原文地址:Video generation models as world simulators
我們探索在視頻數據上進行大規模生成模型的訓練。具體來說,我們聯合訓練文本條件擴散模型,同時處理不同持續時間、分辨率和長寬比的視頻和圖像。我們利用一個在視頻和圖像潛在編碼的時空塊上運行的轉換器結構。我們最大的模型Sora能夠生成一分鐘高保真度視頻。我們的結果表明,擴展視頻生成模型是建立物理世界通用目的模擬器的一個有前途的途徑。
這份技術報告著重介紹了兩個方面:(1) 我們將各種類型的視覺數據轉化為統一表示形式的方法,從而實現生成模型的大規模訓練;和 (2) 對Sora的能力和局限性進行定性評估。報告中不包括模型和實施細節。
許多先前的研究都使用各種方法對視頻數據進行生成建模,包括循環網絡、生成對抗網絡、自回歸變換器和擴散模型。這些工作通常聚焦于狹窄類別的視覺數據、較短的視頻或固定大小的視頻。Sora是一種視覺數據的通用模型,它能夠生成跨越不同持續時間、長寬比和分辨率的視頻和圖像,達到高清晰度視頻長達一分鐘。
將視覺數據轉化為塊
我們受到大型語言模型的啟發,這些模型通過在互聯網規模的數據上進行訓練獲得了通用能力。語言模型的成功在一定程度上歸功于優雅地統一了文本、代碼、數學和各種自然語言等多種形式的令牌。在這項工作中,我們考慮如何將視覺數據的生成模型繼承這些好處。而語言模型使用文本令牌,Sora使用視覺塊。之前已經證明,塊對于視覺數據的模型是一種有效的表示形式。我們發現,塊是一種高度可擴展且有效的表示形式,適用于訓練各種類型的視頻和圖像的生成模型。
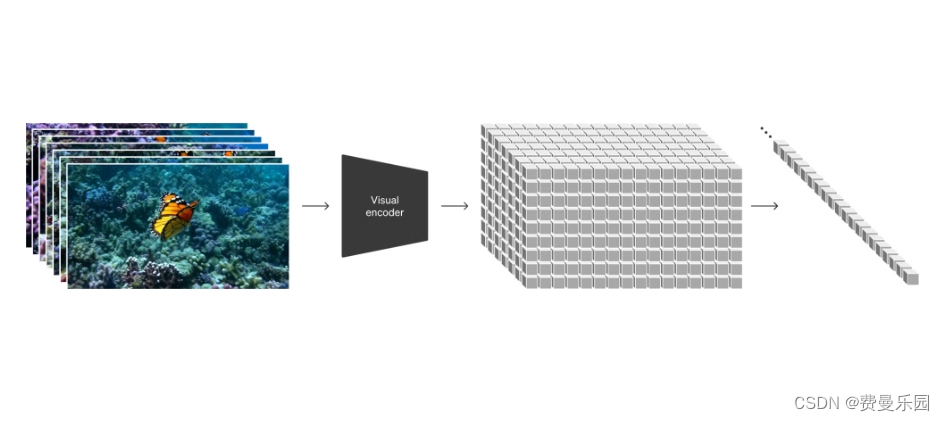 ?
?
在高層次上,我們首先將視頻壓縮成較低維的潛在空間,然后將表示分解為時空塊。
視頻壓縮網絡?
我們訓練了一個網絡來降低視覺數據的維度。該網絡接收原始視頻作為輸入,并輸出一個在時間和空間上都進行了壓縮的潛在表示。Sora在這個壓縮的潛在空間上進行訓練,并生成視頻。我們還訓練了一個相應的解碼器模型,將生成的潛在表示映射回像素空間。
時空潛在塊?
給定一個壓縮的輸入視頻,我們提取一系列時空塊作為變換器的令牌。這個方案也適用于圖像,因為圖像只是具有單幀的視頻。我們基于塊的表示形式使得Sora能夠在分辨率、持續時間和長寬比可變的視頻和圖像上進行訓練。在推理時,我們可以通過將隨機初始化的塊按適當大小的網格排列來控制生成的視頻的大小。
擴展變換器用于視頻生成?
Sora是一個擴散模型;在給定噪聲塊輸入(以及像文本提示這樣的條件信息)的情況下,它被訓練來預測原始的“清晰”塊。重要的是,Sora是一個擴散變換器。變換器在各種領域展示了顯著的擴展性能,包括語言建模、計算機視覺和圖像生成。
 ?
?
在這項工作中,我們發現擴散變換器同樣可以有效地擴展為視頻模型。下面,我們展示了在訓練進行中使用固定種子和輸入的視頻樣本比較。隨著訓練計算力的增加,樣本質量顯著提高。
可變的持續時間、分辨率和長寬比?
先前的圖像和視頻生成方法通常將視頻調整大小、裁剪或修剪為標準尺寸,例如256x256分辨率的4秒視頻。我們發現,相反,以原始大小訓練數據具有幾個優勢。
采樣靈活性?
Sora可以對寬屏1920x1080p視頻、豎屏1080x1920視頻以及介于兩者之間的視頻進行采樣。這使Sora能夠直接以各種設備的原生長寬比創建內容。它還使我們能夠在較低尺寸快速原型化內容,然后再使用相同的模型生成全分辨率內容。
改善構圖和組成 ??
我們在實踐中發現,以視頻的原生長寬比進行訓練可以改善構圖和組成。我們將Sora與將所有訓練視頻裁剪為正方形的模型版本進行了比較,這是訓練生成模型時常見的做法。在正方形裁剪訓練的模型(左側)有時會生成主體僅部分在視野中的視頻。相比之下,Sora生成的視頻(右側)具有改進的構圖。
語言理解?
訓練文本到視頻生成系統需要大量帶有相應文本標題的視頻。我們將引入 DALL·E 3 中的重新標注技術應用到視頻中。我們首先訓練一個高度描述性的標題模型,然后使用它為我們訓練集中的所有視頻生成文本標題。我們發現,使用高度描述性的視頻標題進行訓練不僅提高了文本的準確性,還改善了視頻的整體質量。
類似于DALL·E 3,我們還利用GPT將用戶的簡短提示轉化為更加詳細的長篇說明,并將其發送給視頻模型。這使得Sora能夠生成高質量的視頻,準確地遵循用戶的提示。
通過圖像和視頻發出提示?
以上所有結果以及我們的主頁展示的都是文本到視頻的樣本。但是Sora也可以通過其他輸入進行提示,例如預先存在的圖像或視頻。這種能力使得Sora能夠執行各種圖像和視頻編輯任務,比如創建完美循環的視頻、為靜態圖像添加動畫效果、向后或向前延伸視頻等。
為DALL·E圖像添加動畫效果?
Sora能夠根據提供的圖像和提示生成視頻。以下是基于DALL·E 2和DALL·E 3圖像生成的示例視頻。
延長生成的視頻?
Sora還可以延長視頻的時間,可以向前或向后延長。以下是四個視頻,它們都是從一個生成的視頻片段開始向時間倒退延伸。因此,這四個視頻的開頭各不相同,但最終都導向同樣的結尾。
我們可以使用這種方法向前和向后延伸視頻,以生成一個無縫的無限循環。
視頻到視頻的編輯?
擴散模型為從文本提示編輯圖像和視頻提供了眾多方法。下面我們將其中一種方法,SDEdit,應用到Sora上。這種技術使得Sora能夠零-shot轉換輸入視頻的風格和環境。
連接視頻?
?我們還可以使用Sora逐漸插值兩個輸入視頻之間,創建在完全不同主題和場景組合之間無縫過渡的視頻。在下面的示例中,中間的視頻是左側和右側對應視頻之間插值產生的結果。
圖像生成能力?
Sora還具備生成圖像的能力。我們通過在時間軸上以一幀的時間跨度將高斯噪聲塊排列在空間網格中來實現這一點。該模型可以生成不同大小的圖像,分辨率高達2048x2048。
新興的仿真能力?
我們發現,當視頻模型在大規模訓練時,它們表現出一些有趣的新興能力。這些能力使得Sora能夠從物理世界中模擬出人、動物和環境的某些方面。這些特性的出現并沒有任何針對3D、物體等顯式歸納偏好,它們純粹是規模現象所產生的。
3D一致性??Sora可以生成具有動態攝像機運動的視頻。隨著攝像機的移動和旋轉,人物和場景元素在三維空間中以一致的方式移動。
長程連貫性和物體持久性??對視頻生成系統的一個重要挑戰是在采樣長視頻時保持時間一致性。我們發現,盡管不總是如此,Sora通常能夠有效地模擬短期和長期依賴關系。例如,我們的模型可以在人們、動物和物體被遮擋或離開畫面時仍然保持它們的存在。同樣地,它可以在單個樣本中生成同一角色的多個鏡頭,并在整個視頻中保持他們的外觀。
與世界互動??Sora有時可以模擬一些影響世界狀態的簡單動作。例如,一位畫家可以在畫布上留下新的筆觸,并隨著時間推移而保留下來,或者一個人可以吃掉一個漢堡并留下咬痕。
模擬數字世界??Sora還能夠模擬人工過程,一個例子是視頻游戲。Sora可以同時使用基本策略控制《Minecraft》中的玩家,并以高保真度呈現世界及其動態。通過提供包含“Minecraft”關鍵詞的描述性標題,這些能力可以從零開始引出。
這些能力表明,繼續擴展視頻模型是發展高能力物理世界和數字世界模擬器的有前途的道路,并模擬其中生活的物體、動物和人類。
討論?
目前,Sora作為一個模擬器還存在許多限制。例如,它無法準確地模擬許多基本交互的物理性質,比如玻璃破碎。其他交互,比如吃東西,也不總是產生正確的物體狀態變化。我們在我們的首頁上列舉了模型出現的其他常見故障模式,比如長時間樣本中出現的不連貫性或物體的突然出現。
我們相信,Sora如今所展現的能力表明,繼續擴展視頻模型是發展具有能力的物理世界和數字世界模擬器,并模擬其中生活的物體、動物和人類的有前途的道路。?


)


)








——速度表的multisim仿真)


![[概念區分] 正則表達式與正則化](http://pic.xiahunao.cn/[概念區分] 正則表達式與正則化)

)