一、概述
系統進入suspended或進程被加入到cgroup凍結或解凍分組,用戶進程和部分內核線程被凍結后,會剝奪執行cpu資源,解凍或喚醒后恢復正常。
二、進程凍結與解凍原理
2.1 進程凍結
用戶進程和內核線程凍結的基本流程:
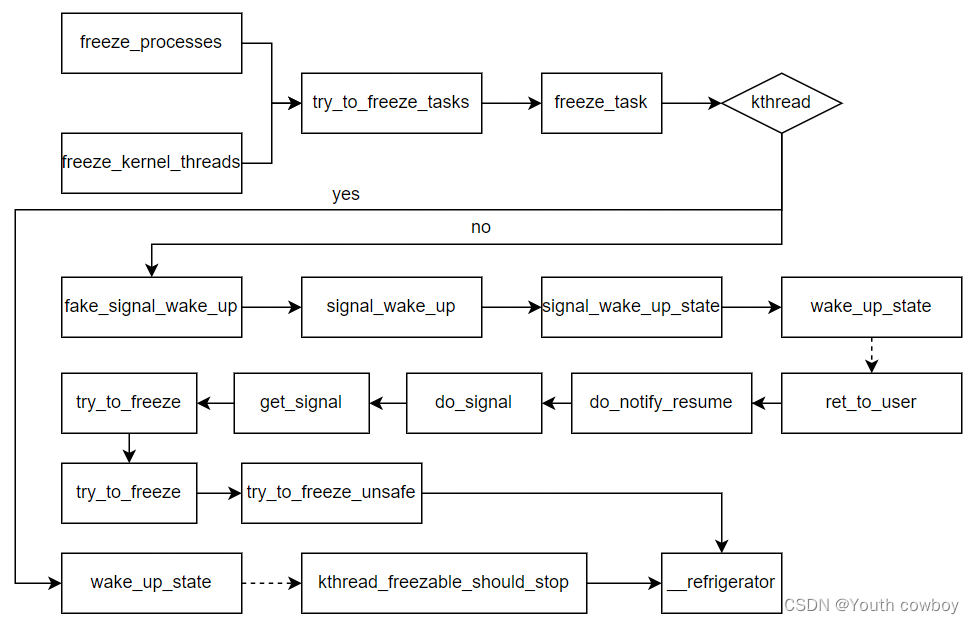
內核態線程可直接喚醒執行凍結操作,用戶進程則需要在其返回到用戶態時才能執行凍結操作。這是因為若其在內核態執行時被凍結,若其正好持有一些鎖,則可能會導致死鎖。為此,內核通過了一個比較巧妙的方式實現了凍結流程。它首先為該進程設置了一個信號pending標志TIF_SIGPENDING,但并不向該進程發送實際的信號,然后通過ipi喚醒該進程執行。由于ipi會進行進程內核的中斷處理流程,當其處理完成后,會調用ret_to_user函數返回用戶態,而該函數會調用信號處理函數檢查是否有pending的中斷需要處理,由于先前已經設置了信號的pending標志,因此會執行信號處理流程。此時,會發現進程凍結相關的全局變量已設置,故進程將執行凍結流程。
2.1.1 凍結用戶進程
int freeze_processes(void)
{int error;error = __usermodehelper_disable(UMH_FREEZING);if (error)return error;/* Make sure this task doesn't get frozen */current->flags |= PF_SUSPEND_TASK;if (!pm_freezing)atomic_inc(&system_freezing_cnt);pm_wakeup_clear(0);pr_info("%s:Freezing user space processes ... ", STR_KERNEL_LOG_ENTER);pm_freezing = true;// true表示用戶進程error = try_to_freeze_tasks(true);if (!error) {__usermodehelper_set_disable_depth(UMH_DISABLED);pr_cont("done.");}pr_cont("\n");BUG_ON(in_atomic());/** Now that the whole userspace is frozen we need to disable* the OOM killer to disallow any further interference with* killable tasks. There is no guarantee oom victims will* ever reach a point they go away we have to wait with a timeout.*/if (!error && !oom_killer_disable(msecs_to_jiffies(freeze_timeout_msecs)))error = -EBUSY;if (error)thaw_processes();return error;
}static int try_to_freeze_tasks(bool user_only) {if (!user_only)freeze_workqueues_begin();while (true) {todo = 0;read_lock(&tasklist_lock);for_each_process_thread(g, p) {if (p == current || !freeze_task(p))continue;......}......
}bool freeze_task(struct task_struct *p)
{unsigned long flags;/** This check can race with freezer_do_not_count, but worst case that* will result in an extra wakeup being sent to the task. It does not* race with freezer_count(), the barriers in freezer_count() and* freezer_should_skip() ensure that either freezer_count() sees* freezing == true in try_to_freeze() and freezes, or* freezer_should_skip() sees !PF_FREEZE_SKIP and freezes the task* normally.*/// 若進程設置了PF_FREEZER_SKIP,則不能凍結if (freezer_should_skip(p))return false;spin_lock_irqsave(&freezer_lock, flags);if (!freezing(p) || frozen(p)) {spin_unlock_irqrestore(&freezer_lock, flags);return false;}// 如果是用戶進程,需要先發送偽信號,當進程返回用戶空間時處理信號過程中被凍結,因為若其在內核態執行時被凍結,若其正好持有一些鎖,則可能會導致死鎖// 如果是內核線程,直接凍結,并將狀態設置為TASK_INTERRUPTIBLEif (!(p->flags & PF_KTHREAD))fake_signal_wake_up(p);elsewake_up_state(p, TASK_INTERRUPTIBLE);spin_unlock_irqrestore(&freezer_lock, flags);return true;
}// kernel/kernel/signal.coid signal_wake_up_state(struct task_struct *t, unsigned int state)
{// 設置TIF_SIGPENDING信號,在get_signal函數中獲取處理set_tsk_thread_flag(t, TIF_SIGPENDING);/** TASK_WAKEKILL also means wake it up in the stopped/traced/killable* case. We don't check t->state here because there is a race with it* executing another processor and just now entering stopped state.* By using wake_up_state, we ensure the process will wake up and* handle its death signal.*/if (!wake_up_state(t, state | TASK_INTERRUPTIBLE))kick_process(t);
}bool get_signal(struct ksignal *ksig)
{struct sighand_struct *sighand = current->sighand;struct signal_struct *signal = current->signal;int signr;if (unlikely(uprobe_deny_signal()))return false;/** Do this once, we can't return to user-mode if freezing() == T.* do_signal_stop() and ptrace_stop() do freezable_schedule() and* thus do not need another check after return.*/try_to_freeze();......} static inline bool try_to_freeze(void)
{if (!(current->flags & PF_NOFREEZE))debug_check_no_locks_held();return try_to_freeze_unsafe();
}static inline bool try_to_freeze_unsafe(void)
{might_sleep();if (likely(!freezing(current)))return false;return __refrigerator(false);
}2.1.2 凍結內核線程
int freeze_kernel_threads(void)
{int error;pr_info("%s:Freezing remaining freezable tasks ... ", STR_KERNEL_LOG_ENTER);pm_nosig_freezing = true;// 傳入false表示內核線程,代碼流程同2.1.1中try_to_freeze_taskserror = try_to_freeze_tasks(false);if (!error)pr_cont("done.");pr_cont("\n");BUG_ON(in_atomic());if (error)thaw_kernel_threads();return error;
}最后會調用kthread_freezable_should_stop函數執行內線線程凍結:
bool kthread_freezable_should_stop(bool *was_frozen)
{…if (unlikely(freezing(current)))frozen = __refrigerator(true);if (was_frozen)*was_frozen = frozen;return kthread_should_stop();
}2.1.3 小結
進程被凍結主要做了以下事情:
1)設置task狀態為TASK_UNINTERRUPTIBLE,表示不能加入就緒隊列被調度
2)設置task的flag為PF_FROZEN,表示進程已被凍結
3)調用schedule函數,將task從cpu上調度出來,不讓其執行cpu,將寄存器堆棧信息保存到thread_info->cpu_context中
4)進程被解凍時,重新被調度,退出for循環,繼續往下執行,重新設置task的狀態為TASK_RUNNING
bool __refrigerator(bool check_kthr_stop)
{/* Hmm, should we be allowed to suspend when there are realtimeprocesses around? */bool was_frozen = false;long save = current->state;pr_debug("%s entered refrigerator\n", current->comm);for (;;) {// 設置當前task狀態為TASK_UNINTERRUPTIBLEset_current_state(TASK_UNINTERRUPTIBLE);spin_lock_irq(&freezer_lock);// 設置當前task的flag為PF_FROZEN,表示已凍結current->flags |= PF_FROZEN;if (!freezing(current) ||(check_kthr_stop && kthread_should_stop()))current->flags &= ~PF_FROZEN;trace_android_rvh_refrigerator(pm_nosig_freezing);spin_unlock_irq(&freezer_lock);if (!(current->flags & PF_FROZEN))break;was_frozen = true;// 將task從cpu上調度出來,不讓其執行cpu,執行schedule函數,會將寄存器堆棧信息保存到thread_info->cpu_context中// task的上下文保存后,停留在該處,下次被喚醒時,重新被調度,退出for循環,往下執行schedule();}pr_debug("%s left refrigerator\n", current->comm);/** Restore saved task state before returning. The mb'd version* needs to be used; otherwise, it might silently break* synchronization which depends on ordered task state change.*/// 被喚醒時,重新設置task的狀態set_current_state(save);return was_frozen;
}
EXPORT_SYMBOL(__refrigerator);2.2 進程解凍或喚醒
進程解凍會調用調度模塊進行進程喚醒,狀態設置為runnable或running.
void __thaw_task(struct task_struct *p)
{unsigned long flags;const struct cpumask *mask = task_cpu_possible_mask(p);spin_lock_irqsave(&freezer_lock, flags);/** Wake up frozen tasks. On asymmetric systems where tasks cannot* run on all CPUs, ttwu() may have deferred a wakeup generated* before thaw_secondary_cpus() had completed so we generate* additional wakeups here for tasks in the PF_FREEZER_SKIP state.*/if (frozen(p) || (frozen_or_skipped(p) && mask != cpu_possible_mask))// 調用調度模塊喚醒進程wake_up_process(p);spin_unlock_irqrestore(&freezer_lock, flags);
}線程入隊操作并標記線程p為runnable狀態,線程標記為TASK_RUNNING,并執行喚醒搶占操作。
int wake_up_process(struct task_struct *p)
{WARN_ON(task_is_stopped_or_traced(p));return try_to_wake_up(p, TASK_NORMAL, 0);
}static int try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{unsigned long flags;int cpu, success = 0;/** If we are going to wake up a thread waiting for CONDITION we* need to ensure that CONDITION=1 done by the caller can not be* reordered with p->state check below. This pairs with mb() in* set_current_state() the waiting thread does.*/smp_mb__before_spinlock();raw_spin_lock_irqsave(&p->pi_lock, flags);if (!(p->state & state))goto out;success = 1; /* we're going to change ->state */cpu = task_cpu(p);/* 使用內存屏障保證p->on_rq的數值是最新的。如果線程已經在運行隊列rq里面了,即進程已經處于runnable/running狀態。ttwu_remote目的是由于線程 p已經在運行隊列rq里面了,并且沒有完全取消調度,再次喚醒的話,需要將線程的狀態翻轉:將狀態設置為TASK_RUNNING,這樣線程就一直在運行隊列里面了。這種情況則直接退出后續流程,并對調度狀態/數據進行統計 */if (p->on_rq && ttwu_remote(p, wake_flags))goto stat;#ifdef CONFIG_SMP/* 等待在其他cpu上的線程調度完成 */while (p->on_cpu)cpu_relax();/** Pairs with the smp_wmb() in finish_lock_switch().*/smp_rmb();p->sched_contributes_to_load = !!task_contributes_to_load(p);p->state = TASK_WAKING;/* 根據進程的所屬的調度類調用相應的回調函數 */if (p->sched_class->task_waking)p->sched_class->task_waking(p);/* 根據線程p相關參數和系統狀態,為線程p選擇合適的cpu */cpu = select_task_rq(p, p->wake_cpu, SD_BALANCE_WAKE, wake_flags);/* 如果選擇的cpu與線程p當前所在的cpu不相同,則將線程的wake_flags設置為需要遷移,然后將線程p遷移到cpu上 */if (task_cpu(p) != cpu) {wake_flags |= WF_MIGRATED;set_task_cpu(p, cpu);}
#endif /* CONFIG_SMP *//* 線程p入隊操作并標記線程p為runnable狀態,同時喚醒搶占 */ttwu_queue(p, cpu);
stat:/* 與調度相關的統計 */ttwu_stat(p, cpu, wake_flags);
out:raw_spin_unlock_irqrestore(&p->pi_lock, flags);return success;
}static void ttwu_queue(struct task_struct *p, int cpu)
{struct rq *rq = cpu_rq(cpu);#if defined(CONFIG_SMP)if (sched_feat(TTWU_QUEUE) && !cpus_share_cache(smp_processor_id(), cpu)) {sched_clock_cpu(cpu); /* sync clocks x-cpu */ttwu_queue_remote(p, cpu);return;}
#endifraw_spin_lock(&rq->lock);ttwu_do_activate(rq, p, 0);raw_spin_unlock(&rq->lock);
}static void ttwu_do_activate(struct rq *rq, struct task_struct *p, int wake_flags)
{
#ifdef CONFIG_SMPif (p->sched_contributes_to_load)rq->nr_uninterruptible--;
#endif//將線程p加入運行隊列rq中ttwu_activate(rq, p, ENQUEUE_WAKEUP | ENQUEUE_WAKING);//將任務標記為可運行的,并執行喚醒搶占。ttwu_do_wakeup(rq, p, wake_flags);
}static void ttwu_activate(struct rq *rq, struct task_struct *p, int en_flags)
{activate_task(rq, p, en_flags);p->on_rq = TASK_ON_RQ_QUEUED;/* if a worker is waking up, notify workqueue */if (p->flags & PF_WQ_WORKER)wq_worker_waking_up(p, cpu_of(rq));
}static void enqueue_task(struct rq *rq, struct task_struct *p, int flags)
{update_rq_clock(rq);sched_info_queued(rq, p);p->sched_class->enqueue_task(rq, p, flags);
}void activate_task(struct rq *rq, struct task_struct *p, int flags)
{if (task_contributes_to_load(p))rq->nr_uninterruptible--;enqueue_task(rq, p, flags);
}//將任務標記為可運行的,并執行喚醒搶占操作
static void ttwu_do_wakeup(struct rq *rq, struct task_struct *p, int wake_flags)
{check_preempt_curr(rq, p, wake_flags);trace_sched_wakeup(p, true);//將線程p的狀態設置為TASK_RUNNINGp->state = TASK_RUNNING;
#ifdef CONFIG_SMPif (p->sched_class->task_woken)p->sched_class->task_woken(rq, p);if (rq->idle_stamp) {u64 delta = rq_clock(rq) - rq->idle_stamp;u64 max = 2*rq->max_idle_balance_cost;update_avg(&rq->avg_idle, delta);if (rq->avg_idle > max)rq->avg_idle = max;rq->idle_stamp = 0;}
#endif
}/*在增加nr_running之前調用enqueue_task()函數。在這里,將更新公平調度統計數據,然后將線程p的調度實體放入rbtree紅黑樹中*/
static void enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{struct cfs_rq *cfs_rq;struct sched_entity *se = &p->se;for_each_sched_entity(se) {if (se->on_rq)break;cfs_rq = cfs_rq_of(se);// 調度實體存入就緒隊列enqueue_entity(cfs_rq, se, flags);/** end evaluation on encountering a throttled cfs_rq** note: in the case of encountering a throttled cfs_rq we will* post the final h_nr_running increment below.*/if (cfs_rq_throttled(cfs_rq))break;cfs_rq->h_nr_running++;flags = ENQUEUE_WAKEUP;}for_each_sched_entity(se) {cfs_rq = cfs_rq_of(se);cfs_rq->h_nr_running++;if (cfs_rq_throttled(cfs_rq))break;// 更新cfs隊列權重update_cfs_shares(cfs_rq);// 更新調度實體的平均負載update_entity_load_avg(se, 1);}if (!se) {update_rq_runnable_avg(rq, rq->nr_running);add_nr_running(rq, 1);}hrtick_update(rq);
}
)













使用)




