一、CPU緩存結構
1.1 CPU的多級緩存
因為CPU的計算速度非常快,但內存的訪問速度相對較慢。因此,如果CPU每次都要從內存讀取數據,會造成大量的等待時間,降低整體性能。
通過引入多級緩存,可以在CPU和內存之間建立數據緩存層,將最常用的數據暫時保存在靠近CPU的高速緩存(CPU Cache)中,以供CPU快速訪問。不同級別的緩存容量和訪問速度各不相同,一般來說,L1緩存最小、速度最快,L2緩存次之,L3緩存最大但速度相對較慢。并且 L1和L2 是 CPU 私有,L3 是所有 CPU 共享。

多級緩存的設計可以實現更高的命中率,即CPU能夠更頻繁地從高速緩存中獲取需要的數據,減少對內存的訪問次數,從而提高整體性能。
1.2 Cache Line
CPU 從內存中讀取數據到 CPU Cache 的過程中,是一小塊一小塊來讀取數據的。這樣一小塊一小塊的數據,在 CPU Cache 里面,我們把它叫作緩存行(Cache Line)。即,Cache Line是CPU緩存中的最小可讀寫單元,用于存儲從主存中讀取的數據塊。日常使用的 Intel 服務器或者 PC 里,Cache Line 的大小通常是 64 字節。
當CPU訪問內存時,如果所需數據在緩存中已經存在于一個Cache Line中,那么CPU可以直接從緩存中讀取數據,而無需訪問主存,從而提高了數據傳輸的速度。

-
標志位(flag):用于指示Cache Line當前是否有效。當一個Cache Line中存儲的數據被更新或替換時,標志位會被清除,表示該Cache Line不再有效。(存MESI 的狀態)
-
標記(tag):用于標識數據區域中存儲的數據塊是來自哪個主存地址。當CPU需要讀取或寫入特定地址的數據時,它會將該地址的一部分作為標記,并與Cache Line中存儲的標記進行比較,以確定是否命中緩存。
-
數據區域(data):用于存儲從主存中讀取的數據塊。
二、寫回策略
寫回策略(Write Back)是一種用于緩存管理的寫入更新方式。當數據被修改時,寫回策略將更新后的數據首先寫入緩存,而不立即寫入主內存。
具體來說,當緩存中的某個數據被修改時,寫回策略將在修改時更新緩存中的對應數據,并將其標記為臟數據,表示該數據已經被修改過。然后,當需要替換這個被修改的數據時,才將更新后的數據寫回主內存。
-
當請求是寫請求時
1)若命中,直接將新數據寫入緩存,并且標記為臟數據dirty(緩存中修改過但尚未寫回到更高級別緩存或主內存中的數據)。注意此時不會寫入內存。
2)若未命中,分配一個緩存塊Cache Line,判斷當前緩存塊是不是臟數據。如果是,先將緩存塊的數據寫回內存中,再將新數據寫入緩存塊。如果不是臟數據,直接從內存中讀到緩存塊中(建立內存塊與緩存塊的索引關系),再將新數據寫入緩存塊,并標記為dirty。
-
當請求是讀請求時
1)若命中,直接返回其數據;
2)若未命中時,分配一個緩存塊,判斷當前緩存塊是不是臟數據。如果是,先將緩存塊的數據寫回下一級存儲中,再從內存讀取新數據到緩存塊中。如果不是臟數據,直接從內存中讀到緩存塊中,修改dirty位為clean(未被修改)。最后返回數據。

這種策略的主要優勢在于減少了向主內存寫入數據的次數。相比于每次數據修改都直接寫入主內存(寫直達,Write Through),寫回策略可以將多次對同一塊數據的修改累積起來,一次性地寫回主內存,減少了對主內存的訪問,提高了效率。
相關視頻推薦
2024年c/c++程序員如何提升自己的核心競爭力?這套linux c/c++后端服務器開發技術教程不要錯過!![]() https://www.bilibili.com/video/BV1CF4m1L7hU/
https://www.bilibili.com/video/BV1CF4m1L7hU/
免費學習地址:Linux C/C++開發(后端/音視頻/游戲/嵌入式/高性能網絡/存儲/基礎架構/安全)
需要C/C++ Linux服務器架構師學習資料加qun579733396獲取(資料包括C/C++,Linux,golang技術,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒體,CDN,P2P,K8S,Docker,TCP/IP,協程,DPDK,ffmpeg等),免費分享

三、緩存一致性問題及解決方案
3.1 緩存一致性問題
上面介紹的寫回策略,延遲數據寫入主內存的時機,可能會帶來數據一致性的問題。因為CPU是多核的,在數據被修改后,尚未寫回主內存之前,如果發生了緩存替換或其他操作,主內存上的數據可能是過期的。
比如在多處理器系統下,核心A和核心A共享一塊主存。假如核心A從主存中讀取到 x,并對其加 1 ,此時還沒有寫回主存。與此同時,核心B 也從主存中讀取 x ,并加 1 。但是它們都不知道對方的存在,也不可以讀取對方的緩存。若這時都將 x 寫回主存,那此時 x 的值就少了 1 ,出現了數據不一致的問題。
3.2 解決方案
3.2.1 總線嗅探
當一個處理器執行一個寫操作時,它會在總線上廣播一個寫請求,并在總線上傳輸要寫入的數據。其他處理器的總線嗅探器會監聽到該寫請求,并檢查請求中的地址。如果某個處理器的緩存中包含了該地址的數據塊,總線嗅探器就會將該緩存塊標記為“無效”,表示該數據已經過期,需要從主內存或其他緩存中重新獲取最新的數據。
同樣地,當一個處理器執行一個讀操作時,總線嗅探器也會監聽到該讀請求,并檢查請求中的地址。如果某個處理器的緩存中包含了該地址的數據塊,總線嗅探器會檢查該數據塊是否為“臟”,即是否被修改過。如果是臟數據,則總線嗅探器負責將該數據寫回到主內存或其他緩存中,以保證數據的一致性。
通過總線嗅探技術,處理器能夠感知其他處理器對共享數據的讀寫操作,并及時更新自己的緩存,以確保所有處理器都能訪問到最新的共享數據。
3.2.2 事務的串行化
舉個例子,假設有兩個事務 T1 和 T2,我們希望它們并發執行的過程如下:
T1:讀取數據 A,修改數據 A(A = 10 ~> A = 20)
T2:讀取數據 A,修改數據 A(A = 20 ~> A = 30)
但是如果這兩個事務并發執行,并未經過任何的串行化控制,可能出現以下情況:
T1 先執行讀取操作,讀取到 A 的值為 10;
T2 在 T1 執行讀取操作后執行讀取操作,讀取到 A 的值也為 10;
T1 執行修改操作,將 A 的值修改為 20;
T2 也執行修改操作,將 A 的值修改為 30;
在這種情況下,最終 A 的值是 30,而不是按照順序執行時的 20。
然而,如果采用串行化控制,將 T1 和 T2 串行化執行,保證它們不會交叉執行,那么最終的結果將與串行執行的結果一致。具體的串行化執行過程如下:
T1 先執行讀取操作,讀取到 A 的值為 10;
T1 執行修改操作,將 A 的值修改為 20;
T2 在 T1 執行完畢后執行讀取操作,讀取到 A 的值為 20;
T2 執行修改操作,將 A 的值修改為 30;
采用串行化控制后,最終 A 的值為 30,與串行執行的結果一致。
可以通過對線程T1加鎖,保證T1執行時候,T2不會產生干擾,達到串行效果。
3.2.3 MESI
通過事務的串行化,每當有核心修改數據,都需要廣播給其他的核心。但是,并不是所有的核心都與這個數據相關。這樣就會浪費帶寬,代價比較大。接下來引入MESI來解決這個問題。
MESI是一種緩存一致性協議,用于解決多核處理器中的緩存一致性問題。CPU 中每個緩存行(caceh line)都使用MESI進行標記,MESI是四種狀態的縮寫,分別代表了緩存行的不同狀態:修改(Modified)、獨占(Exclusive)、共享(Shared)和無效(Invalid)。
1)修改(Modified):當某個核心獨占地擁有一塊緩存行的數據時,如果該核心對緩存行進行了修改,那么該緩存行的狀態為修改狀態。同時,該核心對緩存行所做的修改還沒有寫回到主存中。
2)獨占(Exclusive):如果某個核心獨占地擁有一塊緩存行的數據,并且該數據未被修改,那么該緩存行的狀態為獨占狀態。此時,其他核心不能緩存該緩存行中的數據。
3)共享(Shared):當多個核心同時緩存同一塊緩存行的數據時,該緩存行的狀態為共享狀態。多個核心可以同時讀取該數據,但不能進行寫操作。
4)無效(Invalid):如果某個核心的緩存中的數據與主存中的數據不一致,或者某個核心將共享緩存行標記為無效狀態,那么該緩存行的狀態就會變為無效狀態。此時,其他核心不能使用該緩存行中的數據,必須從主存中獲取最新的數據。
四、原子操作
4.1 什么是原子操作
原子操作是指在執行過程中不會被中斷的操作,要么全部執行成功,要么全部不執行,不會出現部分執行的情況。原子操作可以看作是不可分割的單元, 運行期間不會有任何的上下文切換。
1)在單核處理器上,原子操作可以通過禁止中斷的方式來保證不被中斷。當一個線程或進程執行原子操作時,可以通過禁用中斷來確保原子性。在禁用中斷期間,其他線程或進程無法打斷當前線程或進程的執行,從而保證原子操作的完整性。
2)在多核處理器上,原子操作的實現需要使用一些特殊的硬件機制或同步原語來保證原子性。以下是兩種常見的方法:
1、使用硬件原子指令:現代多核處理器通常支持硬件原子指令,例如CAS(Compare-And-Swap)指令。這樣的指令允許對共享內存進行原子讀取和寫入操作。CAS指令會比較內存中的值與期望值,如果相等則執行寫入操作,否則不執行。通過使用這樣的原子指令,可以在多核處理器上實現原子操作。
2、使用鎖和同步原語:多核處理器上的原子操作可以通過鎖來實現互斥訪問。以往0x86,是直接鎖總線,避免所有內存的訪問。現在是只需要鎖住相關的內存,比較其他核心對這塊內存的訪問。
4.2 c++ 標準庫的原子類型
4.2.1 atomic<T>
atomic<T> 是 C++ 中的原子類型模板,用于實現原子操作。它提供了一種線程安全的方式來對特定類型的數據進行讀取和寫入,以及執行其他常見的原子操作,如增加(增量)和交換等。
atomic<T> 提供了以下常用的成員函數和操作符:
1)加載和存儲操作:通過 load() 和 store() 方法可以實現從原子對象中加載值或將值存儲到原子對象中。
2)交換和比較交換操作:使用 exchange() 可以原子地將新值存儲到原子對象中,并返回之前的值;使用 compare_exchange_strong() 或 compare_exchange_weak() 可以原子地比較并交換值。
3)增減操作:使用 fetch_add() 和 fetch_sub() 可以原子地增加或減少原子對象的值,并返回之前的值。
4)訪問操作:除了上述操作,還可以使用 operator++、operator–、operator+=、operator-= 等操作符進行原子操作。
4.2.2 is_lock_free()
用于檢查原子類型是否是無鎖(lock-free)的。它返回一個布爾值,指示原子類型是否可以在特定硬件平臺上以無鎖方式進行操作。
bool is_lock_free() const noexcept;如果 is_lock_free() 返回 true,表示該原子類型可以在特定硬件平臺上以無鎖方式進行操作;如果返回 false,則表示該原子類型無法以無鎖方式進行操作,需要使用鎖或其他同步機制。
4.2.3 load()
獲取原子對象中的當前值,并返回該值。它會保證在多線程環境下對數據的讀取是原子的,即不會受到其他線程同時修改的干擾,保證了數據的一致性。
load(memory_order order = memory_order_seq_cst) const noexcept;參數 order 是一個可選參數,用于指定內存序(memory order)的類型,默認為 memory_order_seq_cst。內存序定義了原子操作的時序關系,決定了在多線程環境下對數據訪問的可見性和有序性。
4.2.4 store()
用于原子地存儲(寫入)值到原子對象中。它可以將給定的值存儲到原子對象中,并保證在多線程環境下的可見性和原子性。
void store(T value, memory_order order = memory_order_seq_cst) noexcept;參數 value 是要存儲到原子對象中的值,參數 order 是一個可選參數,用于指定內存序(memory order)的類型,默認為 memory_order_seq_cst。
4.2.5 exchange()
用于原子地交換原子對象中的值,并返回先前的值。它可以將給定的值與原子對象的當前值進行交換,并保證在多線程環境下的可見性和原子性。
exchange(T desired, memory_order order = memory_order_seq_cst) noexcept;參數 desired 是要與原子對象進行交換的值,參數 order 是一個可選參數,用于指定內存序(memory order)的類型,默認為 memory_order_seq_cst。
4.2.6 compare_exchange_weak()
用于原子地比較并交換原子對象的值。它可以比較原子對象的當前值與期望值,并在匹配時將新值存儲到原子對象中。
bool compare_exchange_weak(T& expected, T desired,memory_order success, memory_order failure) noexcept;參數 expected 是對原子對象進行比較的期望值,并且在返回時被更新為原子對象的當前值。參數 desired 是要存儲到原子對象中的新值。參數 success 和 failure 分別指定了成功和失敗情況下的內存序(memory order)類型,默認為 memory_order_seq_cst。
返回值是一個 bool 類型,表示是否成功執行了比較和交換操作。如果比較的值與期望值相等,則交換成功,返回 true,否則交換失敗,返回 false。
weak版本的CAS允許偶然出乎意料的返回(比如在字段值和期待值一樣的時候卻返回了false),不過在一些循環算法中,這是可以接受的。通常它比起strong有更高的性能。
舉個例子
a.compare_exchange_weak(b,c)其中a是當前值,b期望值,c新值
a==b時:函數返回真,并把c賦值給a
a!=b時:函數返回假,并把a復制給b
#include <iostream> // std::cout
#include <atomic> // std::atomic, std::atomic_flag, ATOMIC_FLAG_INITint main() //相等案例
{std::atomic<int> a;a.store(10);int b=10; //a==bint c=20;std::cout<<"a:"<<a<<std::endl;while(!a.compare_exchange_weak(b,c)){b=10;c=20;} std::cout<<"a true:"<<a.load()<<std::endl;std::cout<<"a:"<<a<<" b:"<<b<<" c:"<<c<<std::endl;return 0;
}a:10
a true:20
a:20 b:10 c:20int main() //不等案例
{std::atomic<int> a;a.store(10);int b=100; //a!=bint c=20;std::cout<<"a:"<<a<<std::endl;while( !a.compare_exchange_weak(b,c)){b=100;c=20;} std::cout<<"a true:"<<a.load()<<std::endl;std::cout<<"a:"<<a<<" b:"<<b<<" c:"<<c<<std::endl;return 0;
}
a:10
a:10 b:10 c:204.2.7 compare_exchange_strong()
強化版的CAS,如果需要保證嚴格的原子性,則應該使用 compare_exchange_strong 函數。其他根weak版一樣。
compare_exchange_strong ------------ 會阻塞cpu, 會慢一些
compare_exchange_weak --------------- 有可能失敗,性能高, 可以加while直到它成功
五、內存序問題
5.1 什么是內存序問題
內存序(memory order)問題是由于多線程的并行執行可能導致的對共享變量的讀寫操作無法按照程序員預期的順序進行。
簡單來說,編譯器為了提高運算速度,有時候會做出違背代碼原有順序的優化。雖然順序改變了,但執行的結果不會變。比如下面一段代碼
int i=10;int j=20;i+=2;j+=3;我們以為執行順序是從上往下,但編譯器任務i和j沒有關聯,可能會優化成
int i=10;i+=2;int j=20;j+=3;在單核處理器的情況下,這種優化沒問題,因為執行的結果不會變。但是如果是多核處理器,多線程并行執行,就會出現一些難以預知的問題。比如編譯器和處理器可能會重排共享變量的寫操作,使得其中一個線程的寫操作先于另一個線程的寫操作執行。這樣會導致增量值丟失或重復計算,最終的結果可能小于預期的值。
總結來說,就是編譯器和CPU會優化重排指令,改變原始程序中指令的執行順序。這可能會導致多線程間的競態條件和數據依賴關系出現問題,從而使得程序的行為產生難以預測的結果。
需要使用適當的內存序來指定對共享變量的讀寫操作的順序和同步行為。
5.2 內存序
內存徐規定了多個線程訪問同一個內存地址的語義,即 1)某個線程對內存地址的更新何時能被其他線程看見; 2)某個線程對內存地址訪問附近可以做怎么樣的優化;
5.2.1. memory_order_relaxed
松散內存序,只用來保證對原子對象的操作是原子的,在不需要保證順序時使用。(保證原子性,不保證順序性和同步性)

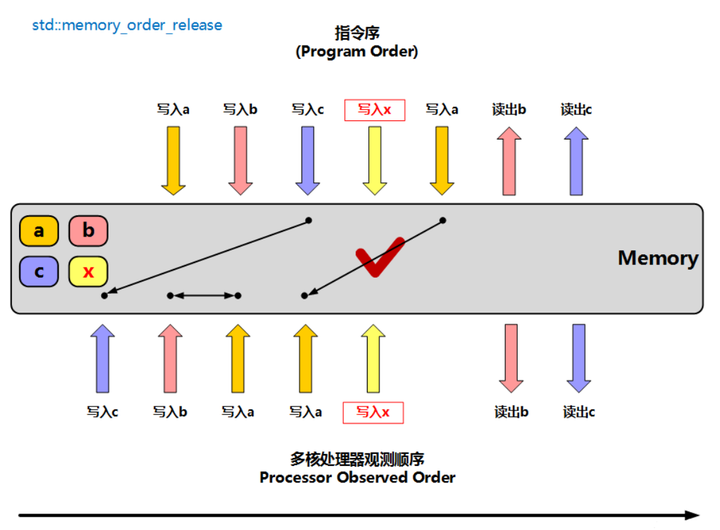
5.2.2. memory_order_release
釋放操作,在寫入某原子對象時,當前線程的任何前面的讀寫操作都不允許重排到這個操作的后面去,并且當前線程的所有內存寫入都在對同一個原子對象進行獲取的其他線程可見。(保證原子性和同步性,順序是當前線程的前面不能寫到后面;但當前線程的后面可以寫到前面)

添加圖片注釋,不超過 140 字(可選)
5.2.3. memory_order_acquire
獲得操作,在讀取某原子對象時,當前線程的任何后面的讀寫操作都不允許重排到這個操作的前面去,并且其他線程在對同一個原子對象釋放之前的所有內存寫入都在當前線程可見。(保證原子性和同步性,順序是當前線程的后面不能寫到前面;但當前線程的前面可以寫到后面)

添加圖片注釋,不超過 140 字(可選)

5.2.4. memory_order_acq_rel
獲得釋放操作,一個讀‐修改‐寫操作同時具有獲得語義和釋放語義,即它前后的任何讀寫操作都不允許重排,并且其他線程在對同一個原子對象釋放之前的所有內存寫入都在當前線程可見,當前線程的所有內存寫入都在對同一個原子對象進行獲取的其他線程可見;
5.2.5. memory_order_seq_cst
順序一致性語義,對于讀操作相當于獲得,對于寫操作相當于釋放,對于讀‐修改‐寫操作相當于獲得釋放,是所有原子操作的默認內存序,并且會對所有使用此模型的原子操作建立一個全局順序,保證了多個原子變量的操作在所有線程里觀察到的操作順序相同,當然它是最慢的同步模型。
5.3 內存屏障
內存屏障(Memory Barrier)是一種硬件或軟件指令,用于控制處理器和內存系統中對內存操作的重新排序和優化。它們的作用是確保在屏障之前和之后的內存訪問按照預期的順序進行。
內存屏障主要有兩種類型:讀屏障(Read Barrier)和寫屏障(Write Barrier)。
讀屏障(也稱為加載屏障):確保在讀取一個變量的值之前,所有之前的讀取操作和加載操作都已經完成。這可以防止讀取過期的或無效的數據。
寫屏障(也稱為存儲屏障):確保在寫入一個變量的值之前,所有之前的寫入操作和存儲操作都已經完成。這可以防止將新的值預先存儲到緩存而不是實際寫入到內存中。
內存屏障的使用可以避免在多線程或并發環境下出現的一些問題,例如數據競爭、亂序執行和原子操作的正確性。通過插入內存屏障,可以使得代碼在一個屏障之前或之后的內存訪問按照預期的順序執行,從而確保正確的內存可見性和一致性。
5.3.1atomic_thread_fence()
創建一個內存屏障(memory barrier),用于限制內存訪問的重新排序和優化。它可以保證在屏障之前的所有內存操作都在屏障完成之前完成。
void atomic_thread_fence(std::memory_order order);常見的 memory_order 參數包括:
std::memory_order_relaxed:最輕量級的內存順序,允許重排和優化。
std::memory_order_acquire:在屏障之前的內存讀操作必須在屏障完成之前完成。
std::memory_order_release:在屏障之前的內存寫操作必須在屏障完成之前完成。
std::memory_order_acq_rel:同時具有 acquire 和 release 語義,適用于同時進行讀寫操作的屏障。
std::memory_order_seq_cst:對于讀操作相當于獲得,對于寫操作相當于釋放。
六、測試代碼
6.1 多線程加鎖
四個線程,每個線程實現count++ 500次。最后結果應該是cout = 2000; 在沒有加鎖的情況下,會出現cout ≠ 2000

#include <chrono>
#include <iostream>
#include <thread>
#include <assert.h>#define USE_ATOMIC 1#if USE_MUTEX#include <mutex>std::mutex mtx;int count = 0;
#elif USE_SPINLOCK#include "spinlock.h"using spinlock_t = struct spinlock;spinlock_t spin;int count = 0;
#elif USE_ATOMIC#include <atomic>std::atomic<int> count{0};
#elseint count = 0;
#endifvoid incrby(int num) {for (int i=0; i < num; i++) {
#if USE_MUTEXmtx.lock();++count;mtx.unlock();
#elif USE_SPINLOCKspinlock_lock(&spin);++count;spinlock_unlock(&spin);
#elif USE_ATOMICcount.fetch_add(1);
#else++count;
#endif}
}int main() {
#ifdef USE_SPINLOCKspinlock_init(&spin);
#endiffor (int i = 0; i < 100; i++) {
#ifdef USE_ATOMICcount.store(0);
#elsecount = 0;
#endifstd::thread a(incrby, 500);std::thread b(incrby, 500);std::thread c(incrby, 500);std::thread d(incrby, 500);a.join();b.join();c.join();d.join();
#ifdef USE_ATOMICif (count.load() != 2000) {
#elseif (count != 2000) {
#endifstd::cout << "i:" << i << " count:" << count << std::endl;break;}}return 0;
}6.2 內存序問題
1)實現功能:
初始x,y都為false;z為0;
線程a:先將x寫為true,再將y寫為true
線程b:自旋等待,知道讀到的y為true,再判斷達到x是否為true,若x為true,++z
2)若函數write_x_then_y()和read_y_then_x()的內存序如下

則在極少數情況下,結果z不為1.
這是因為memory_order_relaxed不保證執行順序,因此編譯器和處理器可能會優化重排。此時會出現一種執行順序:4~> 1 ~> 2 ~> 3 。
這就是線程b中對共享變量y的讀操作,先于線程a對y的寫操作執行。這樣會導致某個線程讀取到較舊的值,而不是最新的值,影響最終結果的準確性。
3)若函數write_x_then_y()和read_y_then_x()的內存序如下

這時結果z一定為1。
這是因為內存序memory_order_release有順序性,保守當前線程前面的操作不能優化到后面,即1一定在2前面。并且還有同步性,即2若執行了,1一定執行了。
內存序memory_order_acquire有順序性,保守當前線程后面的操作不能優化到前面,即3一定在4前面.
#include <atomic>
#include <thread>
#include <assert.h>
#include <iostream>std::atomic<bool> x,y;
std::atomic<int> z;void write_x_then_y()
{x.store(true,std::memory_order_relaxed); // 1 y.store(true,std::memory_order_release); // 2 y = true x= true
}void read_y_then_x()
{while(!y.load(std::memory_order_acquire)); // 3 自旋,等待y被設置為trueif(x.load(std::memory_order_relaxed)) // 4++z;
}int main()
{x=false;y=false;z=0;std::thread a(write_x_then_y);std::thread b(read_y_then_x);a.join();b.join();std::cout << z.load(std::memory_order_relaxed) << std::endl;return 0;
}6.3 多線程同步問題
實現功能:
創建2個線程,線程t1執行i從0加到9999,結果按原子操作寫入x;線程t2執行i從0減到-9999,結果按原子操作寫入x;最后打印出x的值。
6.3.1 問題
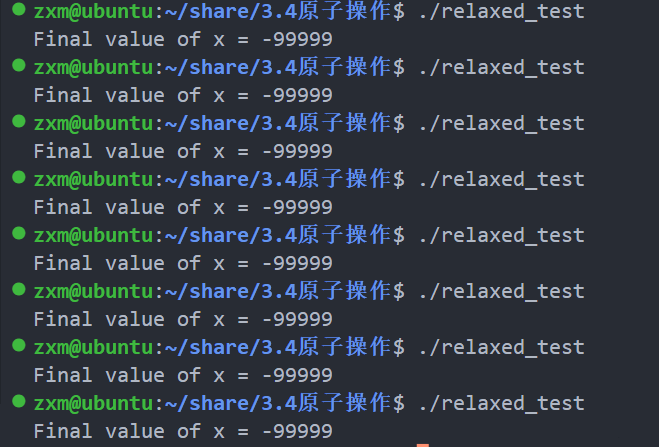
代碼1的執行結果如圖,結果出現錯亂。有時候是9999,有時候是-9999。這是因為兩個線程將結果存入主存的順序是不確定的。

代碼1
#include <atomic>
#include <thread>
#include <iostream>std::atomic<int> x(0);void thread_func1()
{for (int i = 0; i < 100000; ++i){x.store(i, std::memory_order_relaxed);}
}void thread_func2()
{for (int i = 0; i < 100000; ++i){x.store(-i, std::memory_order_relaxed);}
}int main()
{std::thread t1(thread_func1);std::thread t2(thread_func2);t1.join();t2.join();std::cout << "Final value of x = " << x.load(std::memory_order_relaxed) << std::endl;return 0;
}6.3.2 解法一:標志位
代碼2通過添加一個標志位來控制線程t1的執行
代碼2
#include <atomic>
#include <thread>
#include <iostream>std::atomic<int> x(0);
std::atomic<bool> t1_finished(false); // 標志位,表示線程t1是否已完成void thread_func1()
{for (int i = 0; i < 100000; ++i){x.store(i, std::memory_order_release);}t1_finished.store(true, std::memory_order_release); // 在線程t1完成后設置標志位為true
}void thread_func2()
{while (!t1_finished.load(std::memory_order_acquire)) // 檢查標志位,如果線程t1未完成,則等待{std::this_thread::yield();}for (int i = 0; i < 100000; ++i){x.store(-i, std::memory_order_release);}
}int main()
{std::thread t1(thread_func1);std::thread t2(thread_func2);t1.join();t2.join();std::cout << "Final value of x = " << x.load(std::memory_order_acquire) << std::endl;return 0;
}6.3.3 解法二:互斥鎖
代碼3,在線程t2中,每次修改x之前使用了std::lock_guardstd::mutex來自動加鎖,以確保線程t2的操作在同一時刻只有一個線程進行。這樣就能夠保證最后只輸出線程t2的結果。
代碼3
#include <atomic>
#include <thread>
#include <iostream>
#include <mutex>std::atomic<int> x(0);
std::mutex mtx; // 互斥鎖void thread_func1()
{for (int i = 0; i < 100000; ++i){x.store(i, std::memory_order_relaxed);}
}void thread_func2()
{for (int i = 0; i < 100000; ++i){std::lock_guard<std::mutex> lock(mtx); // 加鎖x.store(-i, std::memory_order_relaxed);}
}int main()
{std::thread t1(thread_func1);std::thread t2(thread_func2);t1.join();t2.join();std::cout << "Final value of x = " << x.load(std::memory_order_acquire) << std::endl;return 0;
}6.3.4 解法三:內存屏障
在線程t2的循環中插入了std::atomic_thread_fence(std::memory_order_release)內存屏障指令。該指令用于確保在執行x.store(-i, std::memory_order_relaxed)之前的所有先行寫操作對于其它線程的讀操作都可見。這樣我們就能夠保證最終只輸出線程t2的結果。
#include <atomic>
#include <thread>
#include <iostream>std::atomic<int> x(0);void thread_func1()
{for (int i = 0; i < 100000; ++i){x.store(i, std::memory_order_release);}
}void thread_func2()
{for (int i = 0; i < 100000; ++i){x.store(-i, std::memory_order_release);std::atomic_thread_fence(std::memory_order_release); // 插入內存屏障}
}int main()
{std::thread t1(thread_func1);std::thread t2(thread_func2);t1.join();t2.join();std::cout << "Final value of x = " << x.load(std::memory_order_acquire) << std::endl;return 0;
}


)



 -- 異常類型和生命周期)











- 對ChatGPT的常見誤解)