目錄
- 引出
- Redis事務支持,AOF和RDB持久化
- 1、Redis的事務支持
- 2、Redis的持久化
- Redis沖沖沖——緩存三兄弟:緩存擊穿、穿透、雪崩
- 緩存擊穿
- 緩存穿透
- 緩存雪崩
- 總結
引出
Redis沖沖沖——事務支持,AOF和RDB持久化
Redis事務支持,AOF和RDB持久化
1、Redis的事務支持
事務:一段具有明確開始,結束標記的,并且執行順序是有序的執行過程!
比如:張三給李四轉錢 5000
ACID:原子性,一致性,隔離性,持久性
咱們Redis同樣支持事務!配合關系型數據庫進行事務支持!
開啟事務:multi
執行事務:exec
撤銷事務:discard
監控某Key:watch 采用原理:樂觀鎖
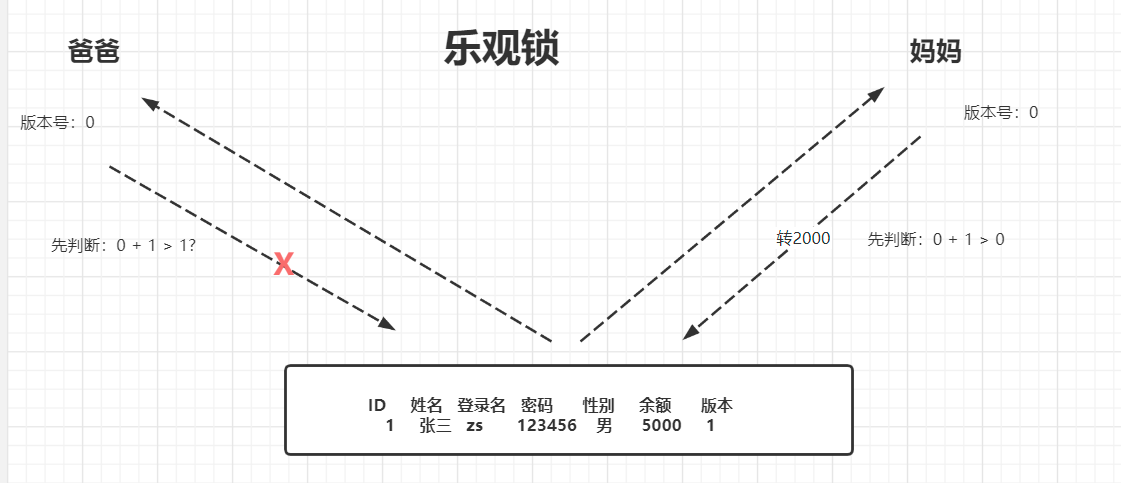
樂觀鎖:依靠版本控制來進行實現,底層原理:CAS Comparable And Swap 比較并交換 (用戶在操作庫的時候,樂觀的認為:一定沒有人和我同時操作同一條數!)
悲觀鎖:(用戶在操作庫的時候,悲觀的認為:一定有人和同時操作同一條數據),依舊數據庫底層上鎖:在SQL語句后,添加:select * from 表 for update;
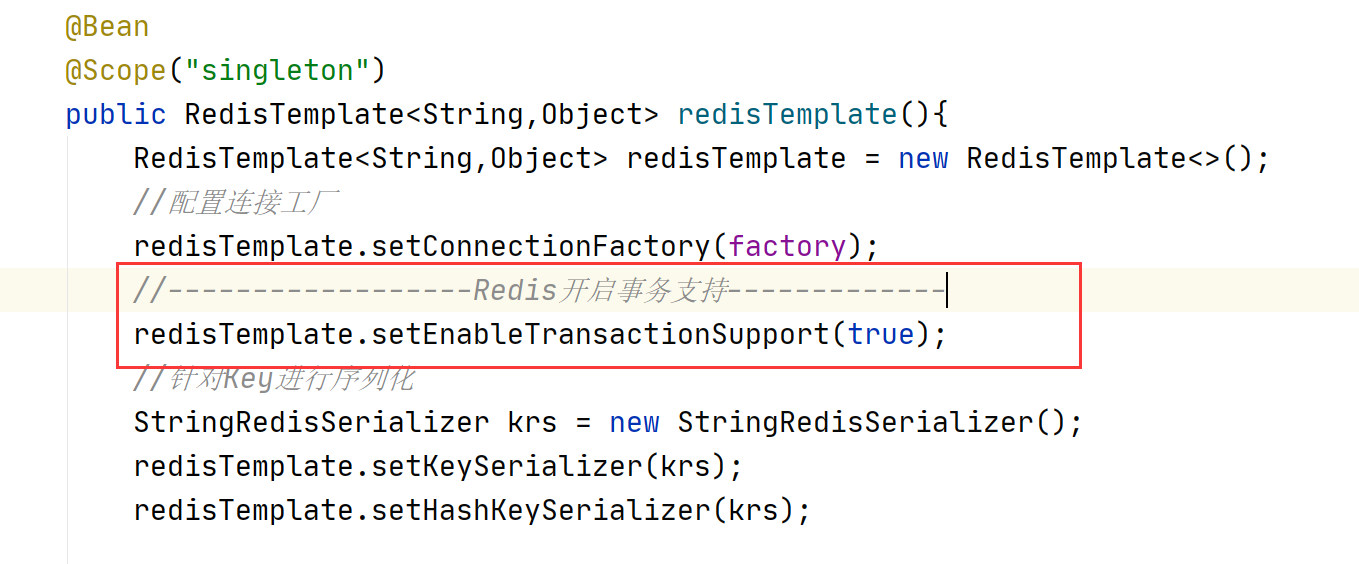
在需要控制事務的方法上,添加注解@Transactional
2、Redis的持久化
Redis的數據,更多的依賴于內存,問題:可能存在數據丟失的問題
解決:Redis提供持久化機制(RDB,AOP)
所以Redis為了解決內存不靠譜的問題, 提供2種:硬盤持久化方案
RDB AOF
(1)、RDB
Redis Database Backup file
RDB (Redis Database)是Redis默認的一種持久化方案!叫:快照模式
原理:dump.rdb文件來進行存儲Redis當前的數據狀態!
下載Redis的配置文件:
curl -o redis.conf https://raw.githubusercontent.com/redis/redis/6.0/redis.conf
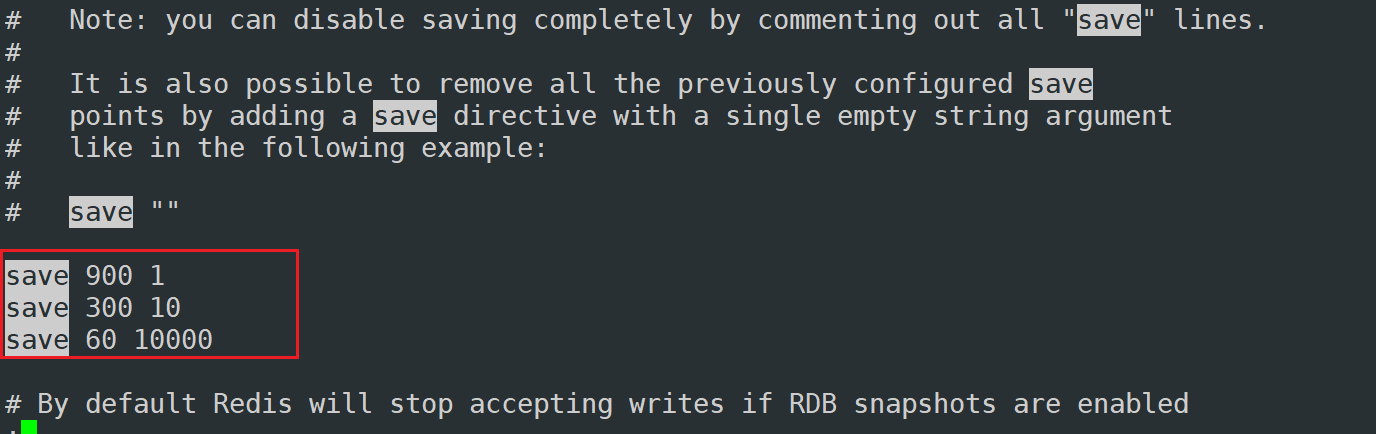
60S—-1分鐘范圍內,如果redis監控到有10000條數據的變化,開始持久化
300S—5分鐘范圍內,如果redis監控到有10條數據的變化,開始持久化
900S —15分鐘范圍內,如果redis監控到有1條數據的變化,開始持久化
所以RDB在一定程度上,可能存在數據丟失的問題
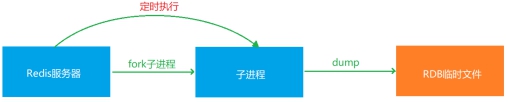
Redis服務器,會定時開啟子進程,在固定時間掃描內存的數據變化 ,當條件滿足,則將變化先通過臨時文件中去,最后
再將臨時文件的內容,寫入到dump.rdb文件中,即可完成持久化
如果需要修改:

取消本機綁定

取消本機客戶端保護模式

為了保護redis,請大家設置連接密碼:

提醒下:在vim中使用“/關鍵字”快速查找關鍵字;并通過N或n 快速定位上一個/下一個
修改redis.conf的權限
chmod 777 redis.conf
重新創建一個Redis的Docker容器:
docker run --name myredis -p 6379:6379 -v /root/redis/redis.conf:/usr/local/etc/redis/redis.conf -v /root/redis/data:/data --privileged=true -d redis:latest redis-server /usr/local/etc/redis/redis.conf
(2)、AOF
AOF Append Only File 采用日志追加的方式,來記錄Redis的相關操作命令!
MySQL 有一種二進制日志文件,記錄:用戶對CUD的所有SQL語句!
AOF 記錄是用戶對Redis所有的命令!不是默認開啟的,需要 運維 手動通過配置文件進行開啟!
產生一個文件:appendonly.aof
追加方法:everysec (每秒追加一次日志), always(記錄每次操作),no (不記錄)
修改配置文件,開啟AOF:

配置追加方式:


AOF重寫的原理:
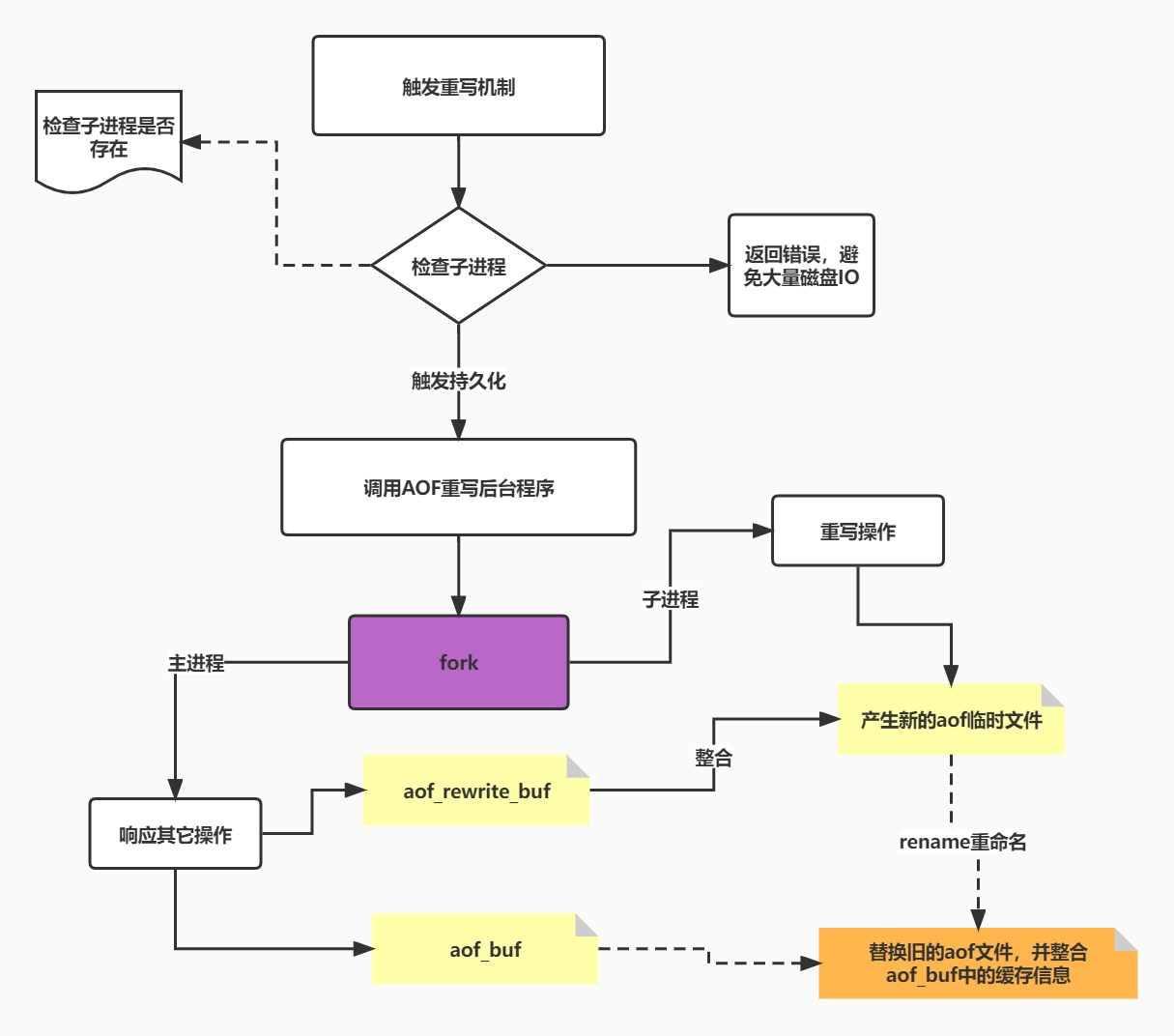
Redis 會自動監控AOF文件的變化,當AOF文件達到64M,或達到上次重寫文件的2倍,就會觸發AOF文件重寫機制!
通過重寫AOF文件來實現持久化,Redis將進程分叉為2個進程,一個主進程,一個子進程;主進程繼續響應其他操作,子進程開啟重寫機制!
在重寫時,會產生2個文件,一個AOF的臨時文件,一個AOF的緩存文件,臨時文件用于重寫,緩存文件用于主進程記錄最新的命令操作;
子進程通過重寫整合命令至新的臨時文件,整合完成之后重命名為AOF文件,并整合緩存文件中的其他命令,完成重寫
AOF & RDB 如何選擇?

Redis沖沖沖——緩存三兄弟:緩存擊穿、穿透、雪崩
緩存擊穿
緩存擊穿:redis中沒有,但是數據庫有
順序:先查緩存,判斷緩存是否存在;如果緩存存在,直接返回數據;如果緩存不存在,則查詢數據庫,將數據庫的數據存入到緩存
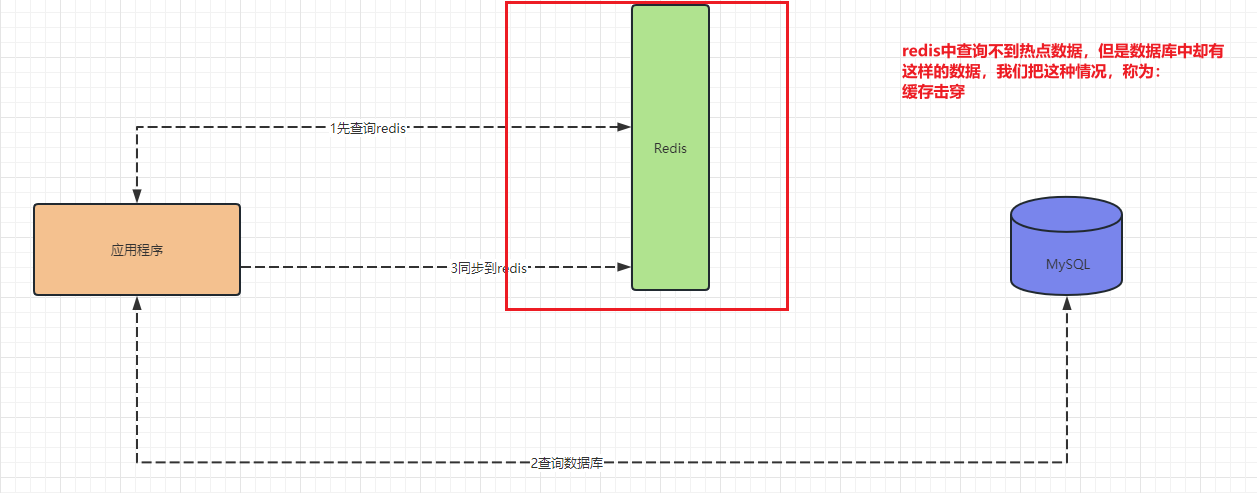
解決方案:將熱點數據設置過期時間長一點;針對數據庫的熱點訪問方法上分布式鎖;
緩存穿透
緩存穿透:redis中沒有,數據庫也沒有
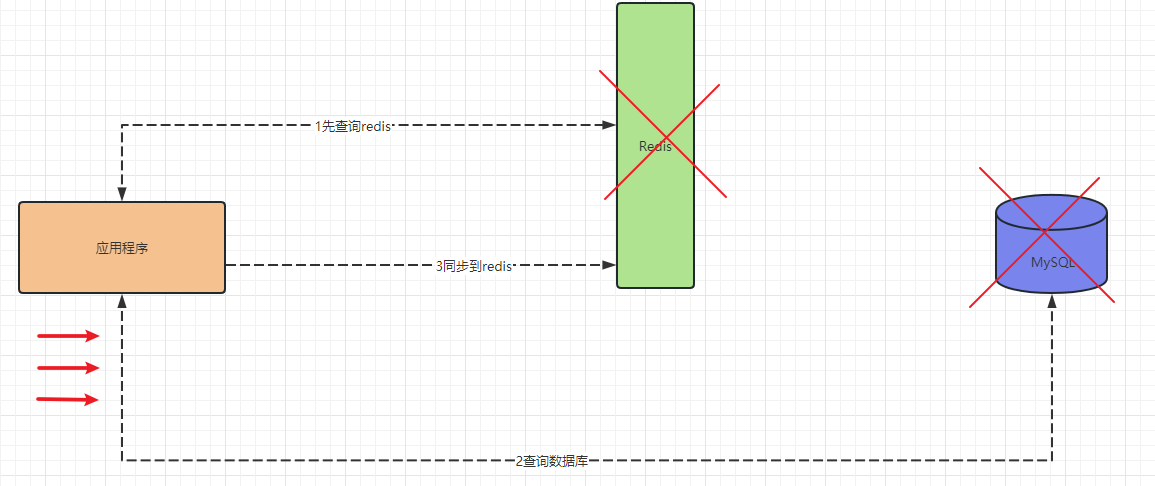
解決方案:
(1)將不存在的key,在redis設置值為null;
(2)使用布隆過濾器;
原理:https://zhuanlan.zhihu.com/p/616911933
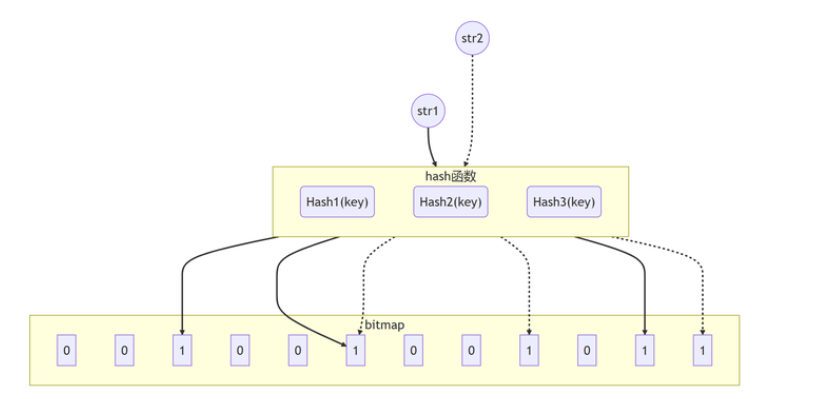
布隆過濾器:
如果確認key不存在于redis中,那么就一定不存在;
它說key存在,就有可能存在,也可能不存在! (誤差)
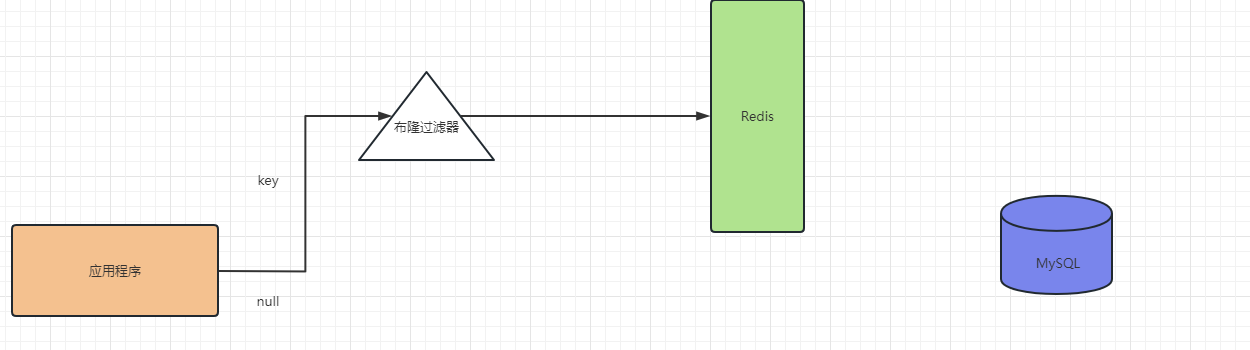
布隆過濾器
1、根據配置類中的 key的數量 ,誤差率,計算位圖數組【二維數組】
2、通過布隆過濾器存放key的時候,會計算出需要多少個hash函數,由hash函數算出多少個位圖位置需要設定為1
3、查詢時,根據對應的hash函數,判斷對應的位置值是否都為1;如果有位置為0,則表示key一定不存在于該redis服務器中;如果全部位置都為1,則表示key可能存在于redis服務器中;
緩存雪崩
緩存雪崩:
Redis的緩存雪崩是指當Redis中大量緩存數據同時失效或者被清空時,大量的請求會直接打到數據庫上,導致數據庫瞬時壓力過大,甚至宕機的情況。
造成緩存雪崩的原因主要有兩個:
1.相同的過期時間:當Redis中大量的緩存數據設置相同的過期時間時,這些數據很可能會在同一時間點同時失效,導致大量請求直接打到數據庫上。
2.緩存集中失效:當服務器重啟、網絡故障等因素導致Redis服務不可用,且緩存數據沒有自動進行容錯處理,當服務恢復時大量的數據同時被重新加載到緩存中,也會導致大量請求直接打到數據庫上。
預防緩存雪崩的方法主要有以下幾種:
1.設置不同的過期時間:可以將緩存數據的過期時間分散開,避免大量緩存數據在同一時間點失效。
2.使用加鎖:可以將所有請求都先進行加鎖操作,當某個請求去查詢數據庫時,如果還沒有加載到緩存中,則只讓單個線程去執行加載操作,其他線程等待該線程完成后再次進行判斷,避免瞬間都去訪問數據庫從而引起雪崩。
3.提前加載預熱:在系統低峰期,可以提前將部分熱點數據加載到緩存中,這樣可以避免在高峰期緩存數據失效時全部打到數據庫上。
4.使用多級緩存:可以在Redis緩存之上再使用一層緩存,例如本地緩存等,當Redis緩存失效時,還能夠從本地緩存中獲取數據,避免直接打到數據庫上。
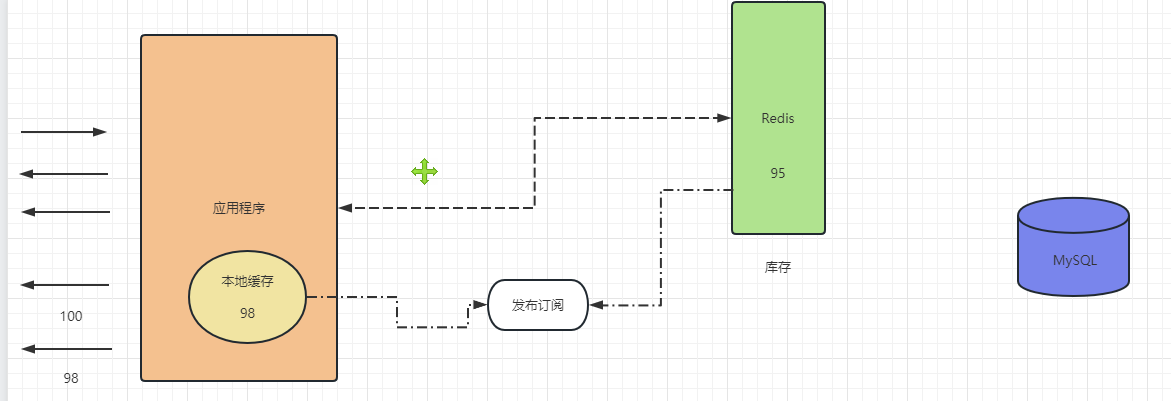
本地緩存:ehcache oscache spring自帶緩存 持久層框架的緩存
總結
Redis沖沖沖——事務支持,AOF和RDB持久化



(題目+思路+代碼))
-事務隔離級別與InnoDB的應用)





)



)

中文版)


