Elasticsearch從入門到精通-01認識Elasticsearch
👏作者簡介:大家好,我是程序員行走的魚
🍂博主從本篇正式開始ES學習,希望小伙伴可以一起探討
📖 本篇主要介紹和大家一塊簡單認識下ES并了解ES中的主要角色
ElasticSearch概述
1.1 認識Elasticsearch

? The Elastic Stack, 包括 Elasticsearch、Kibana、Beats 和 Logstash(也稱為 ELK Stack)。能夠安全可靠地獲取任何來源、任何格式的數據,然后實時地對數據進行搜索、分析和可視化。Elaticsearch簡稱為 ES,ES 是一個**開源的高擴展的分布式全文搜索引擎,是整個 Elastic Stack 技術棧的核心。它可以近乎實時的存儲、檢索數據;本身擴展性很好,可以擴展到上百臺服務器,處理 PB 級別的數據。
1.2 什么是全文搜索引擎
? Google,百度類的網站搜索,它們都是根據網頁中的關鍵字生成索引,我們在搜索的時候輸入關鍵字,它們會將該關鍵字即索引匹配到的所有網頁返回;還有常見的項目中應用日志的搜索等等。對于這些非結構化的數據文本,關系型數據庫搜索不是能很好的支持。一般傳統數據庫,全文檢索都實現的很雞肋,因為一般也沒人用數據庫存文本字段。進行全文檢索需要掃描整個表,如果數據量大的話即使對 SQL 的語法優化,也收效甚微。即使建立了索引,但是維護起來也很麻煩,對于 insert 和 update 操作都會重新構建索引。基于以上原因可以分析得出,在一些生產環境中,使用常規的搜索方式,性能是非常差的:
- 搜索的數據對象是大量的非結構化的文本數據。
- 文本記錄量達到數十萬或數百萬個甚至更多。
- 需要支持大量基于交互式文本的查詢。
- 需要非常靈活的全文搜索查詢。
- 對高度相關的搜索結果的有特殊需求,但是沒有可用的關系數據庫可以滿足。
- 對不同記錄類型、非文本數據操作或安全事務處理的需求相對較少的情況。為了解決結構化數據搜索和非結構化數據搜索性能問題,我們就需要專業,健壯,強大的全文搜索引擎
? 這里說到的全文搜索引擎指的是目前廣泛應用的主流搜索引擎。它的工作原理是計算機索引程序通過掃描文章中的每一個詞,對每一個詞建立一個索引,指明該詞在文章中出現的次數和位置,當用戶查詢時,檢索程序就根據事先建立的索引進行查找,并將查找的結果反饋給用戶的檢索方式。這個過程類似于通過字典中的檢索字表查字的過程。
1.3 Elasticsearch And Solr
? Lucene 是 Apache 軟件基金會 Jakarta 項目組的一個子項目,提供了一個簡單卻強大的應用程式接口,能夠做全文索引和搜尋。在 Java 開發環境里 Lucene 是一個成熟的免費開源工具。就其本身而言,Lucene 是當前以及最近幾年最受歡迎的免費 Java 信息檢索程序庫。但 Lucene 只是一個提供全文搜索功能類庫的核心工具包,而真正使用它還需要一個完善的服務框架搭建起來進行應用。
? 目前市面上流行的搜索引擎軟件,主流的就兩款:Elasticsearch 和 Solr,這兩款都是基于 Lucene 搭建的,可以獨立部署啟動的搜索引擎服務軟件。由于內核相同,所以兩者除了服務器安裝、部署、管理、集群以外,對于數據的操作修改、添加、保存、查詢等等都十分類似。
? 在使用過程中,一般都會將 Elasticsearch 和 Solr 這兩個軟件對比,然后進行選型。這兩個搜索引擎都是流行的,先進的的開源搜索引擎。它們都是圍繞核心底層搜索庫 - Lucene構建的 - 但它們又是不同的。像所有東西一樣,每個都有其優點和缺點:
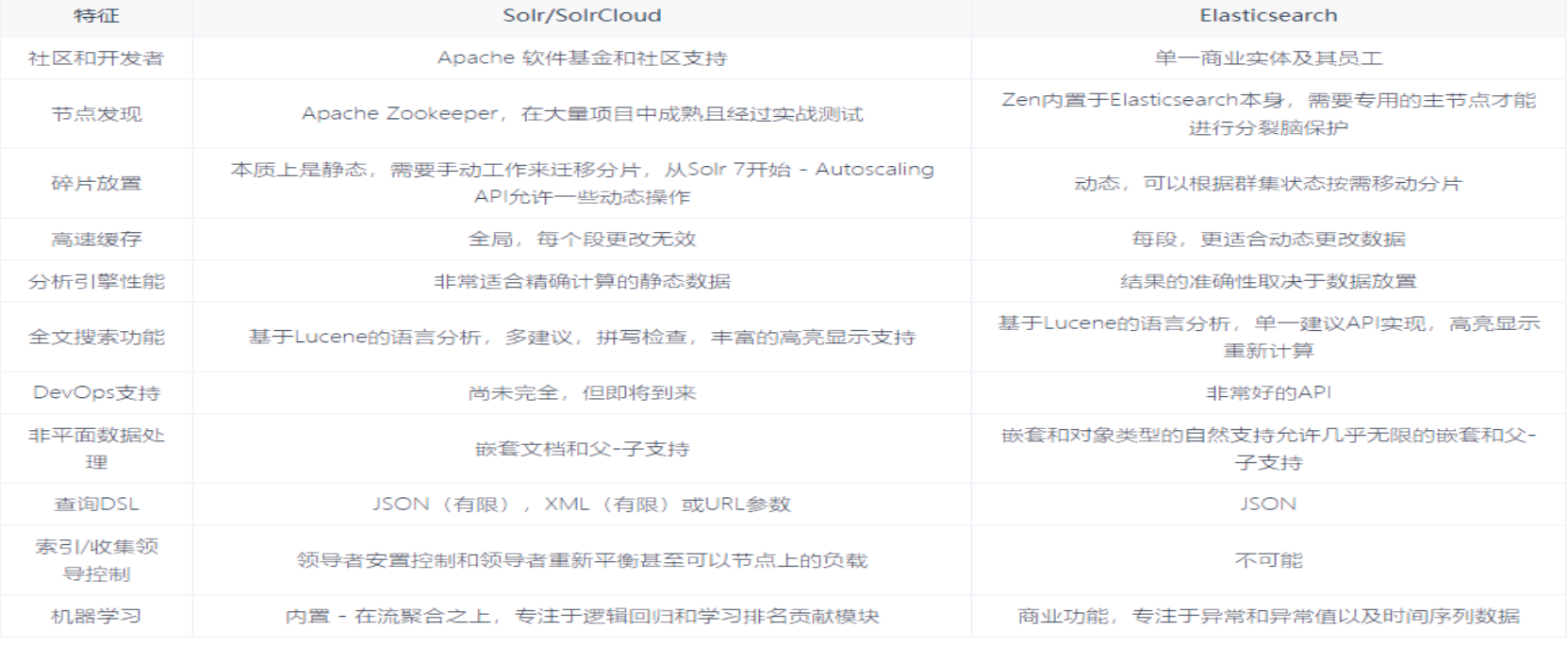
當單純的對已有數據進行搜索時,Solr更快。當實時建立索引時, Solr會產生io阻塞,查詢性能較差, Elasticsearch具有明顯的優勢。大型互聯網公司,實際生產環境測試,將搜索引擎從Solr轉到 Elasticsearch以后的平均查詢速度有了50倍的提升。
1.4 Elasticsearch Or Solr
? Elasticsearch 和 Solr 都是開源搜索引擎,那么我們在使用時該如何選擇呢?
-
Google 搜索趨勢結果表明,與 Solr 相比,Elasticsearch 具有很大的吸引力,但這并不意味著 Apache Solr 已經死亡。雖然有些人可能不這么認為,但 Solr 仍然是最受歡迎的搜索引擎之一,擁有強大的社區和開源支持。
-
與 Solr 相比,Elasticsearch 易于安裝且非常輕巧。此外,你可以在幾分鐘內安裝并運行Elasticsearch。但是,如果 Elasticsearch 管理不當,這種易于部署和使用可能會成為一個問題。基于 JSON 的配置很簡單,但如果要為文件中的每個配置指定注釋,那么它不適合您。總的來說,如果你的應用使用的是 JSON,那么 Elasticsearch 是一個更好的選擇。否則,請使用 Solr,因為它的 schema.xml 和 solrconfig.xml 都有很好的文檔記錄。
-
Solr 擁有更大,更成熟的用戶,開發者和貢獻者社區。ES 雖擁有的規模較小但活躍的用戶社區以及不斷增長的貢獻者社區。
Solr 貢獻者和提交者來自許多不同的組織,而 Elasticsearch 提交者來自單個公司。
-
Solr 更成熟,但 ES 增長迅速,更穩定。
-
Solr 是一個非常有據可查的產品,具有清晰的示例和 API 用例場景。 Elasticsearch的文檔組織良好,但它缺乏好的示例和清晰的配置說明。
-
Solr 支持更多格式的數據,比如JSON、XML、CSV,而 Elasticsearch 僅支持json文件格式。
-
Solr 在傳統的搜索應用中表現好于 Elasticsearch,但在處理實時搜索應用時效率明顯低于 Elasticsearch。
? 那么,到底是Solr還是Elasticsearch?
? 有時很難找到明確的答案。無論您選擇 Solr 還是 Elasticsearch,首先需要了解正確的用例和未來需求。總結他們的每個屬性。
- 由于易于使用,Elasticsearch 在新開發者中更受歡迎。一個下載和一個命令就可以啟動一切。
- 如果除了搜索文本之外還需要它來處理分析查詢,Elasticsearch 是更好的選擇
- 如果需要分布式索引,則需要選擇 Elasticsearch。對于需要良好可伸縮性和以及性能分布式環境,Elasticsearch 是更好的選擇。
- Elasticsearch 在開源日志管理用例中占據主導地位,許多組織在 Elasticsearch 中索引它們的日志以使其可搜索。
- 如果你喜歡監控和指標,那么請使用 Elasticsearch,因為相對于 Solr,Elasticsearch 暴露了更多的關鍵指標
1.5 Elasticsearch應用案例
- GitHub:2013 年初,拋棄了 Solr,采取 Elasticsearch 來做 PB 級的搜索。“GitHub使用Elasticsearch 搜索 20TB 的數據,包括13億文件和1300億行代碼""。
- 維基百科:啟動以 Elasticsearch 為基礎的核心搜索架構
- SoundCloud:“SoundCloud 使用 Elasticsearch 為 1.8 億用戶提供即時而精準的音樂搜索服務”。
- 百度:目前廣泛使用 Elasticsearch 作為文本數據分析,采集百度所有服務器上的各類指標數據及用戶自定義數據,通過對各種數據進行多維分析展示,輔助定位分析實例異常或業務層面異常。目前覆蓋百度內部 20 多個業務線(包括云分析、網盟、預測、文庫、直達號、錢包、風控等),單集群最大 100 臺機器,200 個 ES 節點,每天導入 30TB+數據。
- 新浪:使用 Elasticsearch 分析處理 32 億條實時日志。
- 阿里:使用 Elasticsearch 構建日志采集和分析體系。
- Stack Overflow:解決 Bug 問題的網站,全英文,編程人員交流的網站。
ElasticSearch基本概念
2.1索引(Index)
? 一個索引就是一個擁有幾分相似特征的文檔的集合。比如說,你可以有一個客戶數據的索引,另一個產品目錄的索引,還有一個訂單數據的索引。一個索引由一個名字來標識(必須全部是小寫字母),并且當我們要對這個索引中的文檔進行索引、搜索、更新和刪除的時候,都要使用到這個名字。在一個集群中,可以定義任意多的索引。
? 能搜索的數據必須索引,這樣的好處是可以提高查詢速度,比如:新華字典前面的目錄就是索引的意思,目錄可以提高查詢速度。
Elasticsearch 索引的精髓:一切設計都是為了提高搜索的性能。
2.2 類型(Type)
? 在一個索引中,你可以定義一種或多種類型。
? 一個類型是你的索引的一個邏輯上的分類/分區,其語義完全由你來定。通常,會為具有一組共同字段的文檔定義一個類型。不同的版本,類型發生了不同的變化

2.3 文檔(Document)
? 一個文檔是一個可被索引的基礎信息單元,也就是一條數據.
? 比如:你可以擁有某一個客戶的文檔,某一個產品的一個文檔,當然,也可以擁有某個訂單的一個文檔。文檔以JSON格式來表示,而 JSON 是一個到處存在的互聯網數據交互格式。
? 在一個 index/type 里面,你可以存儲任意多的文檔。
2.4 字段(Field)
? 相當于是數據表的字段,對文檔數據根據不同屬性進行的分類標識。
2.5 映射(Mapping)
? mapping 是處理數據的方式和規則方面做一些限制,如:某個字段的數據類型、默認值、分析器、是否被索引等等。這些都是映射里面可以設置的,其它就是處理 ES 里面數據的一些使用規則設置也叫做映射,按著最優規則處理數據對性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能對性能更好。
2.6 分片(Shards)
? 一個索引可以存儲超出單個節點硬件限制的大量數據。比如,一個具有 10 億文檔數據的索引占據 1TB 的磁盤空間,而任一節點都可能沒有這樣大的磁盤空間。或者單個節點處理搜索請求,響應太慢。為了解決這個問題,Elasticsearch 提供了將索引劃分成多份的能力,每一份就稱之為分片。當你創建一個索引的時候,你可以指定你想要的分片的數量。每個分片本身也是一個功能完善并且獨立的“索引”,這個“索引”可以被放置到集群中的任何節點上。
? 分片很重要,主要有兩方面的原因:
? (1)允許你水平分割 / 擴展你的內容容量。
? (2)允許你在分片之上進行分布式的、并行的操作,進而提高性能/吞吐量。
? 至于一個分片怎樣分布,它的文檔怎樣聚合和搜索請求,是完全由 Elasticsearch 管理的,對于作為用戶的你來說,這些都是透明的,無需過分關心。
被混淆的概念是,一個
Lucene索引我們在Elasticsearch稱作分片 。 一個Elasticsearch索引是分片的集合。 當Elasticsearch在索引中搜索的時候, 他發送查詢到每一個屬于索引的分片(Lucene 索引),然后合并每個分片的結果到一個全局的結果集。
2.7副本(Replicas)
? 在一個網絡 / 云的環境里,失敗隨時都可能發生,在某個分片/節點不知怎么的就處于離線狀態,或者由于任何原因消失了,這種情況下,有一個故障轉移機制是非常有用并且是強烈推薦的。為此目的,Elasticsearch允許你創建分片的一份或多份拷貝,這些拷貝叫做復制分片(副本)。
? 復制分片之所以重要,有兩個主要原因:
? (1)在分片/節點失敗的情況下,提供了高可用性。因為這個原因,注意到復制分片從不與原/主要(original/primary)分片置于同一節點上是非常重要的。
? (2)擴展你的搜索量/吞吐量,因為搜索可以在所有的副本上并行運行。
? 總之,每個索引可以被分成多個分片。一個索引也可以被復制 0 次(意思是沒有復制)或多次。一旦復制了,每個索引就有了主分片(作為復制源的原來的分片)和復制分片(主分片的拷貝)之別。分片和復制的數量可以在索引創建的時候指定。在索引創建之后,你可以在任何時候動態地改變復制的數量,但是你事后不能改變分片的數量。默認情況下,Elasticsearch中的每個索引被分片 1 個主分片和 1 個復制分配,這意味著,如果你的集群中至少有兩個節點,你的索引將會有 1 個主分片和另外 1 個復制分片(1 個完全拷貝),這樣的話每個索引總共就有 2 個分片,我們需要根據索引需要確定分片個數。
2.8分配
? 將分片分配給某個節點的過程,包括分配主分片或者副本。如果是副本,還包含從主分片復制數據的過程。這個過程是由 master 節點完成的。
主分片和另外 1 個復制分片(1 個完全拷貝),這樣的話每個索引總共就有 2 個分片,我們需要根據索引需要確定分片個數。
2.8分配
? 將分片分配給某個節點的過程,包括分配主分片或者副本。如果是副本,還包含從主分片復制數據的過程。這個過程是由 master 節點完成的。
🌟至此本篇就結束了,下一篇將介紹ES環境搭建以及客戶端的安裝,包括Linux和Docker兩種輕松搭建一個屬于自己的ES服務

)








)








)