一、基礎概念
1. MVCC的含義
MVCC (Multiversion Concurrency Control),即多版本并發控制技術,它是通過讀取某個時間點的快照數據, 來降低并發事務沖突而引起的鎖等待, 從而提高并發性能的一種機制.
MVCC 的實現,是通過保存數據在某個時間點的快照來實現的。也就是說,不管需要執行多長時間,每個事務看到的數據都是一致的。
根據事務開始的時間不同,每個事務對同一張表,同一時刻看到的數據可能是不一樣的。
MVCC只在 READ COMMITTED 和 REPEATABLE READ 兩個隔離級別下工作。其他兩個隔離級別夠和MVCC不兼容.
因為 READ UNCOMMITTED 總是讀取最新的數據行, 而不是符合當前事務版本的數據行。
而 SERIALIZABLE 則會對所有讀取的行都加鎖。
讀取數據時通過一種類似快照的方式將數據保存下來,這樣讀鎖就和寫鎖不沖突了,不同的事務session會看到自己特定版本的數據版本鏈,它使得大部分支持行鎖的事務引擎,不再單純的使用行鎖來進行數據庫的并發控制,取而代之的是把數據庫的行鎖與行的多個版本結合起來,只需要很小的開銷,就可以實現非鎖定讀,從而大大提高數據庫系統的并發性能。
自己理解:就是用版本號而不是鎖,已達到并發下的讀寫。
2. MVCC的意義
這樣設計使得讀數據操作很簡單,性能很好,并且也能保證只會讀取到符合標準的行。
不足之處是每行記錄都需要額外的存儲空間,需要做更多的行檢查工作,以及一些額外的維護工作。
MVCC是事務隔離性的底層實現原理
那么讀提交和可重復讀的底層MVCC有何實現差異?
讀提交的邏輯和可重復讀的邏輯類似,它們最主要的區別是:
- 在可重復讀隔離級別下,只需要在事務開始的時候創建一致性視圖,之后當前事務里的其他查詢都共用這個一致性視圖;
- 在讀提交隔離級別下,每一個語句執行前都會重新算出一個新的視圖
可重復讀的核心就是一致性讀(consistent read);而事務更新數據的時候,只能用當前讀。如果當前的記錄的行鎖被其他事務占用的話,就需要進入鎖等待。? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
二.實現原理
在可重復讀隔離級別下,事務在啟動的時候就“拍了個快照”。注意,這個快照是基于整庫的。
InnoDB的MVCC,是通過在每行記錄后面保存兩個隱藏的列來實現的。
每開始一個新的事務,系統版本號都會自動遞增。事務開始時刻的系統版本號會作為事務的版本號,用來和查詢到的每行記錄的版本號進行比較。下面看一下在 REPEATABLEREAD 隔離級別下,MVCC具體是如何操作的。
SELECT
InnoDB會根據以下兩個條件檢查每行記錄:
????????a.InnoDB 只查找版本早于當前事務版本的數據行(也就是,行的系統版本號小于或等于事務的系統版本號),這樣可以確保事務讀取的行,要么是在事務開始前已經存在的,要么是事務自身插人或者修改過的。
????????b,行的刪除版本要么未定義,要么大于當前事務版本號。這可以確保事務讀取到的行,在事務開始之前未被刪除。
只有符合上述兩個條件的記錄,才能返回作為查詢結果INSERT
InnoDB 為新插人的每一行保存當前系統版本號作為行版本號DELETE
InnoDB 為刪除的每一行保存當前系統版本號作為行刪除標識。UPDATE
InnoDB 為插入一行新記錄,保存當前系統版本號作為行版本號,同時保存當前系統版本號到原來的行作為行刪除標識。
保存這兩個額外系統版本號,使大多數讀操作都可以不用加鎖。
?
1.聚簇索引隱藏列
在數據庫表的記錄中,每一個記錄都會添加三個字段:
- DB_TRX_ID:6個字節,表示當前修改本記錄的事務ID
- DB_ROLL_PTR :7 個字節,回滾指針,指向回滾段中的 undo log record,用于找出這個記錄的上個版本修改的數據。
- DB_ROW_ID:6 個字節,一個單調遞增的 ID,確定表中記錄的唯一性。
每行數據也都是有多個版本的,每次事務更新數據的時候,都會生成一個新的數據版本,并且把 transaction id 賦值給這個數據版本的事務 ID,記為 row trx_id。同時,舊的數據版本要保留,并且在新的數據版本中,能夠有信息可以直接拿到它。
也就是說,數據表中的一行記錄,其實可能有多個版本 (row),每個版本有自己的 row trx_id。
如圖 2 所示,就是一個記錄被多個事務連續更新后的狀態。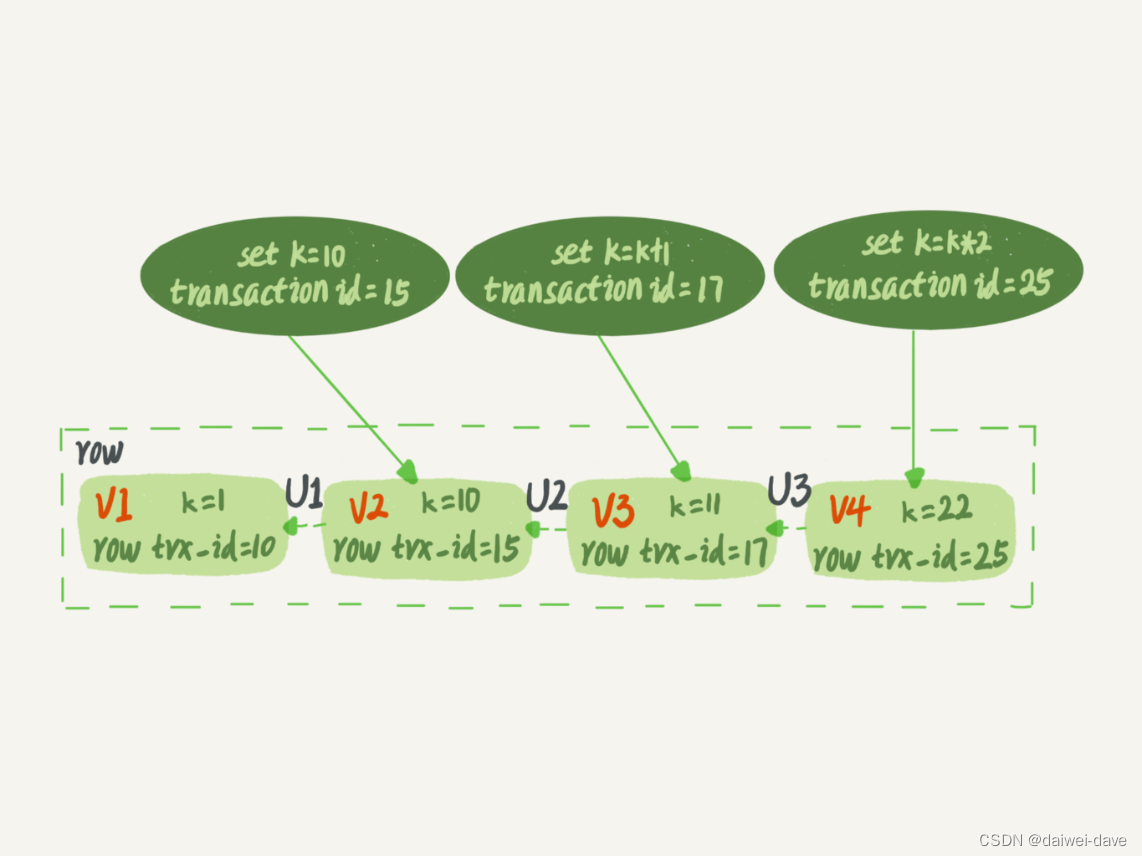
圖 2 行狀態變更圖
圖中虛線框里是同一行數據的 4 個版本,當前最新版本是 V4,k 的值是 22,它是被 transaction id 為 25 的事務更新的,因此它的 row trx_id 也是 25。
你可能會問,前面的文章不是說,語句更新會生成 undo log(回滾日志)嗎?那么,undo log 在哪呢?
實際上,圖 2 中的三個虛線箭頭,就是 undo log;而 V1、V2、V3 并不是物理上真實存在的,而是每次需要的時候根據當前版本和 undo log 計算出來的。比如,需要 V2 的時候,就是通過 V4 依次執行 U3、U2 算出來。
2.一致性視圖(read-view)
按照可重復讀的定義,一個事務啟動的時候,能夠看到所有已經提交的事務結果。但是之后,這個事務執行期間,其他事務的更新對它不可見。
因此,一個事務只需要在啟動的時候聲明說,“以我啟動的時刻為準,如果一個數據版本是在我啟動之前生成的,就認;如果是我啟動以后才生成的,我就不認,我必須要找到它的上一個版本”。
當然,如果“上一個版本”也不可見,那就得繼續往前找。還有,如果是這個事務自己更新的數據,它自己還是要認的。
在實現上, InnoDB 為每個事務構造了一個數組,用來保存這個事務啟動瞬間,當前正在“活躍”的所有事務 ID。
“活躍”指的就是,啟動了但還沒提交。
數組里面事務 ID 的最小值記為低水位,當前系統里面已經創建過的事務 ID 的最大值加 1 記為高水位。
這個視圖數組和高水位,就組成了當前事務的一致性視圖(read-view)
而數據版本的可見性規則,就是基于數據的 row trx_id 和這個一致性視圖的對比結果得到的。這個視圖數組把所有的 row trx_id 分成了幾種不同的情況。
這樣,對于當前事務的啟動瞬間來說,一個數據版本的 row trx_id,有以下幾種可能:
- 如果落在綠色部分,表示這個版本是已提交的事務或者是當前事務自己生成的,這個數據是可見的;
- 如果落在紅色部分,表示這個版本是由將來啟動的事務生成的,是肯定不可見的;
- 如果落在黃色部分,就需要版本對比了。
那就包括兩種情況
a. 若 row trx_id 在數組中,表示這個版本是由還沒提交的事務生成的,不可見;但如果當前是自己的事務,是可見的。
b. 若row trx_id 不在數組中,表示這個版本是已經提交了的事務生成的,可見。(一致性視圖再rm級別下是會更新變化的,也只有rm級別才會這種場景)
3.一致性讀(consistent read)
又稱快照讀,讀取的是undo log中的數據,可能是數據的歷史版本,no-locking,所以是非阻塞的讀取操作,對應為一般的select 語句。
4.當前讀(current read)
讀取的是記錄的最新版本,可能是其他事務提交后的值, 加鎖保證事務隔離性。
主要發生在update 語句,除了 update 語句外,select 語句如果加鎖,也是當前讀。
而對于一般的查詢語句則使用的是一致性讀,即不會讀到其他事務提交后的值。
?5. 數據庫行紀錄的更新底層機制
1.初始數據行
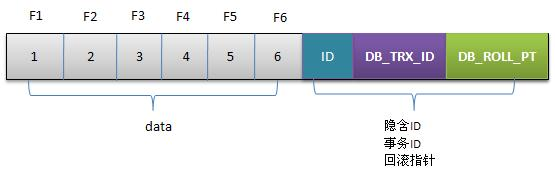
F1~F6是某行列的名字,1~6是其對應的數據。后面三個隱含字段分別對應該行的事務號和回滾指針,假如這條數據是剛INSERT的,可以認為ID為1,其他兩個字段為空。
2.事務1更改該行的各字段的值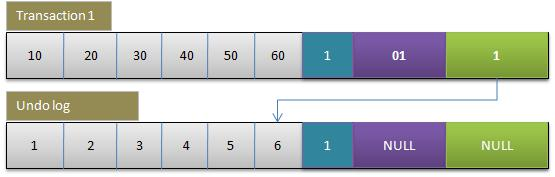
當事務1更改該行的值時,會進行如下操作:
- 用排他鎖鎖定該行
- 記錄redo log
- 把該行修改前的值Copy到undo log,即上圖中下面的行
- 修改當前行的值,填寫事務編號,使回滾指針指向undo log中的修改前的行
3.事務2修改該行的值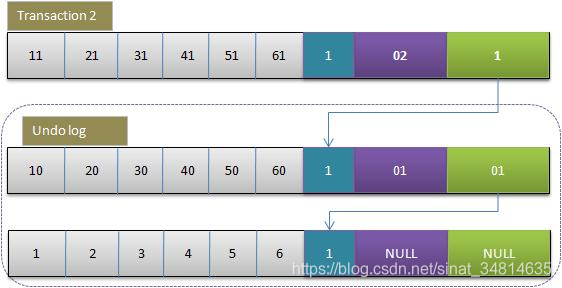
與事務1相同,此時undo log,中有有兩行記錄,并且通過回滾指針連在一起。
因此,如果undo log一直不刪除,則會通過當前記錄的回滾指針回溯到該行創建時的初始內容。
所幸的時在Innodb中存在purge線程,它會查詢那些比現在最老的活動事務(即還未提交的事務)還早的undo log,并刪除它們,從而保證undo log文件不至于無限增長。
即事務一旦提交了,所對應的undo log文件就失去了存在的意義
6. 刪除的底層實現機制
將所在行的數據復制一份,然后將事務ID更新為刪除操作的事務ID。并將新的事務ID的頭信息record header里的刪除標示delete_flag標記置為true,當讀起的時候會檢查頭信息,如果標記為true,則不返回對應的數據。
可見數據庫底層操作也是類似邏輯刪除。
三.實戰分析
1.場景一
我給你舉一個例子吧。下面是一個只有兩行的表的初始化語句。
mysql> CREATE TABLE `t` (`id` int(11) NOT NULL,`k` int(11) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t(id, k) values(1,1),(2,2);
三個并發事務執行順序如下
在這個例子中,事務 C 沒有顯式地使用 begin/commit,表示這個 update 語句本身就是一個事務,語句完成的時候會自動提交。事務 B 在更新了行之后查詢 ; 事務 A 在一個只讀事務中查詢,并且時間順序上是在事務 B 的查詢之后。
這里,我們不妨做如下假設:
1.事務 A 開始前,系統里面只有一個活躍事務 ID 是 99;
2.事務 A、B、C 的版本號分別是 100、101、102,且當前系統里只有這四個事務;
3.三個事務開始前,(1,1)這一行數據的 row trx_id 是 90。
這樣,事務 A 的視圖數組就是 [99,100], 事務 B 的視圖數組是 [99,100,101], 事務 C 的視圖數組是 [99,100,101,102]。
在可重復讀隔離級別下
為了簡化分析,我先把其他干擾語句去掉,只畫出跟事務 A 查詢邏輯有關的操作:
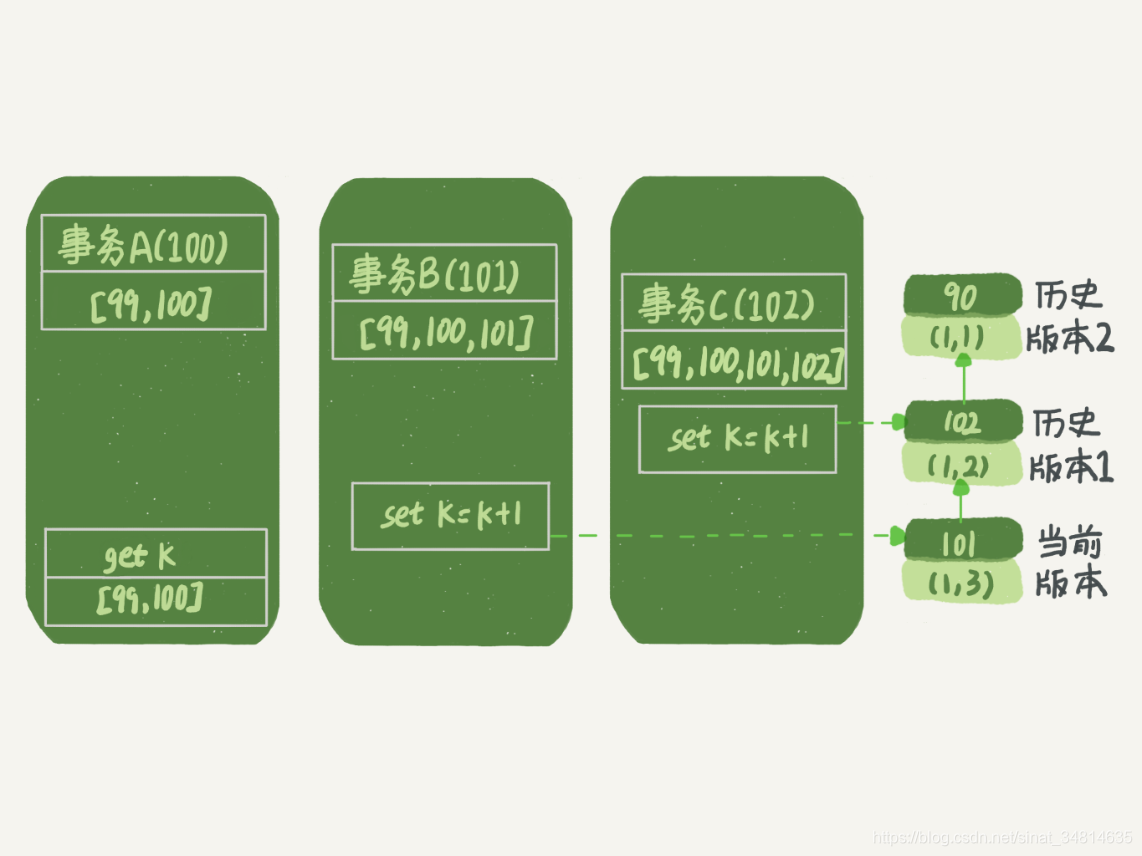
圖 4 事務 A 查詢數據邏輯圖
從圖中可以看到,第一個有效更新是事務 C,把數據從 (1,1) 改成了 (1,2)。這時候,這個數據的最新版本的 row trx_id 是 102,而 90 這個版本已經成為了歷史版本。
第二個有效更新是事務 B,把數據從 (1,2) 改成了 (1,3)。這時候,這個數據的最新版本(即 row trx_id)是 101,而 102 又成為了歷史版本。
你可能注意到了,在事務 A 查詢的時候,其實事務 B 還沒有提交,但是它生成的 (1,3) 這個版本已經變成當前版本了。但這個版本對事務 A 必須是不可見的,否則就變成臟讀了。
好,現在事務 A 要來讀數據了,它的視圖數組是 [99,100]。那么此時事務A的低水位為99,高水位為90+1=91.
當然了,讀數據都是從當前版本讀起的。所以,事務 A 查詢語句的讀數據流程是這樣的:
- 找到 (1,3) 的時候,判斷出 row trx_id=101,比高水位大(開啟一致性視圖開啟的事務),處于紅色區域,不可見;
- 接著,找到上一個歷史版本,一看 row trx_id=102,比高水位大(開啟一致性視圖開啟的事務),處于紅色區域,不可見;
- 再往前找,終于找到了(1,1),它的 row trx_id=90,比低水位小,處于綠色區域,可見。
這樣執行下來,雖然期間這一行數據被修改過,但是事務 A 不論在什么時候查詢,看到這行數據的結果都是一致的,所以我們稱之為一致性讀。
這個判斷規則是從代碼邏輯直接轉譯過來的,但是正如你所見,用于人肉分析可見性很麻煩。
所以,我來給你翻譯一下。一個數據版本,對于一個事務視圖來說,除了自己的更新總是可見以外,有三種情況:
版本未提交,不可見;
版本已提交,但是是在視圖創建后提交的,不可見;
版本已提交,而且是在視圖創建前提交的,可見。
現在,我們用這個規則來判斷圖 4 中的查詢結果,事務 A 的查詢語句的視圖數組是在事務 A 啟動的時候生成的,這時候:
(1,3) 還沒提交,屬于情況 1,不可見;
(1,2) 雖然提交了,但是是在視圖數組創建之后提交的,屬于情況 2,不可見;
(1,1) 是在視圖數組創建之前提交的,可見。
你看,去掉數字對比后,只用時間先后順序來判斷,分析起來是不是輕松多了。
所以,后面我們就都用這個規則來分析。
事務 B的查詢
事務 B 的視圖數組是 [99,100,101],低水位是99,高水位為90+1=91
事務 B在更新后的查詢語句的讀數據流程是這樣的():
找到 (1,3) 的時候,判斷出 row trx_id=101,發現是自己的事務ID,則可見,顧查詢的值為3。
細心的同學可能有疑問了:事務 B 的 update 語句,如果按照一致性讀,好像結果不對哦?
你看圖 5 中,事務 B 的視圖數組是先生成的,之后事務 C 才提交,不是應該看不見 (1,2) 嗎,怎么能算出 (1,3) 來?
是的,如果事務 B 在更新之前查詢一次數據,這個查詢返回的 k 的值確實是 1。
但是,當它要去更新數據的時候,就不能再在歷史版本上更新了,否則事務 C 的更新就丟失了。因此,事務 B 此時的 set k=k+1 是在(1,2)的基礎上進行的操作。
所以,這里就用到了這樣一條規則:更新數據都是先讀后寫的,而這個讀,只能讀當前的值,稱為“當前讀”(current read)。
因此,在更新的時候,當前讀拿到的數據是 (1,2),更新后生成了新版本的數據 (1,3),這個新版本的 row trx_id 是 101。
所以,在執行事務 B 查詢語句的時候,一看自己的版本號是 101,最新數據的版本號也是 101,是自己的更新,可以直接使用,所以查詢得到的 k 的值是 3。
這里我們提到了一個概念,叫作當前讀。其實,除了 update 語句外,select 語句如果加鎖,也是當前讀。
所以,如果把事務 A 的查詢語句 select * from t where id=1 修改一下,加上 lock in share mode 或 for update,也都可以讀到版本號是 101 的數據,返回的 k 的值是 3。下面這兩個 select 語句,就是分別加了讀鎖(S 鎖,共享鎖)和寫鎖(X 鎖,排他鎖)。
mysql> select k from t where id=1 lock in share mode;
mysql> select k from t where id=1 for update;
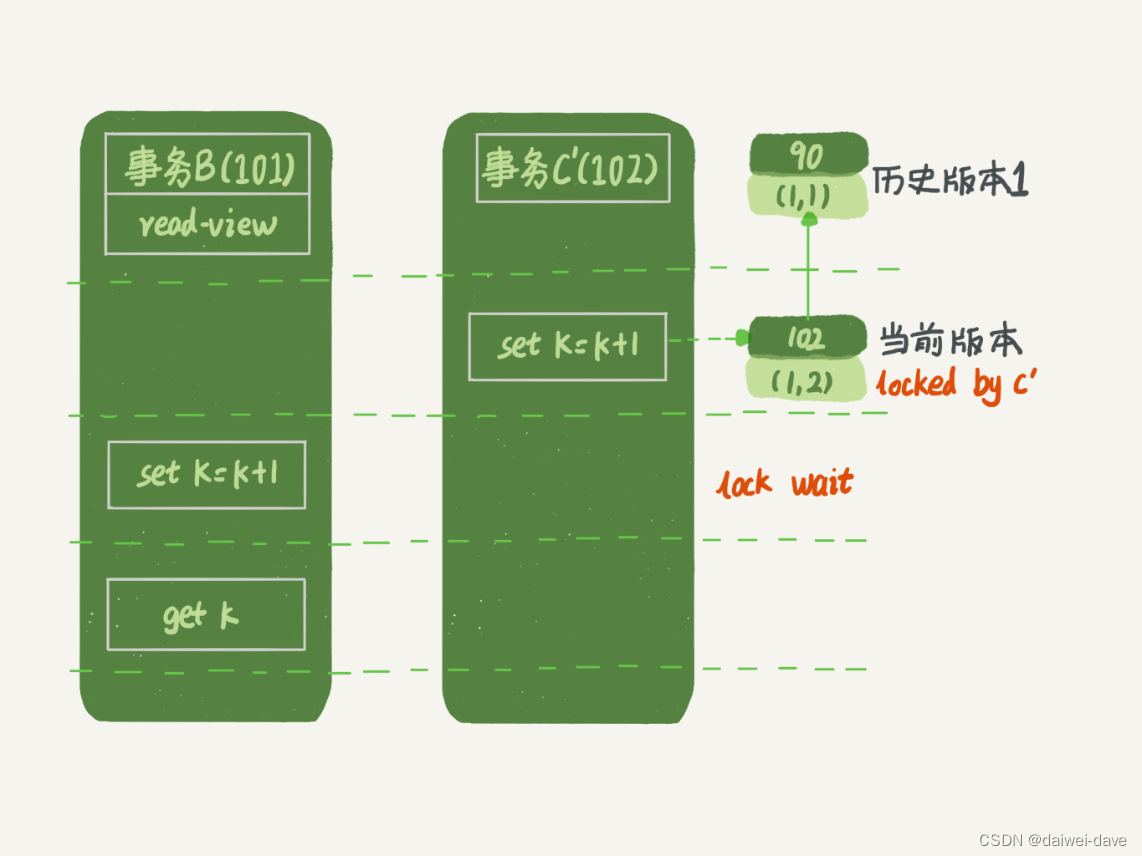
再往前一步,假設事務 C 不是馬上提交的,而是變成了下面的事務 C’,會怎么樣呢?

圖 6 事務 A、B、C’的執行流程
事務 C’的不同是,更新后并沒有馬上提交,在它提交前,事務 B 的更新語句先發起了。前面說過了,雖然事務 C’還沒提交,但是 (1,2) 這個版本也已經生成了,并且是當前的最新版本。那么,事務 B 的更新語句會怎么處理呢?
這時候,我們在之前提到的“兩階段鎖協議”就要上場了。
事務 C’沒提交,也就是說 (1,2) 這個版本上的寫鎖還沒釋放。而事務 B 是當前讀,必須要讀最新版本,而且必須加鎖,因此就被鎖住了,必須等到事務 C’釋放這個鎖,才能繼續它的當前讀。
到這里,我們把一致性讀、當前讀和行鎖就串起來了。
事務 C的查詢
事務 C 的視圖數組是 [99,100,101,102]。低水位是99,高水位為90+1=91.
事務 C查詢語句的讀數據流程是這樣的:
找到 (1,3) 的時候,判斷出 row trx_id=101,大于高水位,不可見。
然后查上一版本,判斷row trx_id=102,發現是自己的事務ID,可見。估事務 C查詢語句得到的值是2.
那么,我們再看一下,在讀提交隔離級別下,事務 A 和事務 B 的查詢語句查到的 k,分別應該是多少呢?
在讀提交時隔離級別下
下面是讀提交時的狀態圖,可以看到這兩個查詢語句的創建視圖數組的時機發生了變化,就是圖中的 read view 框。(注意:這里,我們用的還是事務 C 的邏輯直接提交,而不是事務 C’)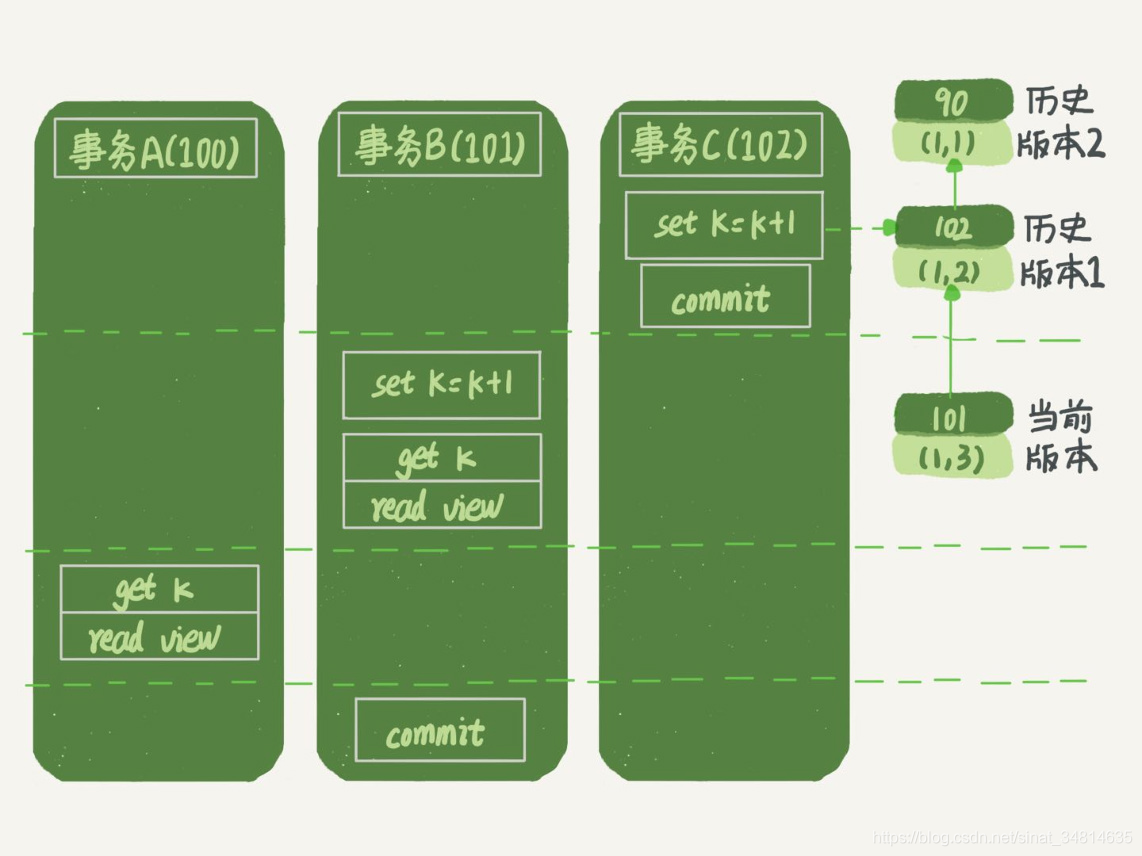
這時,事務 A 的查詢語句的視圖數組是在執行這個語句的時候創建的,時序上 (1,2)、(1,3) 的生成時間都在創建這個視圖數組的時刻之前。但是,在這個時刻:
- (1,3) 還沒提交,屬于情況 1,不可見;
- (1,2) 提交了,屬于情況 3,可見。
所以,這時候事務 A 查詢語句返回的是 k=2。
顯然地,事務 B 查詢結果 k=3。
那么如果用一致性視圖的讀取規則來計算的話
事務A查詢語句的視圖為:[100,101] ,低水位是100,此時已提交的事務信息事務ID是102,所以高水位是102+1=103。
讀起規則:
首先101小于103,且在未提交事務數組中,不可見。然后102小于103,且不在未提交事務數組中,可見。
事務B查詢語句的視圖為:[100,101] 此時A未提交事務,C已提交事務。所以低水位是100,高水位是102+1=103。
讀起規則:
首先101是當前事務ID,可見。事務 B 查詢結果 k=3。
事務C查詢語句的視圖為:[100,101,102] ,此時A,B,C都未提交事務,所以低水位是100,高水位是90+1=91。并且事務C查詢的時候,還沒有執行事務B101的更新語句.
讀起規則:
首先102是當前事務ID,可見。事務C 查詢結果 k=2。
2.場景二
我們創建了一個簡單的表 t,并插入一行,然后對這一行做修改。
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL primary key auto_increment,
`a` int(11) DEFAULT NULL
) ENGINE=InnoDB;
insert into t values(1,2);這時候,表 t 里有唯一的一行數據 (1,2)。假設,我現在要執行:
|
|
你會看到這樣的結果:

結果顯示,匹配 (rows matched) 了一行,修改 (Changed) 了 0 行。
僅從現象上看,MySQL 內部在處理這個命令的時候,可以有以下三種選擇:
-
更新都是先讀后寫的,MySQL 讀出數據,發現 a 的值本來就是 2,不更新,直接返回,執行結束;
-
MySQL 調用了 InnoDB 引擎提供的“修改為 (1,2)”這個接口,但是引擎發現值與原來相同,不更新,直接返回;
-
InnoDB 認真執行了“把這個值修改成 (1,2)"這個操作,該加鎖的加鎖,該更新的更新。
你覺得實際情況會是以上哪種呢?你可否用構造實驗的方式,來證明你的結論?進一步地,可以思考一下,MySQL 為什么要選擇這種策略呢?
第一個選項是,MySQL 讀出數據,發現值與原來相同,不更新,直接返回,執行結束。這里我們可以用一個鎖實驗來確認。
假設,當前表 t 里的值是 (1,2)。

圖 12 鎖驗證方式
session B 的 update 語句被 blocked 了,加鎖這個動作是 InnoDB 才能做的,所以排除選項 1。
第二個選項是,MySQL 調用了 InnoDB 引擎提供的接口,但是引擎發現值與原來相同,不更新,直接返回。有沒有這種可能呢?這里我用一個可見性實驗來確認。
假設當前表里的值是 (1,2)。

圖 13 可見性驗證方式
session A的update語句是當前讀,所以結果是匹配了一行,但沒有結果更新。
session A 的第二個 select 語句是一致性讀(快照讀),它是不能看見 session B 的更新的。
現在它返回的是 (1,3),表示它看見了某個新的版本,這個版本只能是 session A 自己的 update 語句做更新的時候生成。
所以,我們的答案應該是選項 3,即:InnoDB 認真執行了“把這個值修改成 (1,2)"這個操作,該加鎖的加鎖,該更新的更新。
然后你會說,MySQL 怎么這么笨,就不會更新前判斷一下值是不是相同嗎?如果判斷一下,不就不用浪費 InnoDB 操作,多去更新一次了?
其實 MySQL 是確認了的。只是在這個語句里面,MySQL 認為讀出來的值,只有一個確定的 (id=1), 而要寫的是 (a=3),只從這兩個信息是看不出來“不需要修改”的。
作為驗證,你可以看一下下面這個例子。

圖 14 可見性驗證方式 -- 對照
這里update語句只查詢只匹配了id=1的條件,而a=3因為是一致性讀所以匹配不上。




)






畢業設計論文提綱參考)
(動態規劃DP-JavaPythonC++JS實現))

)




