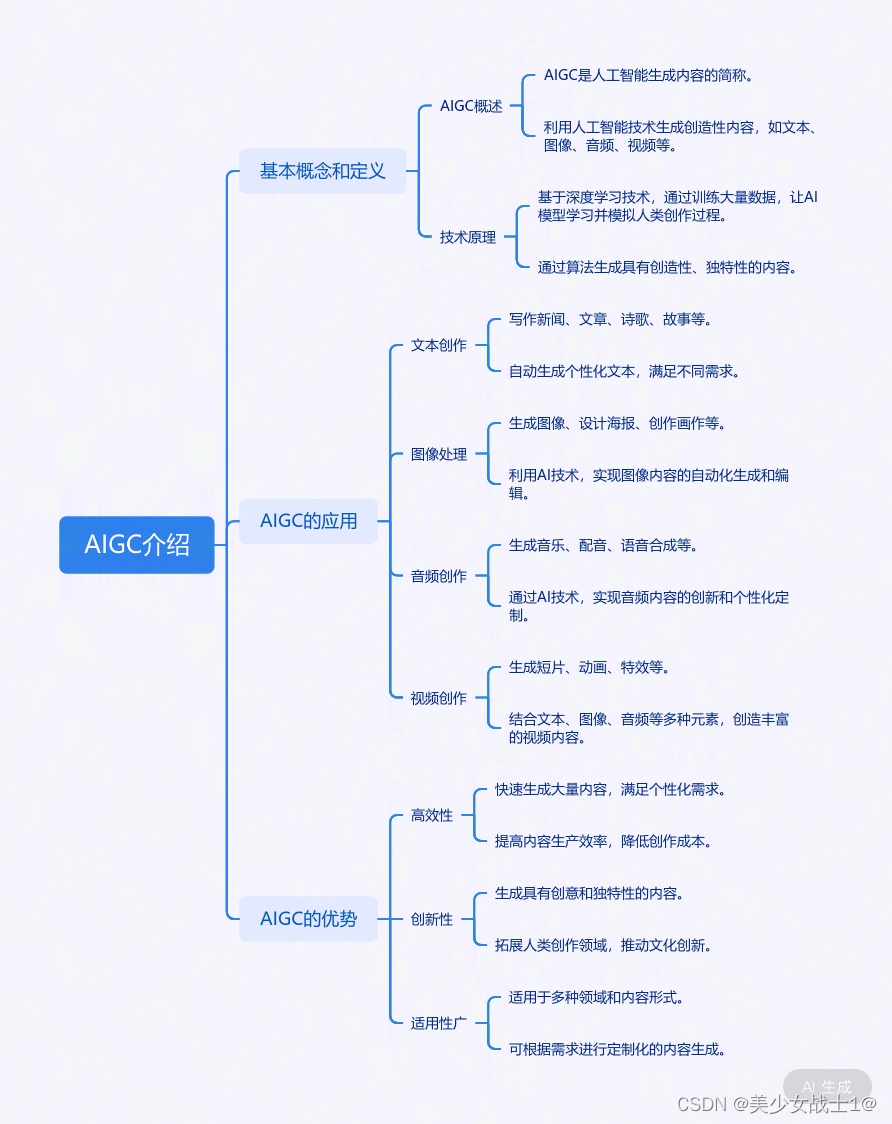
AIGC
- 概述
- 示例展示
- 我們日常用到的一些工具/應用
- 核心技術介紹
- 核心技術的算法解析
- 案例及部分代碼實現
- 1. 藝術作品
- 2. 設計項目
- 3. 影視特效
- 4. 廣告創意
- 總結
一張圖先了解下:
概述
"人工智能生成創造(Artificial Intelligence Generated Content,AIGC)"是指利用人工智能技術生成各種形式的創作內容,包括圖像、音頻、視頻等。AIGC 是人工智能在創意領域的應用,通過機器學習、深度學習等技術,讓計算機具備創作和生成內容的能力。
在 AIGC 領域,目前最為廣泛應用的技術包括生成對抗網絡(GAN)、變分自動編碼器(VAE)、神經風格遷移等。這些技術能夠模仿藝術家的風格、學習輸入數據的特征,從而生成類似但又獨特的創作內容。
舉例來說,通過使用生成對抗網絡(GAN),可以讓機器學習并生成逼真的圖像、視頻或音頻。GAN 的原理是由兩個神經網絡組成,一個生成器用于生成樣本,一個判別器用于評估生成的樣本與真實樣本的區別,二者不斷博弈提高生成效果。
另一個例子是神經風格遷移技術,它可以將一幅圖像的風格轉移到另一幅圖像上,生成具有原始圖像風格的新圖像。這種技術被廣泛應用于藝術創作、圖像處理等領域。
示例展示
1. 圖像生成:
- 示例:使用StyleGAN算法生成的名人肖像畫。
- 描述:展示一幅由StyleGAN生成的逼真的名人肖像畫,如奧黛麗·赫本或萊昂納多·迪卡普里奧。這些圖像幾乎難以與真實照片區分開來,展示了AIGC在圖像生成領域的驚人能力。
- 技術:StyleGAN是一種基于深度學習的生成對抗網絡(GAN),通過訓練大量的圖像數據,能夠生成高質量、多樣化的圖像。
2. 音頻生成:
- 示例:使用Transformer模型生成的語音。
- 描述:播放一段由Transformer模型生成的語音,內容可以是一段新聞報道或詩歌朗誦。這段語音聽起來自然流暢,幾乎與真實的人類語音無異。
- 技術:Transformer模型是一種基于自注意力機制的深度學習模型,廣泛應用于自然語言處理和語音合成等領域。通過訓練大量的語音數據,它能夠學會生成逼真的語音。
3. 視頻生成:
- 示例:使用MotionGAN生成的人物動作視頻。
- 描述:展示一段由MotionGAN生成的人物動作視頻,視頻中的人物動作流暢自然,與真實視頻難以區分。這展示了AIGC在視頻生成和編輯方面的巨大潛力。
- 技術:MotionGAN是一種結合了生成對抗網絡和運動捕捉技術的深度學習模型。它能夠學習人物的動作模式,并生成逼真的動作視頻。
我們日常用到的一些工具/應用
以下是上述工具/應用的主要作用和擅長領域的簡要概述:
-
ChatGPT:
- 主要作用:ChatGPT 是一個基于人工智能技術的語言模型,具備對話功能、語言生成功能、文本分類功能、文本摘要功能、機器翻譯功能以及語音合成功能。
- 擅長領域:ChatGPT 在自然語言處理方面表現出色,能夠進行流暢和自然的對話,并為用戶生成各種文本內容。
-
Midjourney:
- 主要作用:Midjourney 是一款旅行和出行社交應用,提供路線優化、線路推薦、旅行信息、路程追蹤以及社交模式等功能。
- 擅長領域:該應用專注于旅行領域,幫助用戶更好地規劃、享受和分享旅行體驗。
-
Adobe Firefly:
- 主要作用:Adobe Firefly 是一款基于人工智能的圖像和視頻編輯工具,通過語音輸入命令快速完成編輯任務。
- 擅長領域:Firefly 在圖像和視頻編輯方面功能強大,如色彩校正、調整圖像大小、添加文本等,以及視頻編輯功能如調整音頻、添加特效等。
-
文心一言:
- 主要作用:文心一言是一個基于人工智能技術的語言模型,具備表達情感、啟示思維和傳遞文化等功能。
- 擅長領域:文心一言在情感表達、思維啟示和文化傳播方面表現突出,能夠提供深入且富有情感的內容。
-
通義千問:
- 主要作用:通義千問是阿里云推出的超大規模語言模型,具備多輪對話、文案創作、邏輯推理、多模態理解、多語言支持等功能。
- 擅長領域:通義千問適用于多種場景,如在線客服、智能助手、社交聊天、學習輔助等。
-
豆包:
- 主要作用:豆包APP是一款具備自然語言處理和智能推薦功能的AI應用,旨在理解用戶需求并提供實用信息。
- 擅長領域:豆包APP擅長多語種、多功能的AIGC服務,如問答、智能創作和聊天,并支持語音播放。
-
Stable Diffusion:
- 主要作用:Stable Diffusion 是一種用于圖像生成的模型,能夠生成高質量的圖像。
- 擅長領域:該模型擅長圖像生成,尤其在圖像修復、圖像合成、圖像增強和圖像生成等任務中表現出色。
請注意,這些工具和模型的具體功能和擅長領域可能會隨著技術的不斷發展和更新而發生變化。因此,為了獲取最準確和最新的信息,建議您直接查閱官方文檔或聯系相關供應商。
核心技術介紹
AIGC的核心技術介紹
1. 生成對抗網絡(GAN)
原理:GAN由兩部分組成——生成器(Generator)和判別器(Discriminator)。生成器的任務是生成盡可能接近真實數據的假數據,而判別器的任務是盡可能準確地判斷輸入的數據是真實的還是由生成器生成的。兩者通過相互競爭和不斷迭代優化,最終生成器能夠產生非常接近真實數據的輸出。
應用場景:圖像生成、音頻生成、視頻生成等。例如,StyleGAN在圖像生成領域取得了顯著的效果,能夠生成高質量、多樣化的圖像。
2. 變分自動編碼器(VAE)
原理:VAE是一種生成式模型,它通過學習數據的潛在表示來生成新數據。VAE包含編碼器(Encoder)和解碼器(Decoder)兩部分。編碼器將輸入數據壓縮成一個低維的潛在表示(latent representation),解碼器則從這個潛在表示中重構出原始數據。VAE通過最大化數據的變分下界來優化模型,使得生成的數據盡可能接近真實數據。
應用場景:圖像生成、文本生成等。VAE在圖像生成方面可以產生多樣化的輸出,同時保持一定的數據質量。
3. 神經風格遷移(Neural Style Transfer)
原理:神經風格遷移利用深度學習模型(如卷積神經網絡)來分離和重組圖像的內容和風格。它首先訓練一個模型來提取圖像的特征表示,然后將這些特征分為內容特征和風格特征。通過優化一個損失函數,可以同時保持圖像的內容不變而改變其風格,或者保持風格不變而改變其內容。
應用場景:藝術創作、圖像美化等。神經風格遷移可以將一幅畫的風格應用到另一幅畫上,產生新穎且富有藝術感的作品。
這些核心技術為AIGC提供了強大的支持,使得人工智能能夠生成創造性的內容。通過深入了解這些技術的原理和應用場景,學生可以更好地理解AIGC的實現方式和工作原理。
核心技術的算法解析
算法解析
1. 生成對抗網絡(GAN)
工作原理:
GAN由兩部分組成:生成器G和判別器D。生成器G的任務是生成假數據,而判別器D的任務是判斷數據是否為真。訓練過程中,G和D相互競爭,不斷調整各自的參數,直到G能夠生成足以欺騙D的假數據。
輸入輸出:
- 輸入:隨機噪聲z(對于G)和真實/假數據x(對于D)
- 輸出:G輸出假數據x’,D輸出一個概率值表示x是否為真
關鍵步驟:
- 初始化G和D的參數。
- 從噪聲分布中采樣隨機噪聲z。
- 使用G生成假數據x’ = G(z)。
- 將真實數據x和假數據x’混合,輸入到D中進行訓練。
- 更新D的參數以最小化真實數據上的分類錯誤和最大化假數據上的分類錯誤。
- 使用D的輸出作為G的輸入,訓練G以最小化D的分類準確率。
- 重復步驟2-6直到收斂或達到最大迭代次數。
數學公式:
- D的損失函數:(L_D = -\mathbb{E}{x \sim p{data}(x)}[\log D(x)] - \mathbb{E}_{z \sim p_z(z)}[\log(1 - D(G(z)))])
- G的損失函數:(L_G = -\mathbb{E}_{z \sim p_z(z)}[\log D(G(z))])
圖形:
- 可以使用一個簡單的流程圖來表示GAN的訓練過程,包括G和D的交替訓練步驟。
2. 變分自動編碼器(VAE)
工作原理:
VAE通過編碼器將輸入數據編碼為一個低維的潛在表示,然后通過解碼器從這個潛在表示中重構出原始數據。同時,VAE還引入了一個正則化項來鼓勵潛在表示遵循一個先驗分布(如標準正態分布)。
輸入輸出:
- 輸入:原始數據x
- 輸出:重構數據x’和潛在表示z
關鍵步驟:
- 初始化編碼器和解碼器的參數。
- 將原始數據x輸入到編碼器中,得到潛在表示z = Encoder(x)。
- 對潛在表示z進行采樣,得到一個新的潛在表示z’。
- 將z’輸入到解碼器中,得到重構數據x’ = Decoder(z’)。
- 計算重構損失(如均方誤差)和潛在表示的正則化損失(如KL散度)。
- 更新編碼器和解碼器的參數以最小化總損失。
- 重復步驟2-6直到收斂或達到最大迭代次數。
數學公式:
- 總損失:(L_{total} = L_{recon} + L_{KL})
- 重構損失(均方誤差):(L_{recon} = \mathbb{E}{x \sim p{data}(x)}[||x - Decoder(Encoder(x))||^2])
- 潛在表示的正則化損失(KL散度):(L_{KL} = \mathbb{E}_{z \sim q(z|x)}[\log \frac{q(z|x)}{p(z)}])
圖形:
- 可以使用一個簡單的結構圖來表示VAE的編碼器、解碼器和潛在空間。
3. 神經風格遷移
工作原理:
神經風格遷移利用預訓練的卷積神經網絡(如VGG)來提取圖像的內容和風格特征。然后,通過優化一個損失函數來同時保持圖像的內容不變而改變其風格,或者保持風格不變而改變其內容。
輸入輸出:
- 輸入:內容圖像C、風格圖像S和一張隨機初始化的空白圖像T
- 輸出:遷移后的圖像T’,它結合了C的內容和S的風格
關鍵步驟:
- 使用預訓練的VGG網絡來提取內容圖像C和風格圖像S的特征。
- 初始化一張空白圖像T,并設置優化器(如L-BFGS)。
- 定義損失函數,包括內容損失(內容圖像C和遷移圖像T’在VGG某一層的特征差異)和風格損失(風格圖像S和遷移圖像T’在VGG多個層的特征統計差異)。
- 使用優化器迭代更新T的像素值,以最小化損失函數。
- 重復步驟3-4直到達到最大迭代次數或損失函數收斂。
數學公式:
- 內容損失:(L_{content} = \frac{1
案例及部分代碼實現
案例分析:AIGC在不同領域的應用與創新
為了讓學生更深入地了解AIGC在不同領域的應用和創新,我會分享一些成功的AIGC應用案例,并進行詳細分析。
1. 藝術作品
案例:使用StyleGAN生成的名人肖像畫
分析:StyleGAN是一種先進的圖像生成技術,它通過學習大量的圖像數據,能夠生成高度逼真和多樣化的圖像。在這個案例中,StyleGAN被用來生成名人肖像畫。通過調整參數和風格,藝術家能夠創作出與真實照片難以區分的肖像畫,展現出AIGC在藝術創作領域的巨大潛力。
代碼實現
要使用StyleGAN生成名人肖像畫,首先需要訪問一個已經訓練好的StyleGAN模型。通常,這些模型是由大型數據集(如FFHQ,即Flickr Faces HQ數據集)訓練得到的,包含了數千張高質量的人臉圖片。由于StyleGAN模型的復雜性,通常建議使用預訓練的模型,而不是從頭開始訓練。
以下是一個使用Python和PyTorch框架的簡化示例,展示了如何使用預訓練的StyleGAN模型來生成名人肖像畫。請注意,這個示例假設你已經有一個可用的StyleGAN模型和相應的權重文件。
首先,確保安裝了必要的庫:
pip install torch torchvision
然后,你可以使用以下代碼來加載預訓練的StyleGAN模型并生成圖像:
import torch
from PIL import Image
from torchvision import transforms
from torchvision.transforms.functional import resize
from stylegan2_pytorch import StyleGAN2# 加載預訓練的StyleGAN模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = StyleGAN2(config_path="path/to/config.pt", checkpoint_path="path/to/stylegan2.pt").to(device)
model.eval()# 加載并預處理輸入圖像(如果要用作條件輸入)
transform = transforms.Compose([transforms.Resize((1024, 1024)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# 假設我們有一個名人肖像的輸入圖像
input_image = Image.open("path/to/celebrity_portrait.jpg")
input_tensor = transform(input_image).unsqueeze(0).to(device)# 生成圖像
with torch.no_grad():latent = model.mean_latent(10000) # 使用平均潛在向量output = model(input_tensor, latent, truncation_psi=0.7, noise_mode='const')# 將輸出張量轉換為圖像
output_image = (output.squeeze().permute(1, 2, 0) * 0.5 + 0.5).clamp(0, 1).mul(255).permute(2, 0, 1).byte().cpu().numpy()
output_image = Image.fromarray(output_image.astype('uint8'))# 顯示或保存生成的圖像
output_image.show()
output_image.save("path/to/generated_portrait.png")
在這個示例中,我們首先加載了預訓練的StyleGAN模型,然后定義了一個預處理流程來準備輸入圖像(如果有的話)。我們使用了模型的mean_latent方法來獲取一個平均潛在向量,這個向量通常用于無條件生成。然后,我們調用模型生成圖像,并將輸出張量轉換為PIL圖像對象,最后顯示或保存生成的圖像。
請注意,這個示例僅供學習目的,并且假設你已經有了適當的模型和配置文件。實際使用中,你需要替換config_path和checkpoint_path變量,指向你的StyleGAN模型和權重文件。此外,StyleGAN2模型和其他相關代碼可能需要從專門的庫或資源中獲取。
2. 設計項目
案例:使用VAE生成家居設計方案
分析:VAE(變分自動編碼器)是一種生成式模型,能夠生成多樣化的數據。在這個案例中,設計師利用VAE生成了多種家居設計方案。他們首先訓練了一個VAE模型,使其學習到家居設計的潛在表示。然后,通過調整潛在空間的參數,設計師能夠生成出各種創新且實用的家居設計方案,從而加速設計過程并拓寬設計思路。
要使用VAE(變分自動編碼器)生成家居設計方案,你需要先準備一個包含家居設計圖像的數據集,然后訓練VAE模型來學習這些設計的潛在表示。一旦模型訓練完成,你可以通過調整潛在空間中的向量來生成新的設計方案。
以下是一個使用PyTorch框架實現VAE生成家居設計方案的簡化示例代碼:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader# 定義VAE模型
class VAE(nn.Module):def __init__(self, input_dim=784, hidden_dim=400, latent_dim=20):super(VAE, self).__init__()self.fc1 = nn.Linear(input_dim, hidden_dim)self.fc21 = nn.Linear(hidden_dim, latent_dim) # mean layerself.fc22 = nn.Linear(hidden_dim, latent_dim) # log variance layerself.fc3 = nn.Linear(latent_dim, hidden_dim)self.fc4 = nn.Linear(hidden_dim, input_dim)def encode(self, x):h1 = torch.relu(self.fc1(x))return self.fc21(h1), self.fc22(h1)def reparameterize(self, mu, logvar):std = torch.exp(0.5*logvar)eps = torch.randn_like(std)return mu + eps*stddef decode(self, z):h3 = torch.relu(self.fc3(z))return torch.sigmoid(self.fc4(h3))def forward(self, x):mu, logvar = self.encode(x.view(-1, 784))z = self.reparameterize(mu, logvar)return self.decode(z), mu, logvar# 超參數設置
input_dim = 784 # 圖片展平后的維度
hidden_dim = 400
latent_dim = 20
learning_rate = 1e-3
epochs = 50
batch_size = 128# 數據預處理
transform = transforms.Compose([transforms.ToTensor(),transforms.Lambda(lambda x: x.mul(255))
])# 加載家居設計圖片數據集
dataset = datasets.ImageFolder(root='path/to/home_design_images', transform=transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)# 實例化VAE模型、損失函數和優化器
model = VAE(input_dim, hidden_dim, latent_dim)
reconstruction_loss = nn.BCELoss(reduction='sum')
kl_divergence_loss = nn.KLDivLoss(reduction='batchmean')
optimizer = optim.Adam(model.parameters(), lr=learning_rate)# 訓練VAE模型
for epoch in range(epochs):for images, _ in dataloader:# 訓練VAErecon_batch, mu, logvar = model(images)reconstruction_loss_batch = reconstruction_loss(recon_batch, images)kl_divergence = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())loss = reconstruction_loss_batch + kl_divergenceoptimizer.zero_grad()loss.backward()optimizer.step()print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item()}')# 生成新的家居設計方案
def generate_designs(model, num_designs=5):with torch.no_grad():z = torch.randn(num_designs, latent_dim)images = model.decode(z)return images# 生成并保存設計方案
generated_designs = generate_designs(model)
save_image(generated_designs.data.cpu(), 'generated_home_designs.png', nrow=5)
在這個示例中,我們定義了一個VAE模型,它由一個編碼器、一個解碼器以及一個用于重參數化的函數組成。
3. 影視特效
案例:使用神經風格遷移技術制作電影特效
分析:神經風格遷移是一種能夠將一幅畫的風格應用到另一幅畫上的技術。在影視特效領域,這項技術被用來制作各種獨特的視覺效果。例如,在電影中,神經風格遷移可以被用來將某個場景的風格轉變為另一個完全不同的風格(如將現代城市轉變為中世紀城堡),從而為觀眾帶來全新的視覺體驗。
4. 廣告創意
案例:使用AIGC技術生成動態廣告海報
分析:AIGC技術也可以用于廣告創意領域。通過結合圖像生成、視頻生成等技術,可以快速生成多樣化的動態廣告海報。這些海報不僅具有高度的創意性和個性化,而且能夠根據目標受眾的喜好進行定制,從而提高廣告的吸引力和轉化率。
代碼實現
import aigc_library # 假設這是你的AIGC庫 # 初始化AIGC庫
ai_generator = aigc_library.AIGCGenerator() # 定義海報參數
poster_theme = 'tech' # 海報主題
poster_size = (1920, 1080) # 海報尺寸
dynamic_effects = ['fade_in', 'zoom_out'] # 動態效果列表 # 生成海報背景
background_image = ai_generator.generate_image(theme=poster_theme, size=poster_size) # 生成海報內容
content_image = ai_generator.generate_content_image(theme=poster_theme, text='New Product Launch') # 將內容添加到背景
final_image = aigc_library.combine_images(background_image, content_image) # 添加動態效果
for effect in dynamic_effects: final_image = ai_generator.apply_dynamic_effect(final_image, effect) # 保存或發布海報
aigc_library.save_image(final_image, 'dynamic_poster.mp4') # 假設輸出為視頻格式 # 發布到社交媒體或網站
# ... # 評估廣告效果
# ...
總結
通過以上案例分析,我們可以看到AIGC技術在不同領域的應用和創新。無論是藝術創作、設計項目、影視特效還是廣告創意,AIGC技術都為我們提供了全新的創作方式和手段。
AI 匯總持續整理、持續學習中。。。
試用了部分工具,還可以,跟語言描述有很大關系,有喜歡的可以去試試;
也不能過分依賴AI,有的時候挺一言難盡的。。。
純屬個人觀點






)



 -- 異常類型和生命周期)










