
論文題目: MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts
論文鏈接:?https://arxiv.org/abs/2401.04081
代碼倉庫:?GitHub - llm-random/llm-random
作為大型語言模型(LLM)基礎架構的后起之秀,狀態空間模型(State Space Models,SSMs)在序列數據建模領域中已取得了驚人的發展。其中Mamba模型改進了傳統的SSM,其通過輸入依賴的方式來調整SSM中的參數,允許模型自適應的根據輸入數據選擇性的傳輸或遺忘信息,來提高模型在密集型數據上的計算效率。與此同時,Mixture of Experts(MoE)框架也顯著改進了基于Transformer的LLM,如何設計更高效的MoE混合策略也成為了LLM研究領域中的潮流方向。
本文介紹一篇來自IDEAS NCBR和華沙大學合作完成的文章,本文作者探索了如何將SSM與MoE結合起來,提出了一種名為MoE-Mamba的框架,MoE-Mamba繼承了SSM序列模型的遞歸計算特性,在推理速度方面相比傳統Transformer具有天然優勢,同時預測精度優于 Mamba 和 Transformer-MoE。特別的是,MoE-Mamba可以在減少訓練steps的情況下達到與普通 Mamba 相同的性能。
01. 引言
SSMs模型相比Transformer具有很多優勢,例如可并行訓練、推理時的線性時間復雜度以及在長上下文任務上的依賴捕獲能力。特別是近期提出的Mamba模型[1],基于選擇性的SSM和硬件感知設計在多種語言理解任務上取得了優異的結果,被學術界廣泛認為是下一個替代注意力Transformer結構的有力競爭者。Mamba對GPU顯存的占用不依賴于上下文長度,因為其反向傳播所需的中間狀態不會被保存,而是在反向傳播期間重新計算,強調了狀態壓縮的重要性。此外,專家混合模型MoE[2]被證明可以有效擴展和提升Transformer模型的性能,其可以大幅增加模型的參數數量,而不會對模型推理和訓練所需的 FLOP 產生太大影響,例如近期開源的Mixtral8×7B [3],性能與LLaMa-2 70B相當,但是推理計算量僅為后者的1/6。
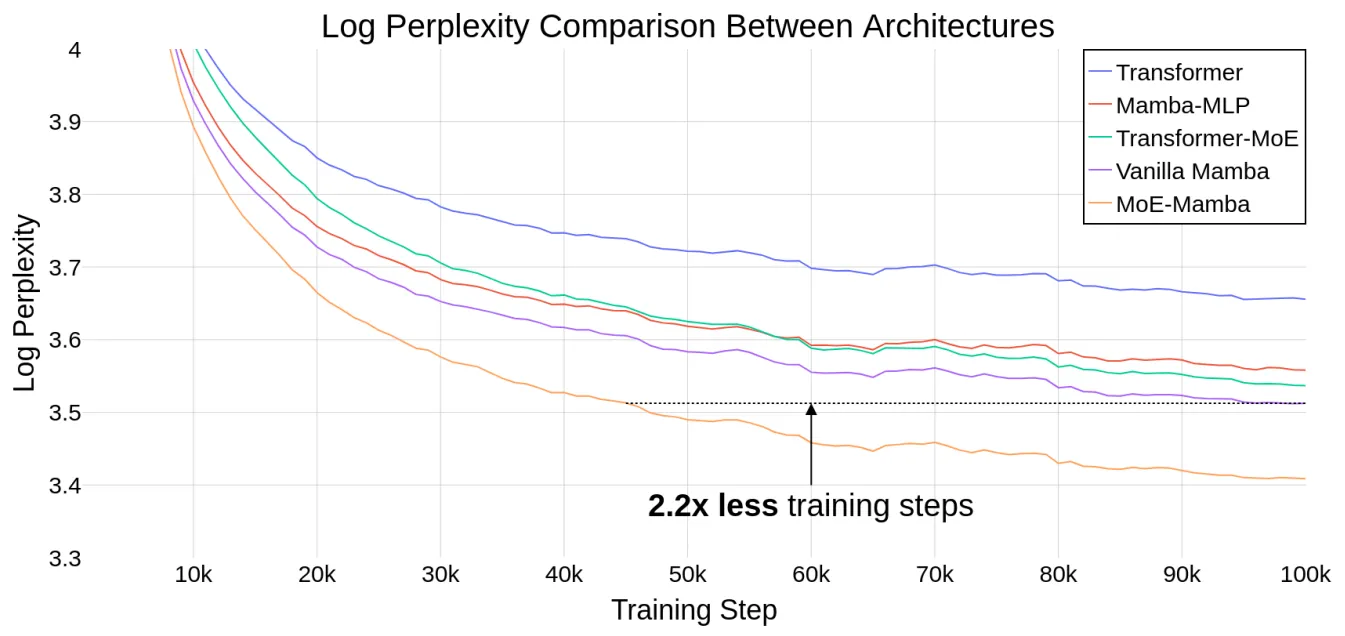
本文引入了一種將Mamba與MoE層相結合的模型MoE-Mamba,MoE-Mamba實現了a+b>c的效果,上圖展示了MoE-Mamba與其他baseline方法的性能對比效果,可以看到,MoE-Mamba可以在普通Mamba的基礎上實現對模型訓練步驟縮減的效果。如上圖黑色虛線所示,MoE-Mamba在減少2.2倍訓練steps的情況下達到了與普通Mamba相同的性能。后續的其他實驗也表明,MoE-Mamba擁有大規模擴展模型參數規模的潛力。
02. 本文方法
盡管 Mamba 的主要底層機制與 Transformer 中使用的注意力機制有很大不同,但 Mamba 仍然保留了 Transformer 模型的層次結構(即塊疊加)。例如包含一層或多層的相同塊依次堆疊,每一層的輸出會被匯聚到殘差信息流中再送入到下一個塊中,殘差流的最終狀態隨后被用于預測語言建模任務中的下一個token。下圖展示了這些架構的細節對比,從左到右分別是vanilla Transformer、MoE-Transformer、Mamba、MoE-Mamba。
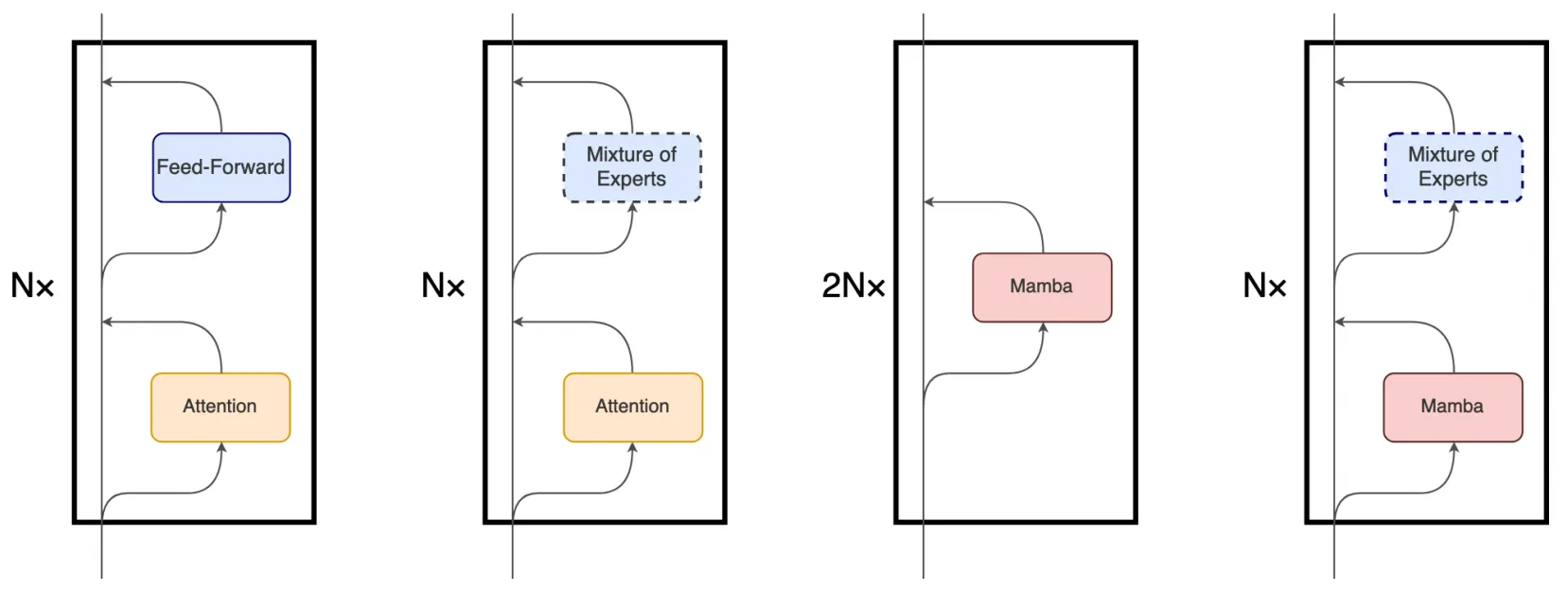
本文提出的MoE-Mamba充分利用了前兩種架構的兼容性,例如,在原有Mamba結構的基礎上仿照MoE-Transformer將兩個mamba塊中的其中一個替換成一個可選擇的MoE塊。這種將mamba層與MoE交錯設置的模式可以有效地將序列的整個上下文集成到mamba塊的內部表示中,從而將其與MoE層的條件處理分開。
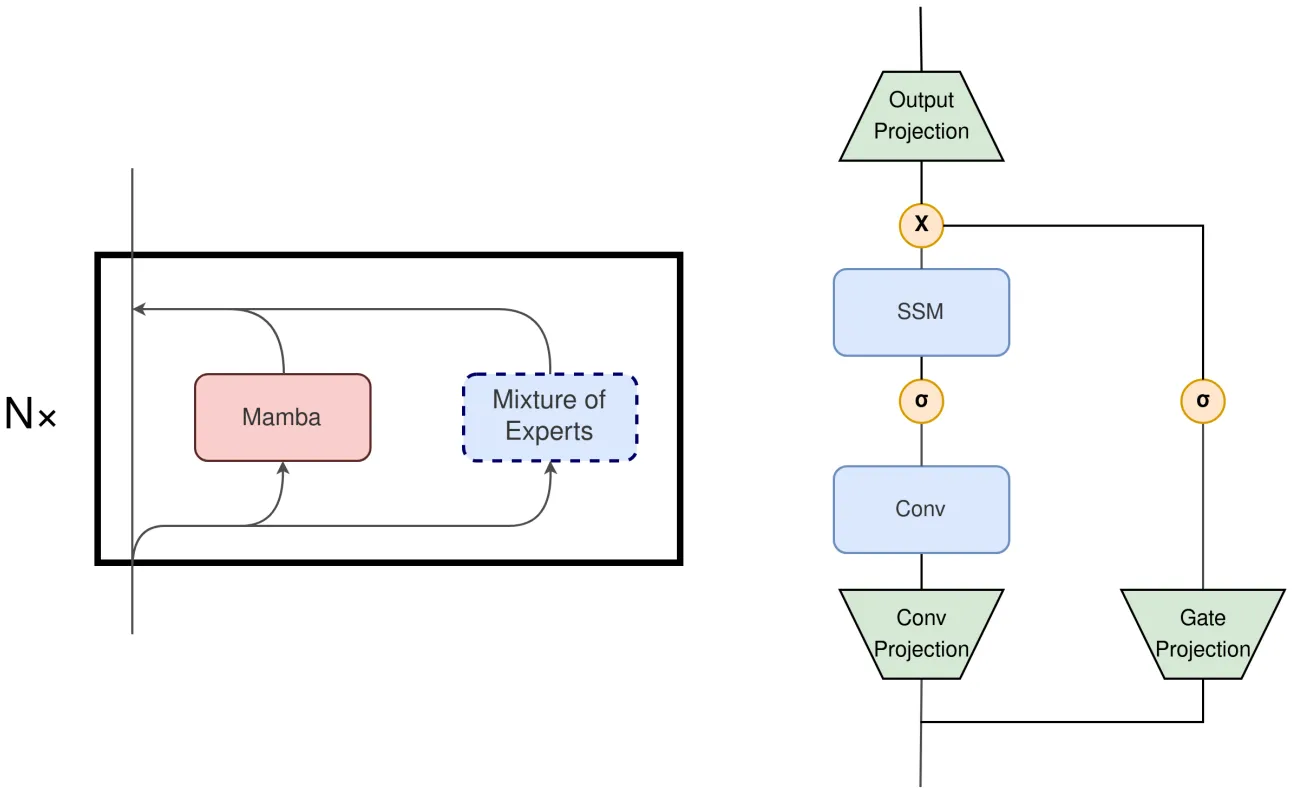
此外,本文作者認為如果將Mamba塊和MoE塊在局部層的范圍內進行并行執行也是一個非常有前景的改進方向,如上圖左側展示了一種并行的Mamba+MoE 架構,右側展示了Mamba Block的構成。如果將Mamba Block中的輸出投影也替換為MoE,模型可以選擇更少的模塊來匹配當前輸入計算的需要,也能實現與原始Mamba架構相當的效果。當然,也可以進一步將MoE替換Conv Projection層來進一步減少計算量。
03. 實驗效果
在本文的實驗部分,作者比較了5種不同的設置:vanilla Transformer、Mamba、Mamba-MLP、MoE 和 MoE-Mamba。為了保證 Mamba 和本文MoE-Mamba模型中每個token的活動參數數量大致相同,作者將每個MoE前饋層的參數量進行了縮減。不包括嵌入層和非嵌入層,所有模型的每個 token 大約需要訪問 26M 個參數,訓練數據集使用C4,整體的訓練量為大約6.5B個token和10萬個訓練steps。
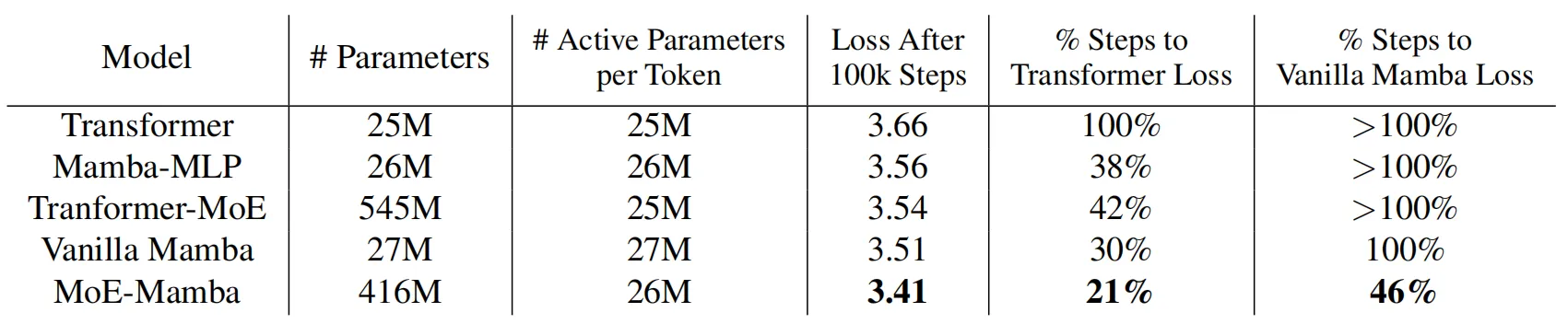
上表展示了上述幾種對比模型的訓練效果,可以看到,MoE-Mamba 比普通 Mamba 模型有了顯著的改進。值得注意的是,MoE-Mamba 只需 46% 的訓練steps即可達到與 vanilla Mamba 相同的性能。
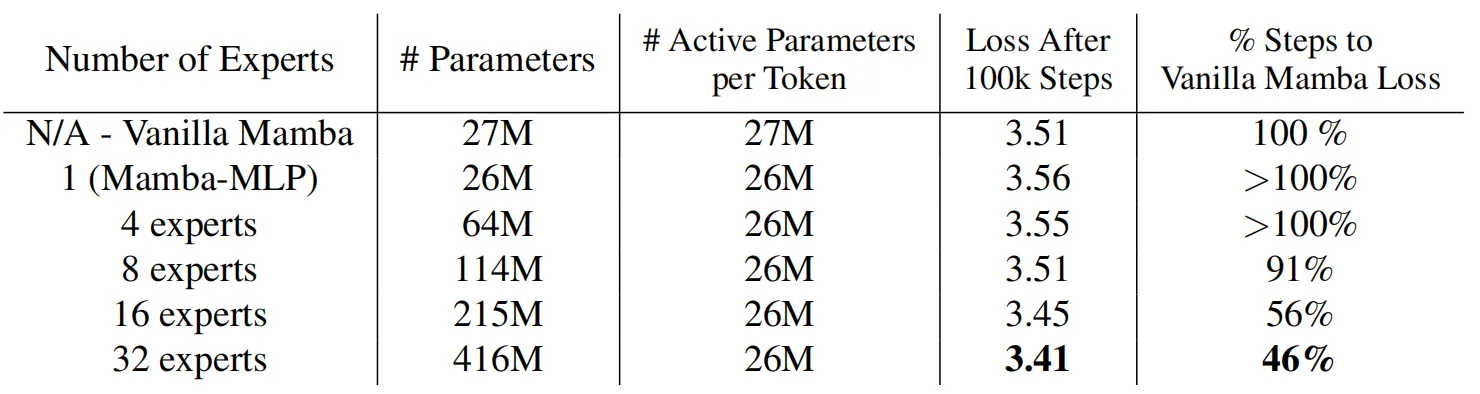
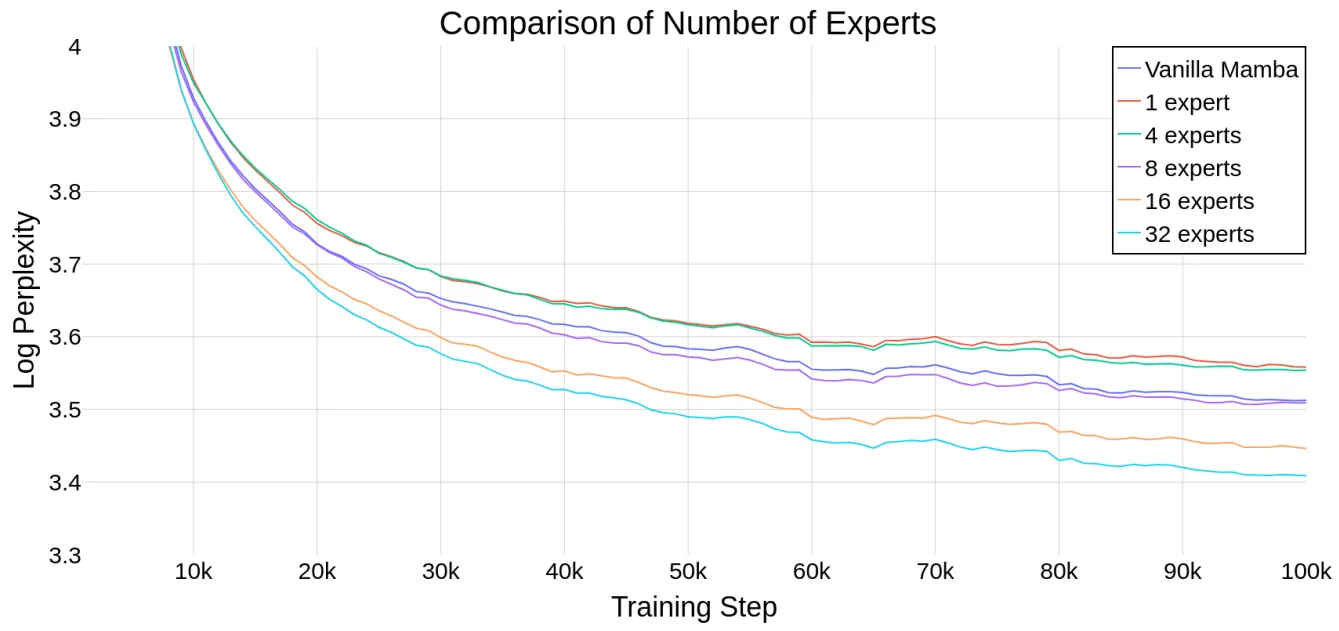
MoE中的專家數量是MoE-Mamba中的一個重要超參數,為了評估Mamba能否隨著專家數量的增加而擴展,作者在下圖繪制了模型在不同專家數量情況下的運行情況,并且加入了Mamba 和 Mamba-MLP(后者相當于具有單個專家的 MoE-Mamba)作為參考。上表展示了模型在10萬訓練steps之后的結果,結果表明,MoE-Mamba可以很好的適應專家數量的變化,如果專家數量設置為8或超過8,MoE-Mamba可以獲得比普通Mamba模型更好的最終性能。
04. 總結
本文提出了一種將專家混合MoE技術與Mamba架構進行集成的模塊,即MoE-Mamba。基于并行計算的天然優勢,Mamba減輕了大模型中復雜循環順序性質的影響,并且對硬件進行感知來實現參數擴展。Mamba相比普通注意力機制Transformer解決了序列模型中效率和有效性之間的基本權衡,強調了狀態壓縮的重要性。將Mamba與高度稀疏的MoE前饋層交錯設置可以實現更高推理效率的LLM,但目前的組合方式仍然非常簡單,作者也探索了一種局部并行的Mamba+MoE架構以實現更高的預測準確率和更稀疏的推理效果。期望后續有更多基于條件計算與狀態空間模型技術相結合的技術出現,作者認為這條道路將能夠更有效地擴展到更大的語言模型中。
參考
[1] Gu A, Dao T. Mamba: Linear-time sequence modeling with selective state spaces[J]. arXiv preprint arXiv:2312.00752, 2023.
[2] Sanseviero, O., Tunstall, L., Schmid, P., Mangrulkar, S., Belkada, Y., and Cuenca, P. Mixture of experts explained, 2023. URL https://huggingface.co/blog/moe.
[3] Mistral. Mixtral of experts, Dec 2023. URL https://mistral.ai/news/mixtral-of-experts/.
??關于TechBeat人工智能社區
▼
TechBeat(www.techbeat.net)隸屬于將門創投,是一個薈聚全球華人AI精英的成長社區。
我們希望為AI人才打造更專業的服務和體驗,加速并陪伴其學習成長。
期待這里可以成為你學習AI前沿知識的高地,分享自己最新工作的沃土,在AI進階之路上的升級打怪的根據地!
更多詳細介紹>>TechBeat,一個薈聚全球華人AI精英的學習成長社區?


















技術的定制化思維鏈提示和定向刺激提示的心理咨詢場景定向ai智能應用)
