1.介紹
Explicit Visual Prompting for Low-Level Structure Segmentations
低級結構分割的顯式視覺提示
2023年發表在IEEE CVPR
Paper Code
2.摘要
檢測圖像中低級結構(低層特征)一般包括分割操縱部分、識別失焦像素、分離陰影區域和檢測隱藏對象。雖然每個此類主題通常都是通過特定領域的解決方案來解決的,但統一的方法在所有這些主題中都表現良好。從 NLP 中廣泛使用的預訓練和提示調整協議中汲取靈感,本文提出了一種新的視覺提示模型,稱為顯式視覺提示(EVP)。與之前的視覺提示(通常是數據集級隱式嵌入)不同,本文強調的是強制調整參數,重點關注每個單獨圖像的顯式視覺內容,即來自凍結補丁嵌入的特征和輸入的高頻成分。在相同數量的可調參數下(每個任務有 5.7% 的額外可訓練參數),所提出的 EVP 顯著優于其他參數高效的調整協議。
就是不同于直接把輸入給到網絡模型讓它自己學習,學習內容不可知的隱式視覺提示,本文提出了顯示視覺提示,調整參數重點關注頻域的高頻輸入部分(即低層特征)。
Keywords:顯式視覺提示,頻域高頻部分
3. Introduction
圖像編輯和操作算法的進步使得創建逼真但虛假的圖片變得容易。由于其與監視和犯罪相關的潛在負面影響,檢測此類被操縱區域成為一個重要問題。眾所周知,低級結構(低級特征)有利于篡改區域檢測,比如調整大小和復制粘貼將破壞原始圖像與被纂改圖像之間的 JPEG 壓縮級別,被纂改圖像的噪聲水平并且背景也不同。要分割模糊像素、陰影區域和隱藏物體,低級線索也很重要。雖然所有這些任務都屬于低級結構分割,但它們是通常由具有精心設計的網絡架構的特定領域解決方案來解決。此外,缺乏大規模數據集通常被認為是限制性能的主要因素。
本文基本思想是使用最少的額外可訓練參數,有效地將凍結的大型基礎模型適應許多下游任務。由于基礎模型已經在大規模數據集上進行了訓練,因此提示通常會導致下游任務上更好的模型泛化,特別是在注釋數據有限的情況下。提示還顯著節省了模型的存儲,因為它只需要保存共享的基本模型和任務感知提示。
視覺提示調整。即使在GPT3中手動選擇提示的少量或零次設置中,也可以對下游遷移學習任務進行強大的泛化。最近,提示已經適應視覺任務。有任務提出了記憶令牌,這是一組可學習的嵌入向量的每個Transformer層。VPT 提出了類似的想法,并通過跨多個領域和骨干架構的多種識別任務的廣泛實驗來研究視覺提示的通用性和可行性。不像VPT重點是識別任務,本文的工作旨在探索低層次結構分割的最佳視覺內容。
偽造檢測的目標是檢測手動操作的像素,例如被刪除、替換或編輯的像素。早期的方法通過局部噪聲水平的不一致來檢測區域拼接,基于不同來源的圖像可能包含由傳感器或后處理步驟引入的不同噪聲特性的事實。其他線索也很有幫助,例如SIFT,JPEG壓縮偽影和重新采樣偽影。最近,有人通過在標記的訓練數據上訓練一個完全卷積的網絡來學習檢測剪接。還有結合生成對抗網絡(GAN)來檢測復制移動攻擊。Huh等人提出將攝影元數據作為一種自由而豐富的監督信號,用于學習自我一致性,并應用訓練后的模型來檢測拼接。最近,TransForensic利用視覺Transformer來解決這個問題。高頻元件在這一領域仍然是有用的優先級。RGB-N設計了一個額外的噪聲流。ObjectFormer提取高頻特征作為視覺內容的補充信號。但與ObjectFormer不同的是,本文的主要重點是利用高頻組件作為一種激勵設計,以有效地適應不同的低級分割任務。
4.網絡結構詳解
顯式視覺分割(EVP),基于在ImageNet 上預訓練的視覺變換器(SegFormer),用以低級結構分割。EVP凍結backbone的參數,只包含少量的可調參數,從凍結補丁嵌入和高頻分量的特征中學習特定于任務的知識。模型總體結構圖如下:

如右邊所示,圖像輸入,經過補丁嵌入層獲取到的特征入Embedding Tune層,獲取補丁分量,圖像經過HFC Extraction 提取層提取到高頻分量,首先將兩者相加入適配器Adaptor得到自適應后的輸出;將補丁分量與自適應后的結果相加,入Transformer層,輸出結果再與自適應的分量相加入下一Transformer層,循環幾次;最后的輸出進入第二階段。
需要注意的是,backbone比如SegFormer是預訓練好的,它的參數無需再調整,只需調整Embedding Tune,HFC Extraction ,和Adaptor的參數。
SegFormer:
SegFormer是一個基于transformer的分層結構,具有更簡單的語義分割解碼器。與傳統的CNN主干類似,SegFormer通過幾個階段捕獲多個陳舊特征。因此,每個階段都是通過特征嵌入層1和視覺Transformer塊構建的。至于解碼器,它利用來自編碼器和MLP層的多尺度特征來解碼特定的類。注意,所提出的提示策略不限于SegFormer,并且可以容易地適應于其他網絡結構。
高頻分量:
對于維數為H ×W的圖像I,可以將其分解為低頻分量Il(LFC)和高頻分量Ih(HFC),即 I = { I l , I h } I = {\{Il,Ih\}} I={Il,Ih}。將fft和ifft分別表示為快速傅立葉變換及其逆變換,使用z來表示I的頻率分量。因此有 z = f f t ( I ) z = fft(I) z=fft(I)和 I = i f f t ( z ) I = ifft(z) I=ifft(z)。將低頻系數移到中心(H/2,W/2)。為了獲得HFC,生成二進制掩碼 M h ∈ { 0 , 1 } H × W M_h ∈ {\{0,1\}}^{H×W} Mh?∈{0,1}H×W,并根據掩碼比τ將其應用于z:
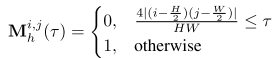
τ表示掩蔽區域的表面比。HFC可以計算:
類似地,可以適當地定義二進制掩碼 M l ∈ { 0 , 1 } H × W M_l ∈ {\{0,1\}}^{H×W} Ml?∈{0,1}H×W以計算LFC:
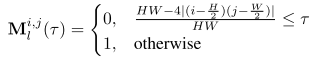
LFC可以表示為:
請注意,對于RGB圖像,獨立地在每個像素通道上計算上述過程。
顯式視覺提示:
顯式視覺識別(EVP):從補丁嵌入和高頻分量中學習明確的提示。學習前者來將分布從預訓練數據集轉移到目標數據集。而學習后者的主要動機是通過數據增強來學習預訓練模型對這些特征保持不變。與學習隱式提示的VPT不同,它由三個基本模塊組成:補丁嵌入調諧,高頻分量調諧以及適配器。
從補丁嵌入中學習明確的提示:這指的是利用補丁嵌入(通常是從預訓練模型中獲得的)來將數據分布從預訓練數據集轉移到目標數據集。補丁嵌入是將圖像的小塊或局部區域映射到低維向量空間的過程,而這些向量可以被視為對圖像特征的編碼。通過學習從預訓練模型中得到的這些特征嵌入,可以幫助將模型在預訓練數據集上學到的知識轉移到目標數據集上,從而提高模型在目標任務上的性能。
學習高頻分量的主要動機是通過數據增強來學習預訓練模型對這些特征保持不變:
這指的是利用數據增強技術來學習模型對圖像的高頻分量(即圖像中變化較快的部分)的不變性。數據增強是一種通過對訓練數據進行一系列隨機變換來增加數據樣本數量和多樣性的技術。通過在訓練過程中對高頻分量進行數據增強,可以幫助模型學習到對這些變化保持不變的特征表示,從而提高模型的魯棒性和泛化能力。高頻分量的不變性指的是對圖像中高頻部分的特征保持不變的性質。在圖像處理中,高頻分量通常指的是圖像中變化快速的部分,如邊緣、紋理等。這些特征對于圖像的識別和理解非常重要,因為它們包含了圖像中的細節信息。
為什么要保持高頻分量的不變性呢?
魯棒性: 高頻分量往往包含了圖像中的重要細節和結構信息。如果模型能夠在不同的輸入圖像中保持對這些細節的感知不變,那么它在面對各種變化,如旋轉、縮放、光照變化等時會更加穩健。
泛化能力: 如果模型在訓練過程中學習到了對高頻特征的不變性,那么它在處理未見過的數據時也會表現更好。這是因為模型已經學習到了對圖像中普遍存在的模式和結構的抽象表示,而不僅僅是對訓練數據的記憶。
抑制噪聲: 高頻分量往往受到噪聲的影響,保持對高頻特征的不變性可以幫助模型抑制噪聲的影響,從而提高對干凈數據的處理能力。
補丁嵌入調整。本模塊旨在調整預訓練的補丁嵌入。在預訓練的SegFormer中,補丁 I p I^p Ip被投影到 C s e g ? d i m e n s i o n C_{seg}-dimension Cseg??dimension特征。凍結這個投影,并添加一個可調線性層 L p e L_{pe} Lpe?,以將原始嵌入投影到c維特征 F p e ∈ R c F_{pe} ∈ R^c Fpe?∈Rc中:
 比例因子r控制可調參數。
比例因子r控制可調參數。
高頻分量調諧。對于高頻分量 I h f c I_{hfc} Ihfc?,學習了類似于SegFormer的重疊補丁嵌入。形式上, I h f c I_{hfc} Ihfc?被分成與SegFormer具有相同補丁大小的小補丁。表示補丁 I h f c P ∈ R C I^P_{hfc} ∈ R^C IhfcP?∈RC,C = h×w×3,學習一個線性層 L h f c L_{hfc} Lhfc?將補丁投影到c維特征 F h f c ∈ R c F_{hfc} ∈ R^c Fhfc?∈Rc。
適配器。Adaptor的目標是通過考慮來自圖像嵌入和高頻分量的特征,在所有層中高效地執行自適應。對于第i個適配器,將 F p e F_{pe} Fpe?和 F h f c F_{hfc} Fhfc?作為輸入并獲得提示 P i P^i Pi:
P i = M L P u p ( G E L U ( M L P t u n e i ( F p e + F h f c ) ) ) P^i = MLP_{up}({GELU({MLP^i_{tune}}(F_{pe}+F_{hfc}) ))} Pi=MLPup?(GELU(MLPtunei?(Fpe?+Fhfc?)))
其中GELU是GELU激活。 M L P t u n e i MLP^i_{tune} MLPtunei?是一個線性層,用于在每個適配器中產生不同的提示。 M L P u p MLP_{up} MLPup?是所有適配器共享的上投影層,用于匹配Transformer特征的尺寸。Pi是附加到每個Transformer層的輸出提示。
5.實驗與結果
隱藏物體檢測的結果如下:





:模擬算法真題 ★★★★☆《越野比賽》)
)









錯誤的集合)
)
)


