理終極指南)











)