1. 什么是RDD?
RDD(Resilient Distributed Dataset)叫做彈性分布式數據集,是Spark中最基本的數據處理模型。在代碼中,RDD是一個抽象類,他代表著一個彈性的、不可變的、可分區的、里面的元素可并行計算的集合。注意,RDD只是封裝了計算邏輯,并不保存數據。RDD是一個抽象類,需要子類去實現。不可變指的是計算邏輯不可變,如果想要改變,則要產生新的RDD。
2. 五大核心屬性
源碼中五大屬性介紹如下

1)分區列表
分區的主要目的是實現并行計算/分布式計算
2)分區計算函數
以分區為單位,進行計算,每個分區的計算函數都是一樣的
3)RDD之間的依賴關系
一個RDD能夠轉換成另一個RDD,形成一種包裝的依賴關系
4)分區器
負責如何劃分分區,分區器是Option屬性,可能有,可能沒有
5)計算每個分區的首選位置
數據存儲的節點和數據計算節點可能不一樣,判斷計算發給哪個節點更好,移動數據不如移動計算
3. 執行原理
Spark框架在執行計算時,先申請資源,然后將數據處理邏輯分解成一個個計算任務,然后將計算任務發送到已經分配資源的計算節點上,按照指定的計算模型進行計算。以Yarn集群環境為例:
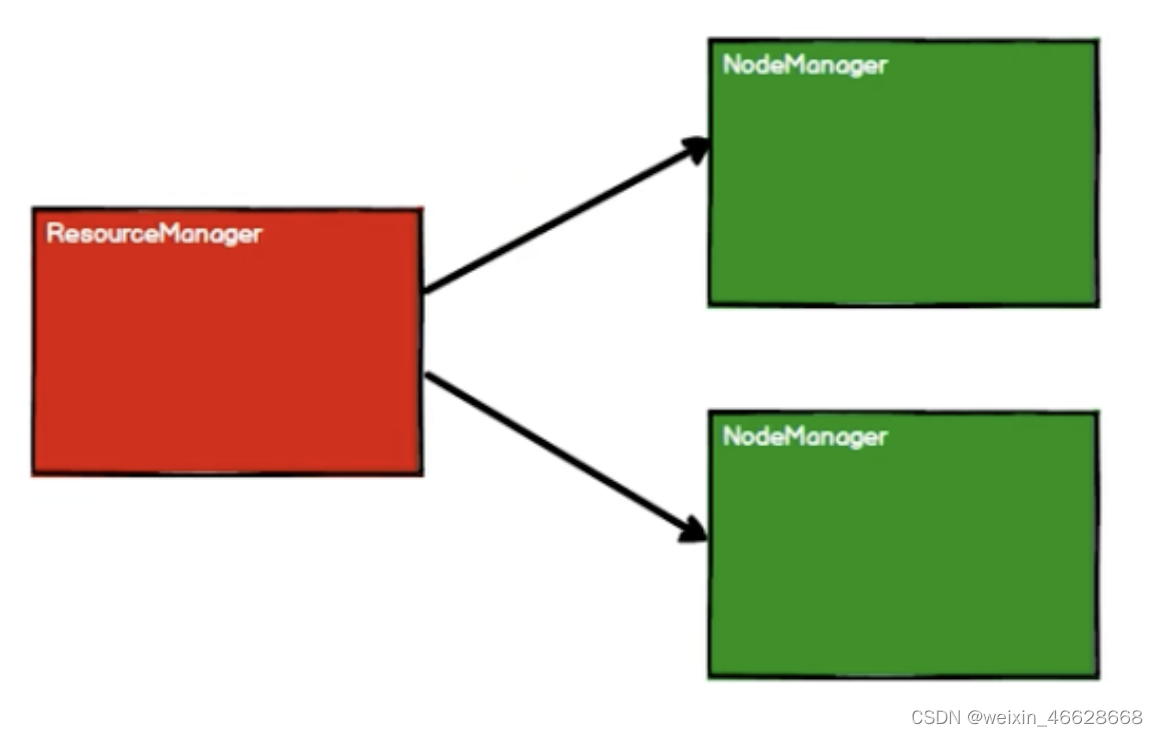
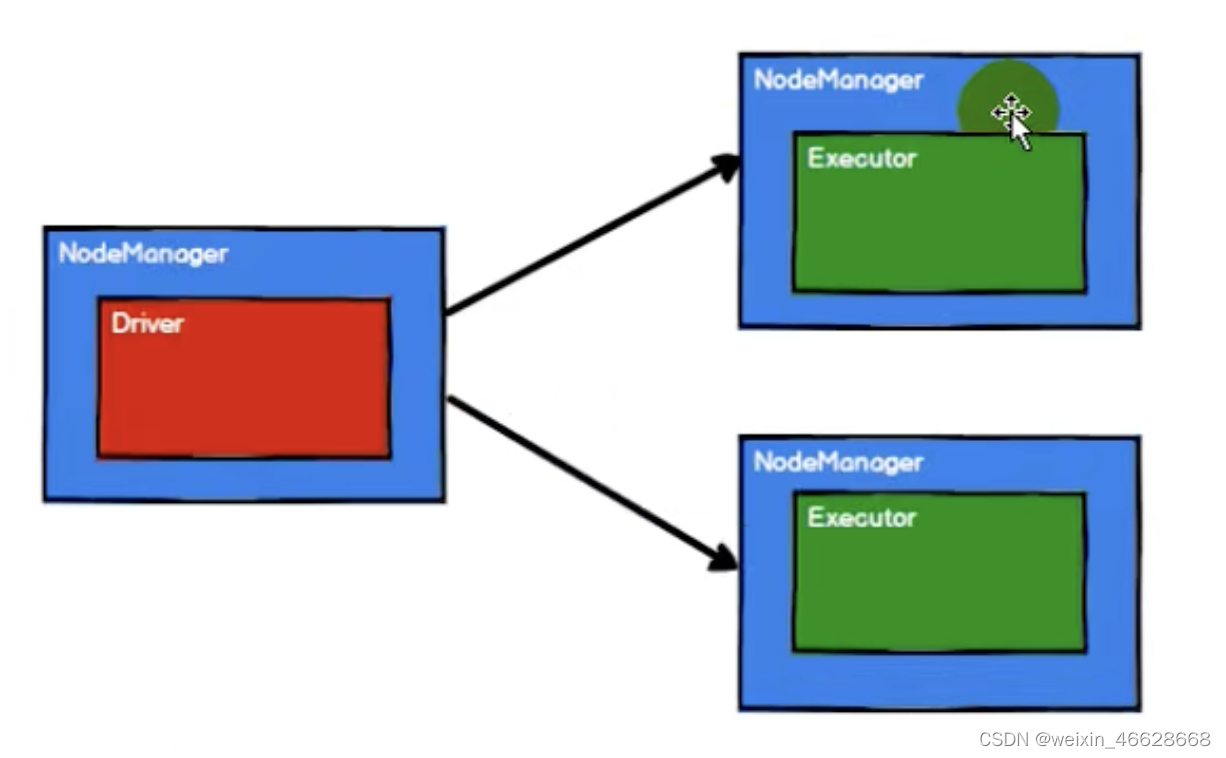
其中,Yarn只是負責資源調度的,而NodeManager中的Driver才是負責任務調度的,而NodeManager中的Executor是負責任務執行的。
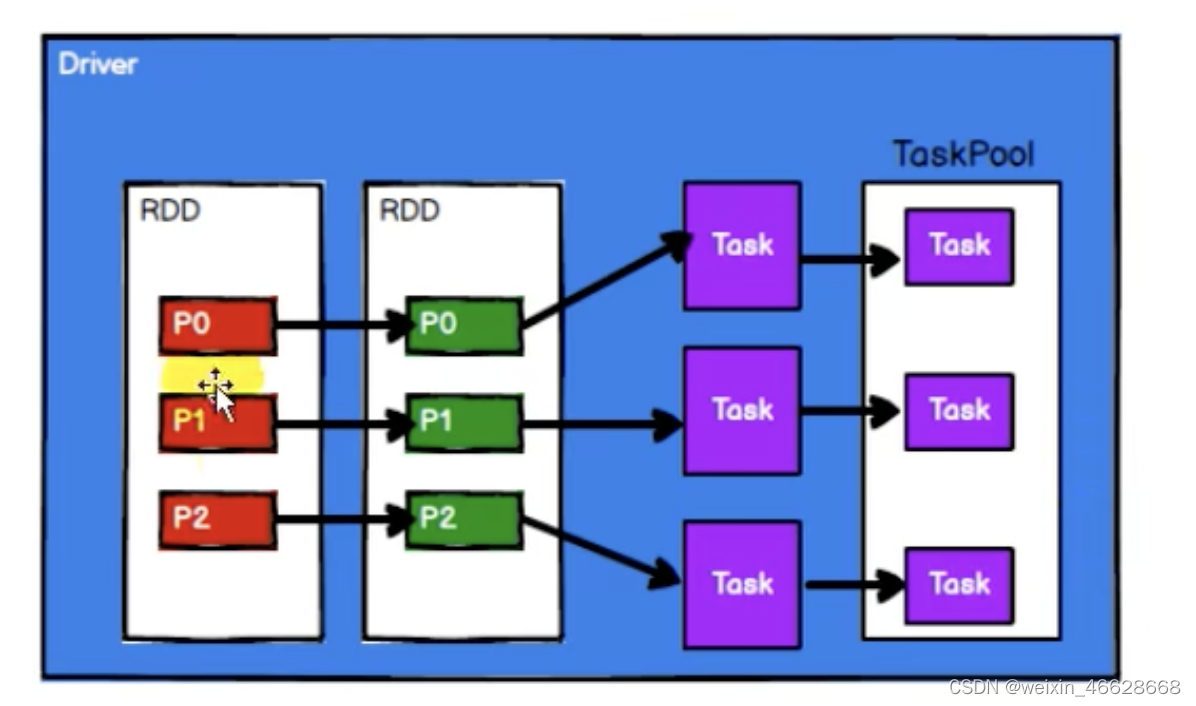
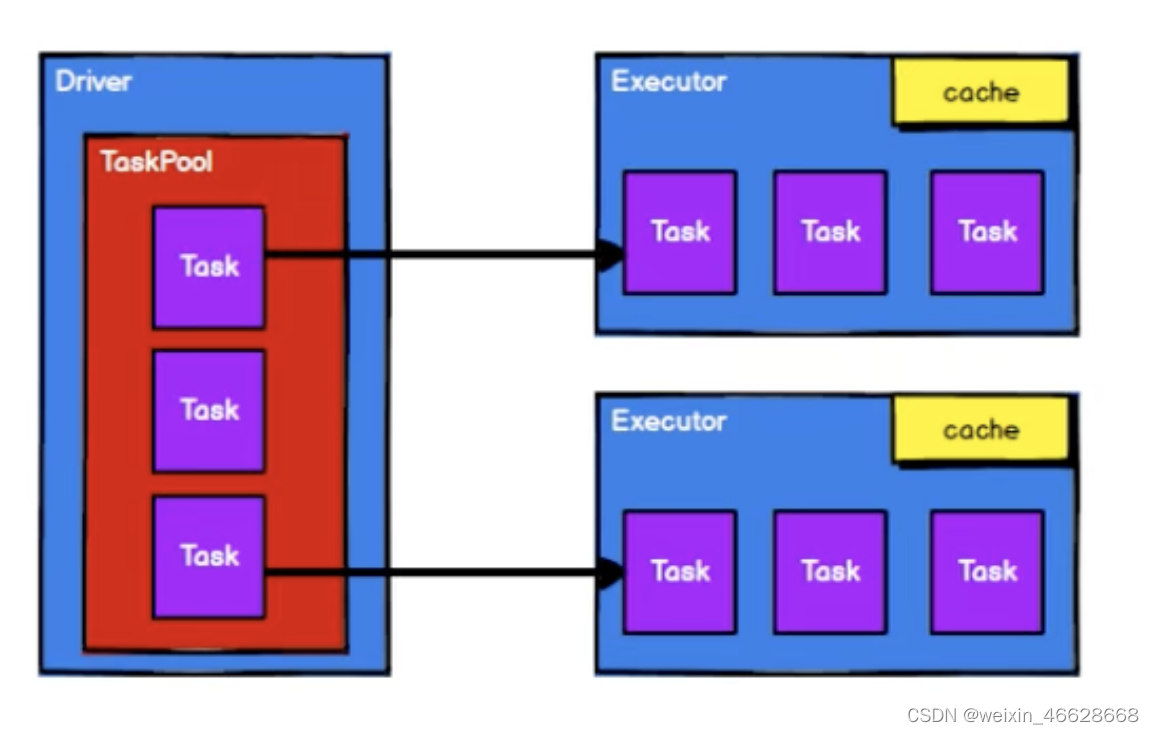
4. 從集合中創建RDD
通過parallelize和makeRDD方法
val sparkConf = new SparkConf.setMaster("local[*]").setAppName("RDD")val sc = new SparkContext(sparkConf)val seq = Seq[Int](1, 2, 3, 4)
// val rdd : RDD[Int] = sc.parallelize(seq)
val rdd : RDD[Int] = sc.makeRDD(seq)rdd.collect().foreach(println)sc.stop()其中local[*]表示使用當前本機的核數,如果不寫[*]就用單核。parallelize和makeRDD方法本質是一樣的,makeRDD方法內部調用了parallelize方法。
makeRDD可以加上第二個參數,表示分區數量,如果不傳,會使用默認值scheduler.conf.getInt("spark.default.parallelism", totalCores),即會從sparkConf中獲取配置參數,如果沒配置,則使用totalCores,即當前環境最大核數。當然,這是針對本地模式的源碼分析。
另外使用saveAsTextFile保存每個分區的文件。
val sparkConf = new SparkConf.setMaster("local[*]").setAppName("RDD")val sc = new SparkContext(sparkConf)val seq = Seq[Int](1, 2, 3, 4)
// val rdd : RDD[Int] = sc.parallelize(seq)
val rdd : RDD[Int] = sc.makeRDD(seq, 2)rdd.saveAsTextFile("output")rdd.collect().foreach(println)sc.stop()結果如下(2個分區):
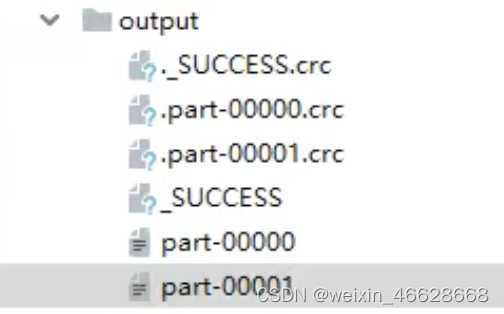
可以設置sparkConf中的分區數量配置參數為5
val sparkConf = new SparkConf.setMaster("local[*]").setAppName("RDD")
sparkConf.set("spark.default.parallelism", "5")val sc = new SparkContext(sparkConf)val seq = Seq[Int](1, 2, 3, 4)
// val rdd : RDD[Int] = sc.parallelize(seq)
val rdd : RDD[Int] = sc.makeRDD(seq)rdd.saveAsTextFile("output")rdd.collect().foreach(println)sc.stop()結果如下
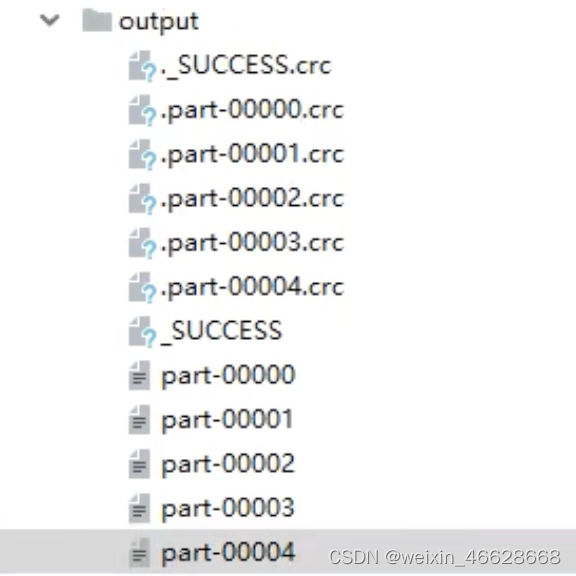 ?
?
分區數據的劃分可以參考
036 RDD-集合數據源-分區數據的分配
5. 從文件中創建RDD
val sparkConf = new SparkConf.setMaster("local[*]").setAppName("RDD")val sc = new SparkContext(sparkConf)val seq = Seq[Int](1, 2, 3, 4)
// val rdd : RDD[Int] = sc.parallelize(seq)
val rdd : RDD[String] = sc.textFile("path")rdd.collect().foreach(println)sc.stop()path可以是文件夾,也可以是文件?,還可以加上通配符*。另外,path可以是分布式文件系統的路徑。這里的textFile是以行為單位進行讀取數據,不考慮數據來自于哪個文件。如果需要考慮數據來源于哪個文件,則需要用到wholeTextFiles方法。
val sparkConf = new SparkConf.setMaster("local[*]").setAppName("RDD")val sc = new SparkContext(sparkConf)val seq = Seq[Int](1, 2, 3, 4)
// val rdd : RDD[Int] = sc.parallelize(seq)
val rdd : RDD[String] = sc.wholeTextFiles("path")rdd.collect().foreach(println)sc.stop()讀取結果形式類似如下:
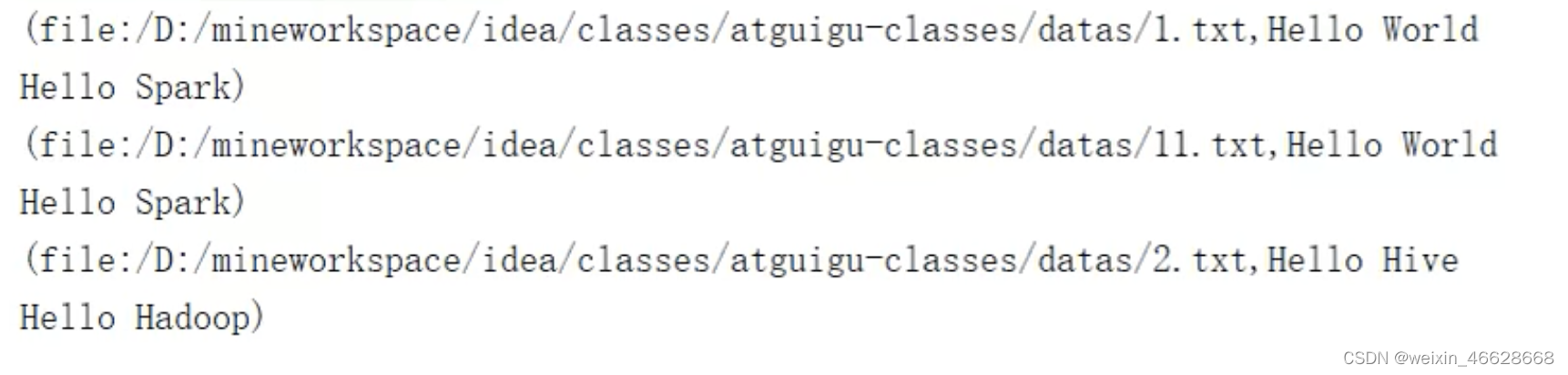
可以看出,是以文件為單位進行讀取,文件全路徑名稱和文件內容以逗號隔開。
textFile也可以通過第二個參數指定分區數量,如果不傳,默認為min(scheduler.conf.getInt("spark.default.parallelism", totalCores), 2),但是第二個參數并不完全是最終分區的數量,這里只是表示最小分區數,實際分區數量可能比這個值要大。實際分區數量怎么計算可以考037 RDD-文件數據源-分區的設定。分區數據的劃分可參考038 RDD-文件數據源-分區數據的分配和039 RDD-文件數據源-分區數據的分配-案例分析???????






)


)









