目錄
一、技術架構
二、業務挑戰
2.1 調度任務量大
2.2?運維復雜
2.3?SLA要求高
三、調度優化實踐
3.1?重復調度
3.2?漏調度
3.3?Worker服務卡死
3.4?任務重復運行
四、服務監控
4.1?方法耗時監控
4.2?任務調度鏈路監控
五、用戶收益
原文大佬的這篇調度系統案例有借鑒意義,這里直接摘抄下來用作學習和知識沉淀。
一、技術架構
? 在我們公司的大數據離線任務調度架構中,調度平臺處于中間層,通過數據集成平臺、數據開發平臺將工作流提交給調度平臺。

二、業務挑戰
2.1 調度任務量大
? ? 目前每天調度的工作流實例在3萬多,任務實例在14萬多。每天調度的任務量非常龐大,要保障這么多任務實例穩定、無延遲運行,是一個非常大的挑戰。
2.2?運維復雜
? ? 因為每天調度的任務實例非常多,經歷了幾次調度機器擴容階段,目前2個調度集群有6臺Master、34臺Worker機器。
2.3?SLA要求高
? ? 由于業務的金融屬性,如果調度服務穩定性出問題,導致任務重復調度、漏調度或者異常,損失影響會非常大。
三、調度優化實踐
? ?我們在過去一年,對于調度服務穩定,我們做了如下2個方向的優化。第一,調度服務穩定性優化。第二、調度服務監控。
3.1?重復調度
? ? ?用戶大規模遷移工作流時,遇到了工作流重復調度問題。現象是同一個工作流會在同一個集群同一時間,生成2個工作流實例。經過排查,基于從A項目遷移到B項目的需求,在工作流上線時,用戶通過提交工單,修改了調度數據庫中工作流的項目ID,進行遷移。這么做會導致該工作流所對應的quartz(分布式調度器)元數據產生2條數據,進而導致該工作流重復調度。如圖3所示,JOB_NAME為’job_1270’的記錄,有2條數據,而JOB_GROUP不一樣。查詢源碼job_name對應工作流的定時器ID,JOB_GROUP對應項目ID。因此修改工作流對應的項目ID,會導致quartz數據重復和重復調度。正確遷移工作流項目的方式是,先下線工作流,然后再修改項目ID。

SELECT count(1)FROM (SELECT TRIGGER_NAME, count(1) AS num FROM QRTZ_TRIGGERS GROUP BY TRIGGER_NAME HAVING num > 1 )t3.2?漏調度
? ? ??凌晨2點調度太集中,有些工作流發生漏調度。因此優化了quartz參數,將org.quartz.jobStore.misfireThreshold從60000調整為600000。
如何監控和避免此問題,監控sql摘要如下:
select TRIGGER_NAME,NEXT_FIRE_TIME ,PREV_FIRE_TIME,NEXT_FIRE_TIME-PREV_FIRE_TIME from QRTZ_TRIGGERS where NEXT_FIRE_TIME-PREV_FIRE_TIME=86400000*2
? ?sql邏輯是:根據quartz(分布式調度器)的元數據表QRTZ_TRIGGERS的上一次調度時間PREV_FIRE_TIME和下一次調度時間NEXT_FIRE_TIME的差值進行監控。如果差值為24小時就正常,如果差值為48小時,就說明出現了漏調度。

? ?如果已經發生了漏調度如何緊急處理??我們實現了漏調度補數邏輯通過自定義工作流進行http接口調用。如果監控到發生了漏調度情況,可以立即運行此工作流,就能把漏調度的工作流立即調度運行起來。
3.3?Worker服務卡死
??? 這個現象是凌晨調度Worker所在機器內存占用飆升至90%多,服務卡死。
? ? ?思考產生該問題的原因是,調度worker判斷本機剩余內存時,有漏洞。假設設置了worker服務剩余內存為25G時,才不進行任務調度。但是,當worker本機剩余內存為26G時,服務判斷本機剩余內存未達到限制條件,那么開始從zk隊列中抓取任務,每次抓取10個。而每個spark的driver占用2G內存,那么本地抓取的10個任務在未來的內存占用為20G。我們可以簡單計算得出本機剩余內存為26G-20G為6G,也就是說抓取了10個任務,未來的剩余內存可能為6G,會面臨嚴重不足。
? ? 為了解決這個問題,我們參考Yarn,提出了”預申請”機制。預申請的機制是,判斷本機剩余內存時,會減去抓取任務的內存,而不是簡單判斷本機剩余內存。?
? ? 如何獲取將要抓取任務的內存大小呢??有2種方式,第一種是在創建工作流時指定本任務driver占用的內存,第二種是給一個固定平均值。
? ?綜合考慮,采用了第二種方式,因為這種方式對于用戶來說,是沒有感知的。我們對要抓取的每個任務配置1.5G(經驗值)內存,以及達到1.5G內存所需要的時間為180秒,抓取任務后,會放入緩存中,緩存過期時間為180(經驗值)秒。剩余內存計算公式,本機剩余內存 =? 【本機真實物理剩余內存】—【緩存中任務個數*1.5G】
? ? ?還是同樣的場景,本機配置的剩余內存為25G,本機實際剩余內存為26G,要抓取的任務為10個。每個任務未來占用的driver內存為1.5G。簡單計算一下,本機剩余內存=26G-10*1.5G。在“預申請”機制下,本機剩余內存為1G,小于25G,不會抓取,也就不會導致Worker機器的內存占用過高。那么會不會導致Worker服務內存使用率過低呢,比如shell、python、DataX等占用內存低的任務。結論是不會,因為我們有180秒過期機制,過期后,計算得到的本機剩余內存為變高。
? ?實施上文的內存預申請機制后,最近半年沒有遇到由于內存占用過高導致worker服務卡死的問題。以下是我們加上內存預申請機制后,worker內存使用率情況,可以看見worker最大內存使用率始終穩定保持在80%以下。

3.4?任務重復運行
? 在worker服務卡死時,我們發現yarn上的任務沒有被殺死,而master容錯時導致任務被重復提交到yarn上,最終導致用戶的數據異常。
? ?我們分析后發現,任務實例有一個app_link字段,該字段存放用戶提交的yarn任務的app id,而第一次調度的任務的app id為空。排查代碼發現worker在運行任務時,只有完成的yarn 任務,才會更新app_link字段。這樣導致master在容錯時,拿不到app id,導致舊任務沒有被殺死,最終導致任務重復提交。
? ?我們進行的第一個改進點為,在worker運行yarn任務時,從log中實時過濾出app id,然后每隔5秒將app id更新到app_link字段中。?這樣yarn任務在運行時,也就能獲取到app id,master容錯時就能殺死舊任務。
? ?第二個改進點為,在worker服務卡死從而自殺時,殺死本機上正在運行的調度服務,這樣可能master就不需要進行容錯了。?實施改進點后,最近半年沒有遇到重復調度的yarn任務了。
四、服務監控
? ? 一個穩定的系統,除了代碼上的優化,一定離不開完善的監控。DolphinScheduler 對外提供了 Prometheus 格式的基礎指標,我們新增了一些高優指標,并集成到公司內部的監控系統。通過監控大盤來查看調度系統的健康狀況,并針對不同級別的prometheus指標和閾值,配置電話 / 釘釘報警。
4.1?方法耗時監控
? ? 我們通過byte-buddy、micrometer等,實現了自定義輕量級java agent框架。這個框架實現的目標是監控java方法的最大耗時、平均耗時、qps、服務的jvm健康狀況等。并把這些監控指標通過http暴露出來,通過prometheus抓取,再通過grafana進行可視化展示,并針對不同級別的prometheus指標和閾值,配置電話 / 釘釘報警。
? ? 例如以下是master訪問zk和quartz的最大耗時,平均耗時,qps等。

以下是master服務的jvm監控指標

? ?通過該java agent,我們實現了api、master、worekr、zookeeper等服務方法耗時監控,提前發現問題并解決,避免將問題擴大到用戶感知的狀況。
4.2?任務調度鏈路監控
? ??為了保障調度任務的穩定性,有必要對任務調度的生命周期進行監控。DolphinScheduler服務調度任務的全流程是先從quartz(分布式調度器)中產生Command(待調度指令),然后將Command轉化為工作流實例,再從工作流實例生成一系列對應的任務實例,需要對該任務鏈路的生命周期進行監控。
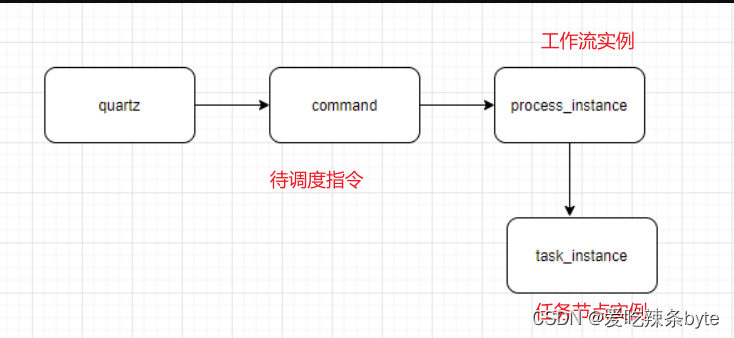
- 監控quartz元數據
? ? ?前面已經講了我們通過監控quartz元數據,發現漏調度和重復調度問題。
- 監控command表積壓情況
? ? ? 通過監控command表積壓情況,從而監控master是否服務正常,以及master服務的性能是否能夠滿足需求。
- 監控任務實例
? ? ?通過監控任務實例等待提交時間,從而監控worker服務是否正常,以及worker服務的性能是否能夠滿足需求。
? ?綜上,通過上述的全生命周期監控,可以提前感知到worker服務的性能問題,并及時解決。
五、用戶收益
? ? ?通過對DolphinScheduler代碼的優化,獲得的最大收益是近半年沒有因為調度服務故障導致用戶的SLA受影響,當調度系統出現問題時,能及時感知并解決。
參考文章:
Apache DolphinScheduler 在奇富科技的首個調度異地部署實踐


)












單容器管理)
)


