寫在前面
通過completion suggester可以實現如下的效果:
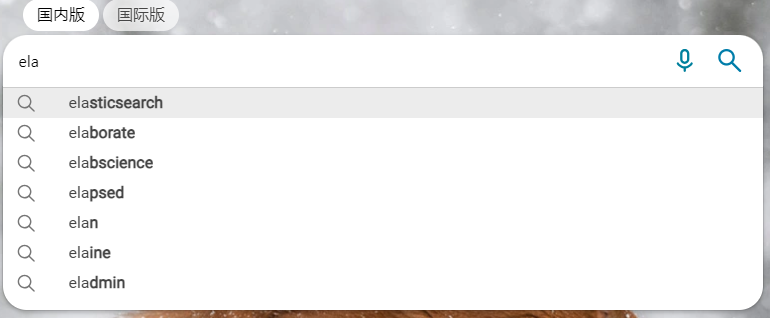
其實就是做的like xxx%這種。通過FST這種數據結構來存儲,實現快速的前綴匹配,并且可以將es所有的數據加載到內存中所以速度completion的查詢速度非常快。
需要注意,如果是某個字段想要使用completion suggester的功能,需要將其類型設置為completion,也就是我們需要顯示的設置mapping來指定。
1:例子
首先來創建索引并指定mapping:
DELETE articlesPUT articles
{"mappings": {"properties": {"title": {"type": "text","fields": {"title_use_completion": {"type": "completion"}}}}}
}
接著插入數據:
POST articles/_bulk
{ "index": {} }
{ "title": "lucene is very cool" }
{ "index": {} }
{ "title": "Elasticsearch builds on top of lucene" }
{ "index": {} }
{ "title": "Elasticsearch rocks" }
{ "index": {} }
{ "title": "elastic is the company behind ELK stack" }
{ "index": {} }
{ "title": "Elk stack rocks" }
查詢:
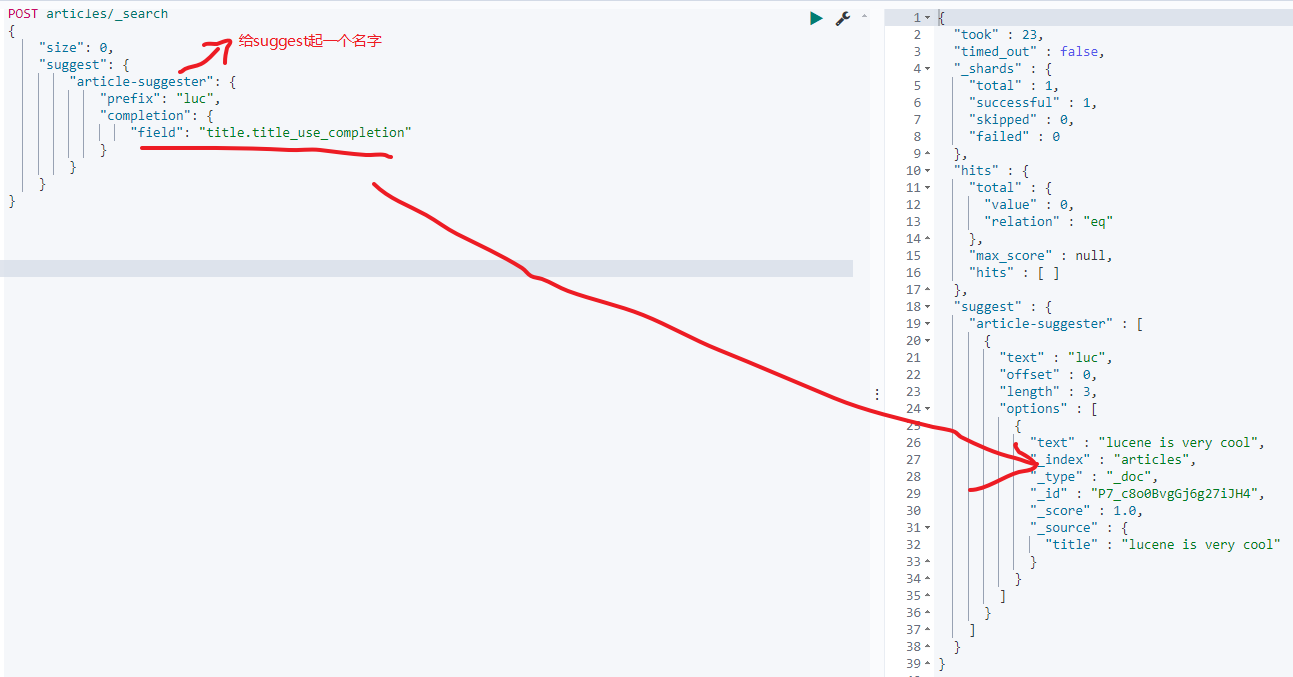
POST articles/_search
{"size": 0,"suggest": {"article-suggester": {"prefix": "luc","completion": {"field": "title.title_use_completion"}}}
}
另外,es還支持一種基于上下文的suggestion,Context Suggerter,如下:

context分為兩類,category和geo,如下:

以context為里來看下。
- 首先來定義mapping
在mapping中指定context的信息:
# 刪除
DELETE comments
# 創建
PUT comments
# 指定mapping
PUT comments/_mapping
{"properties": {"comment_autocomplete": {"type": "completion","contexts": [{"type": "category","name": "comment_category"}]}}
}
數據:
# 錄入數據并指定上下文是movies
POST comments/_doc
{"comment": "I love the star war movies","comment_autocomplete": {"input": ["start wars"],"contexts": {"comment_category": "movies"}}
}# 錄入數據并指定上下文是coffee
POST comments/_doc
{"comment": "Where can I find a Starbucks","comment_autocomplete": {"input": ["starbucks"],"contexts": {"comment_category": "coffee"}}
}
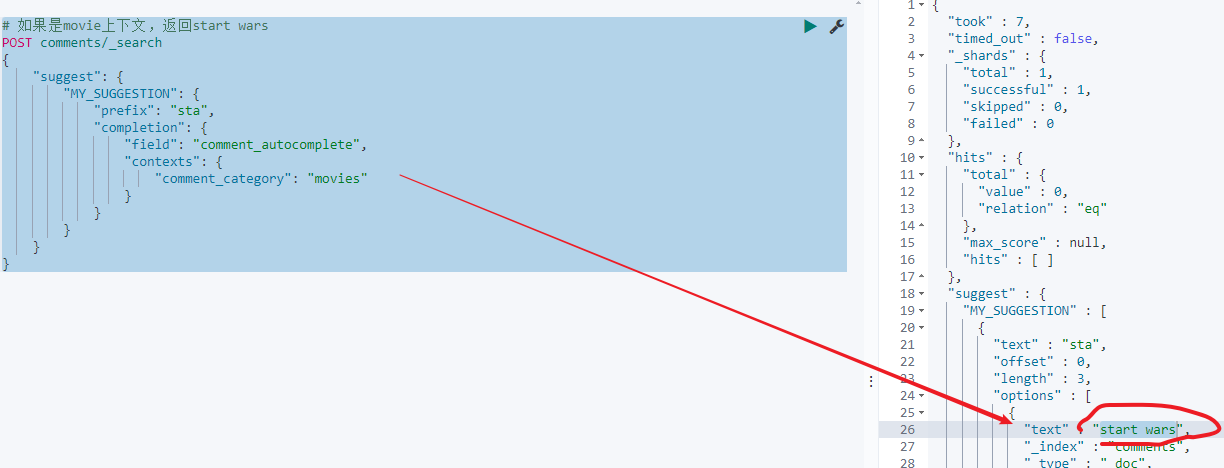
movies上下文查詢:
# 如果是movie上下文,返回start wars
POST comments/_search
{"suggest": {"MY_SUGGESTION": {"prefix": "sta","completion": {"field": "comment_autocomplete","contexts": {"comment_category": "movies"}}}}
}
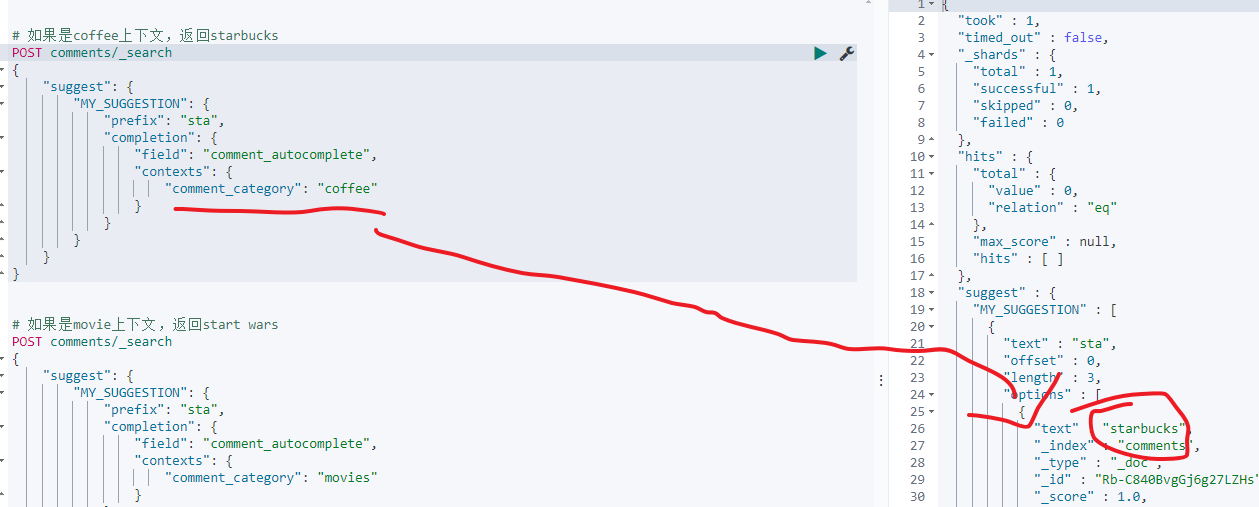
coffee上下文查詢:
# 如果是coffee上下文,返回starbucks
POST comments/_search
{"suggest": {"MY_SUGGESTION": {"prefix": "sta","completion": {"field": "comment_autocomplete","contexts": {"comment_category": "coffee"}}}}
}
最后看下term,phrase,completion三者的對比:

寫在后面
參考文章列表
倒排索引:ES倒排索引底層原理及FST算法的實現過程 。


)


)








 安裝以及配置環境)


)

