
本文主要分三部分內容:第一部分介紹拓數派公司,第二部分介紹 πDataCS 產品,最后介紹 πDataCS 與龍蜥在生態上的合作。
杭州拓數派科技發展有限公司(簡稱“拓數派”,英文名稱“OpenPie”)是國內基礎數據計算領域的高科技創新企業。作為國內云上數據庫和數據計算領域的引領者,以“Data Computing for New Discoveries”「數據計算,只為新發現」為使命,致力于在數字原生時代,運用突破性計算理論、獨創的云原生數據庫旗艦產品以及之上的算法和數學模型,建立下一代云原生數據平臺的前沿標準,驅動企業實現從“軟件公司”到“數據公司”再到“數學公司”的持續進階,加速數字化轉型升級。
拓數派自成立以來專注于數據計算領域,旗下大模型數據計算系統(PieDataComputingSystem, 縮寫:πDataCS),以云原生技術重構數據存儲和計算,一份存儲,多引擎數據計算,讓 AI 模型更大更快,全面升級大數據系統至大模型時代。πDataCS 旨在助力企業優化計算瓶頸、充分利用和發揮數據規模優勢,構建核心技術壁壘,更好地賦能業務發展,使得自主可控的大模型數據計算系統保持全球領先,讓大模型技術全面賦能各行各業。 目前大模型數據計算系統,面向國內市場提供公有云版、社區版、企業版及一體機多個版本,滿足企業不同業務場景需求,并已為金融、制造、醫療及教育等行業用戶構建了 AI 數據底座。

拓數派擁有強悍的研發核心團隊和有成功上市經驗的管理團隊。其核心團隊成員主要來自 Pivotal、IBM、騰訊、字節跳動、快手、Oracle 等世界 500 強以及國內頭部互聯網公司。拓數派創始人兼 CEO 馮雷(Ray Von)是數據云和人工智能領域的連續創業者和技術引領者。馮雷于 2010 年從美國硅谷歸國,曾在 500 強公司 EMC 旗下創建 Greenplum 中國研發部門工作。2013 年隨著全球 Pivotal 組建,馮雷先生在中國 Greenplum 大數據和 VMWare 的 PaaS 云的基礎上組建了 Pivotal 中國研發中心,推動了 Greenplum 大數據庫、CloudFoundry PaaS 云等知名開源產品的領域領先地位。

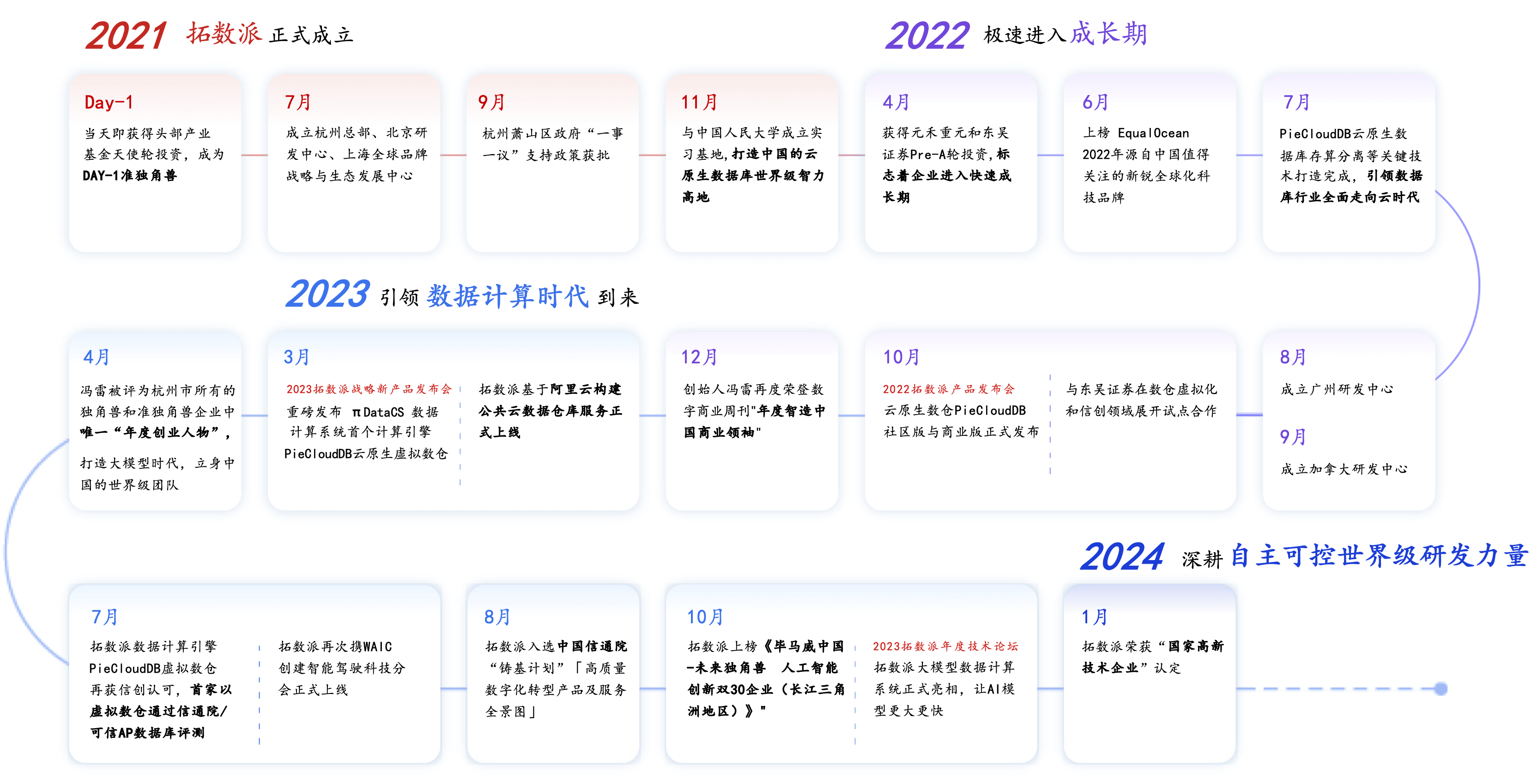
拓數派 2021 年創立,迅速進入快速發展階段,引領數據計算時代的到來。成立當天即獲得頭部產業基金天使輪投資,成為 DAY-1 準獨角獸。2022 年拓數派發布了云原生虛擬數倉 PieCloudDB 社區版與商業版。2023 年拓數派大模型數據計算系統 πDataCS 正式亮相,讓 AI 模型更大更快。
下面介紹 πDataCS。數據分析的目的最終是為了發現解釋世界規則的模型。有了數據和計算,最終用來描述世界規律,構建一個模型系統。構建模型系統的關鍵是要有足夠多的數據,數據是核心競爭力。有了數據后要構造出解釋世界的模型。拓數派團隊既具備大數據分析的豐富經驗,也具備云計算方面的實戰經驗。
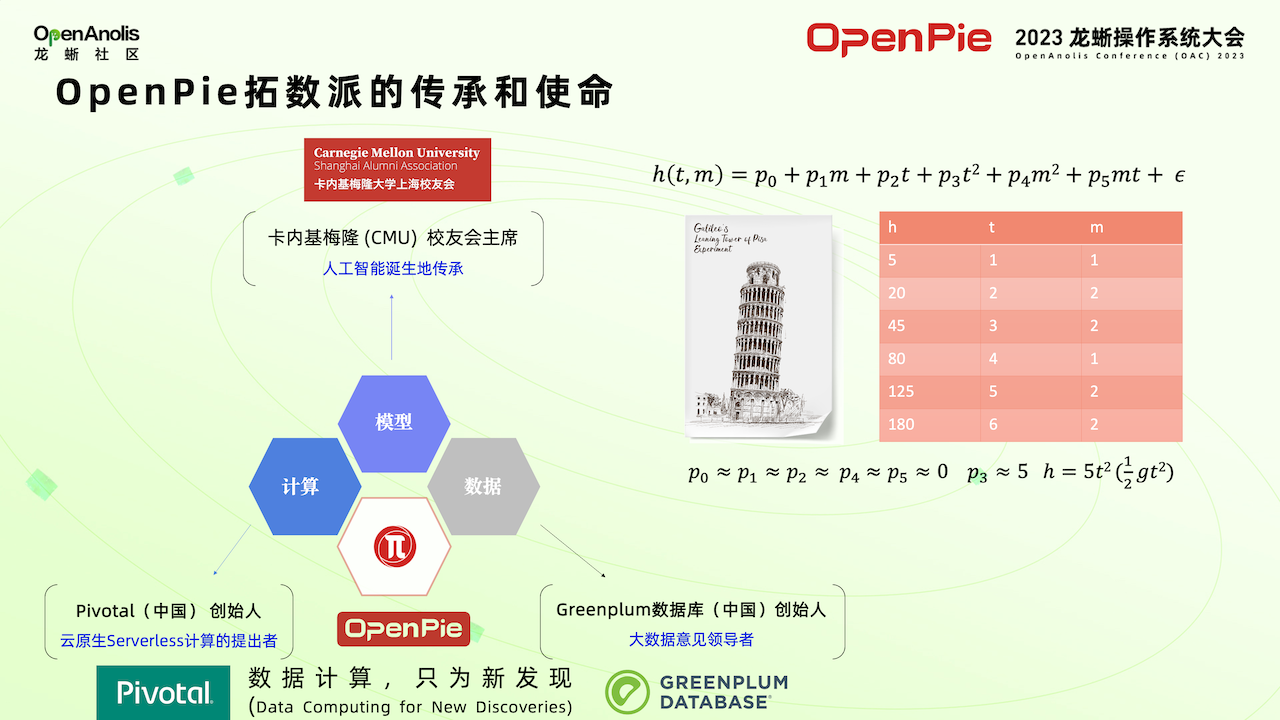
一提到模型可能首先想到有幾千億參數的大模型數據系統,其實日常生活中的模型無處不在。例如自由落體模型,由物理實驗推導而來。最早的物理規律并不是理論推導而成,而是由數據分析得出,例如開普勒行星運動三定律,就是通過分析天文學家幾十年的觀測數據總結得出。以自由落體模型為例,可以考慮物體的自由落體運動以時間和變量為參數。構造這樣簡單的一套模擬系統,通過觀測收集到數據,再經過計算發現 p0、p1 參數都是 0,只有 p3 是5 。經過分析后得出,只有當 p0、p1 值為該值時才符合客觀規律,這就是簡單的模型訓練過程。進行數據分析時,不僅要構造像大模型這種復雜系統,生活中也有很多像自由落體這種模型等待我們發現。
下面是 πDataCS 產品的架構圖。

πDataCS 打造了全新的云原生架構,支持一份數據,多引擎計算。πDataCS 支持多種云平臺,包括公有云和私有云。πDataCS 以云原生技術重構數據存儲和計算,先將數據計算系統中的計算和數據分離,增強系統的彈性。接著,考慮到未來數據治理和交易,拓數派把元數據和用戶數據再次分離,實現了全新的 eMPP 架構。元數據被映射到塊存儲,由元數據管理系統「木牘」進行管理;用戶數據被映射到對象存儲,由「簡墨」存儲系統來管理;計算被映射到容器或者虛擬機,由計算系統來管理。元數據可以在系統中描述數據的結構,找到數據位置。將元數據單獨處理后簡化了數據交換。例如進行黃金交易時不一定一手交錢一手交貨,可以將存儲黃金的保險柜鑰匙交出,此處的保險柜鑰匙就相當于元數據管理系統,避免了數據遺漏等風險。此外 πDataCS 還利用 FPGA 硬件加速技術來提高對數據文件的訪問。
目前,πDataCS支持三種計算引擎:
- PieCloudDB: 作為拓數派首款云原生數倉計算引擎,支持 SQL 語言模型,兼容 HTAP
- PieCloudVector: 為支持和大模型配合的向量計算而建立的云原生向量計算引擎
- PieCloudML: 為支持 Python 和 R 等機器學習語言而建立的云原生機器學習引擎
πDataCS 的第一個優勢是全面升級 Hadoop 大數據和 Greenplum 數倉至云原生數據平臺。打造 πDataCS 是為了全面升級用戶的數據平臺。曾經談到大數據時一定會提到 Hadoop,隨著時間發展,人們發現 Hadoop 的很多問題,但很多用戶的大數據系統還是基于 Hadoop 實現。自從 Hadoop 之后出現很多大數據技術,但只能解決一部分數據問題。例如 MPP 數據庫,主要為了處理關系型數據,還有 MySQL 數據庫只能處理某一個類型的數據。只有 Hadoop 平臺可以使用它的若干個模塊來處理所有的數據,包括結構化的、非結構化的、文本、圖像等等。同 Hadoop 一樣,πDataCS 和也可以通過一個平臺多種計算引擎來為客戶處理所有數據,包括結構化的、非結構化的、文本、圖像等。

πDataCS 的第二優勢是可以全面支持大語言基礎模型和私域數據結合做垂直應用。拓數派第二款計算引擎 PieCloudVector,是一款可以用于存儲、查詢和分析向量數據(比如特征向量)的向量數據庫。
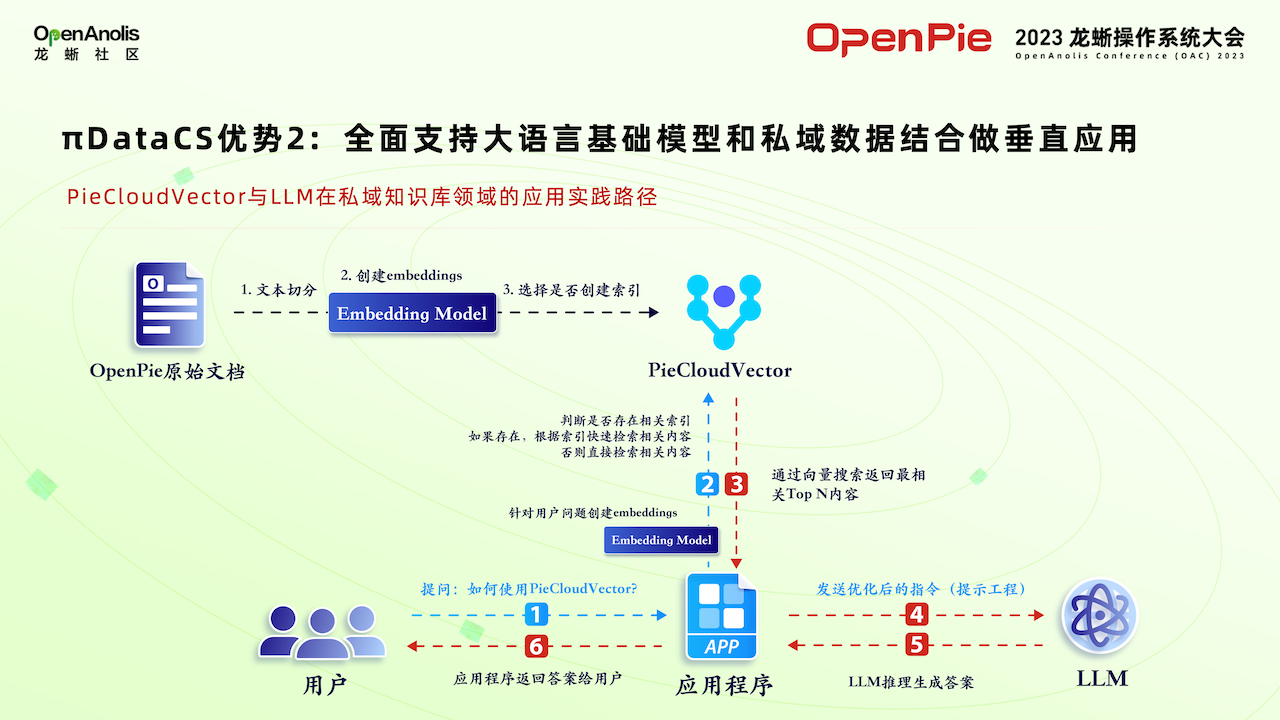
某知名金融客戶積累了很多金融方面的數據,包括各種各業的行業和所投資的各個公司的一些財務數據等,這些是他的核心競爭力。他希望打造一個他私有的大模型系統,使用問答的方式來使用他收集的這些金融方面數據,但是考慮到數據的隱私和安全等,不可能使用公開的大模型。上圖是以 PieCloudVector 為核心,幫助客戶找到了這樣一套私有的金融方面的大模型系統。首先這些文檔使用模型進行提取,將特征存入向量計算 Vector 數據中,再通過架構和他的應用程序進行交互,然后可以使用問答的方式來使用金融數據,也可以使用像大語言模型系統。
πDataCS 的第三個優勢是云原生 eMPP 計算引擎全面顛覆 MPP 技術,打造大模型數據計算新范式。這一優勢是通過第一款計算引擎 PieCloudDB Database 來實現的。
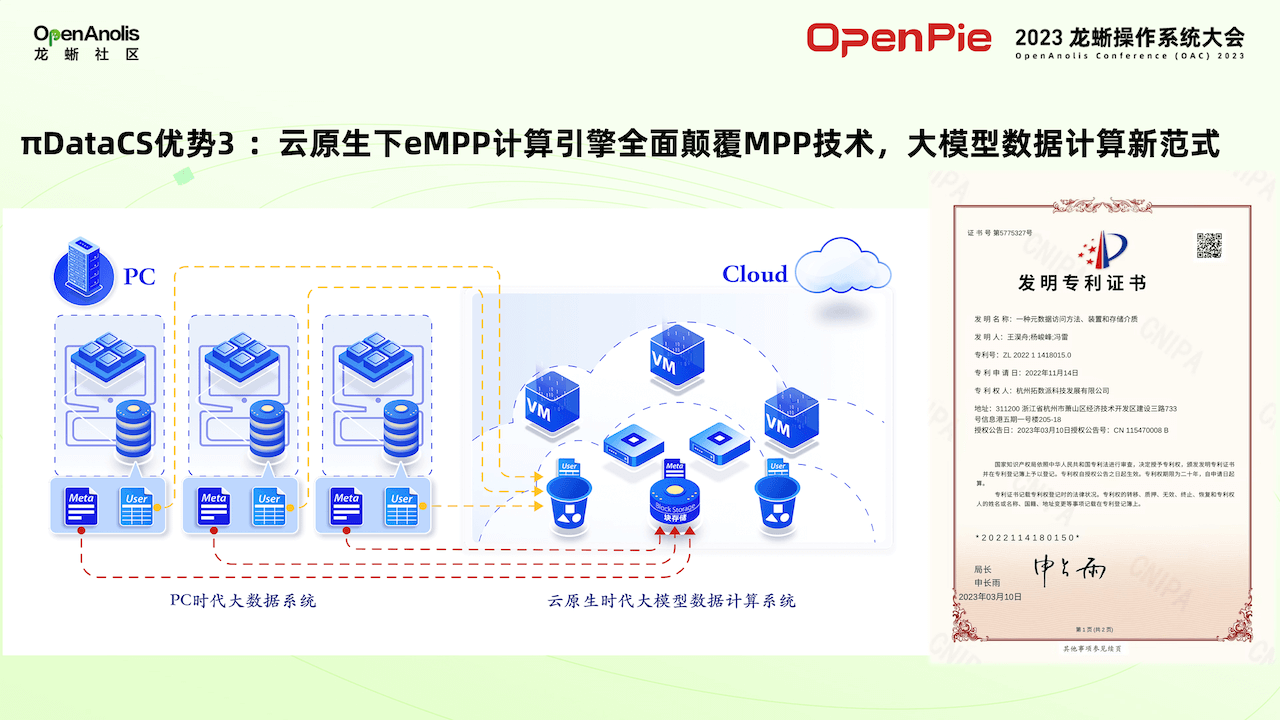
虛擬機技術可以把一臺物理服務器切換成若干臺小的服務器,把它一臺物理服務器的資源切換虛擬機,給不同的用戶來用。同樣我們希望把數倉資源切算成若干的虛擬數倉,然后交給各個部門來使用,提高硬件的使用效率。以上解釋了為什么拓數派團隊要對 PieCloudDB 打造基于云原生的 eMPP 架構。
PieCloudDB 是基于 eMPP 架構的數倉系統,實現了把元數據收集到元數據服務木牘當中,把用戶數據存儲到了簡墨系統中,然后實現了存儲分離的虛擬數倉,實現了元數據、用戶數據和虛擬數倉數據計算之間獨立的擴縮容。使用基于 PC 架構的傳統數倉系統,數據和計算緊緊綁定在一起。可以對它進行橫向的擴展,但是同時必須要擴展存儲,也需要擴展計算,計算和存儲不能進行獨立的擴展。這種架構下需要縮容時操作很困難。通過 PieCloudDB 虛擬數倉,將一個個數倉打造成不包含任何數據而且無狀態的計算平臺。可以根據需要對數倉的計算能力進行擴縮容。

在實際的應用場景中,簡墨系統可以構建在 S3 對象存儲中或者 HDFS 和 NAS 中。
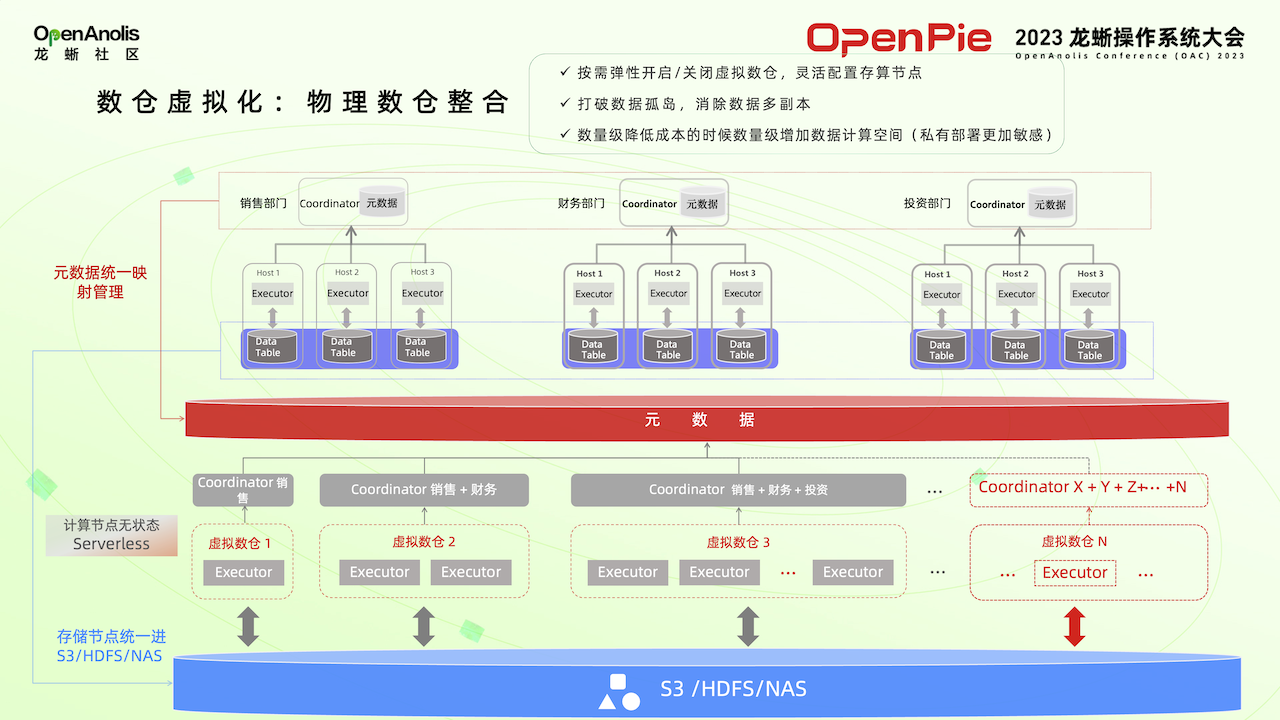
PieCloudDB 通過映射,讓每一個業務部門自己擁有獨立的一套數倉系統,使用起來與傳統 MPP 數據庫沒有太大區別。但各個部門進行數據交換時,不需要再進行 ETL 操作,通過數據授權對元數據進行操作,將不同部門之間的數據映射給其他部門。在存儲系統中,所有數據只存儲了一份。類似前文交換保險柜鑰匙來獲得黃金,而不是真正進行黃金交換。通過虛擬數倉系統,可以降低硬件和管理成本。虛擬化可以提高硬件的使用率,提升數據資源的應用效率,再通過一些技術提高數據安全性。

為了實現虛擬數倉系統,PieCloudDB 完成了四大技術突破。
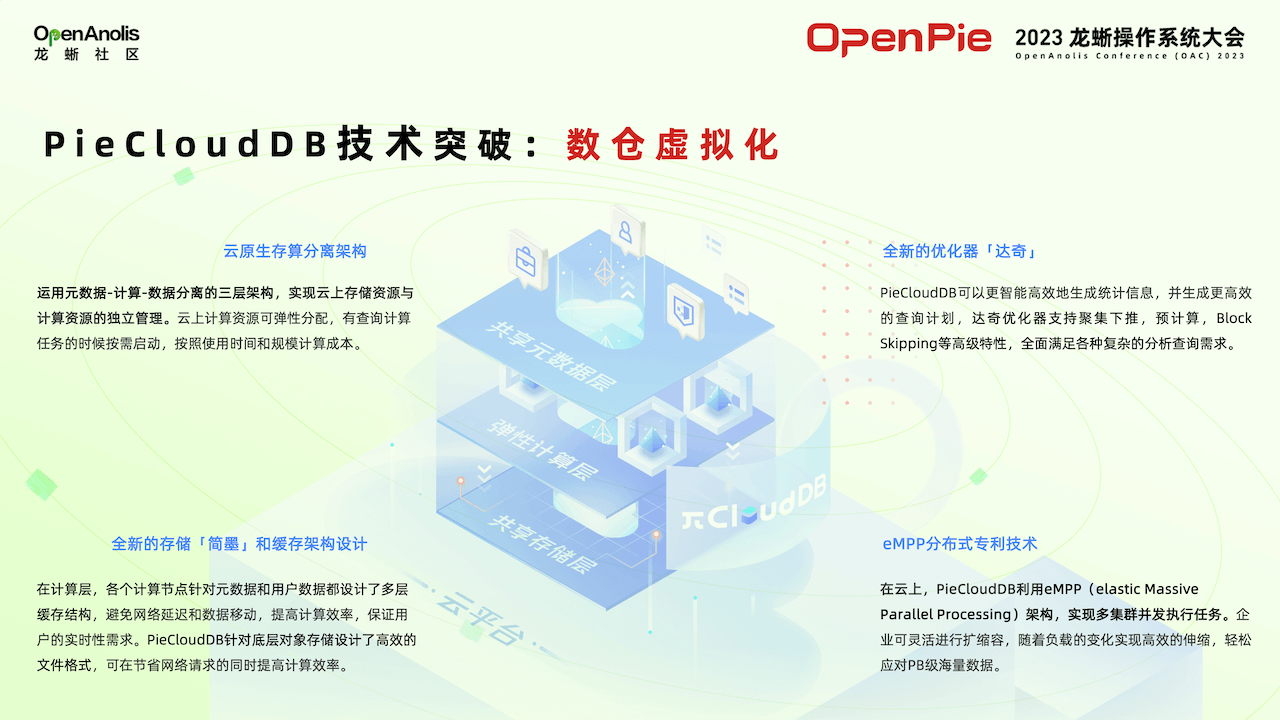
首先,PieCloudDB 實現了云原生存算分離架構:用戶數據,元數據和計算三層分離,可進行獨立擴縮容。第二根據云原生特點打造優化器達奇。云原生優化器負責根據部署 PieCloudDB 架構的特點來生成更優的執行計劃,提高數據分析效率。第三是全新的數據存儲引擎簡墨,還有相關緩存架構設計,提高虛擬數倉訪問數據輸出的效率。第四是 eMPP 分布式技術,為傳統 MPP 架構增加彈性,使虛擬數倉進行橫向的擴容和縮容變得非常方便。
πDataCS 第二款計算引擎PieCloudVector,針對一些像金融、保險這方面用戶,對數據的安全性要求比較高,需要打造一個自己私有的大模型系統。
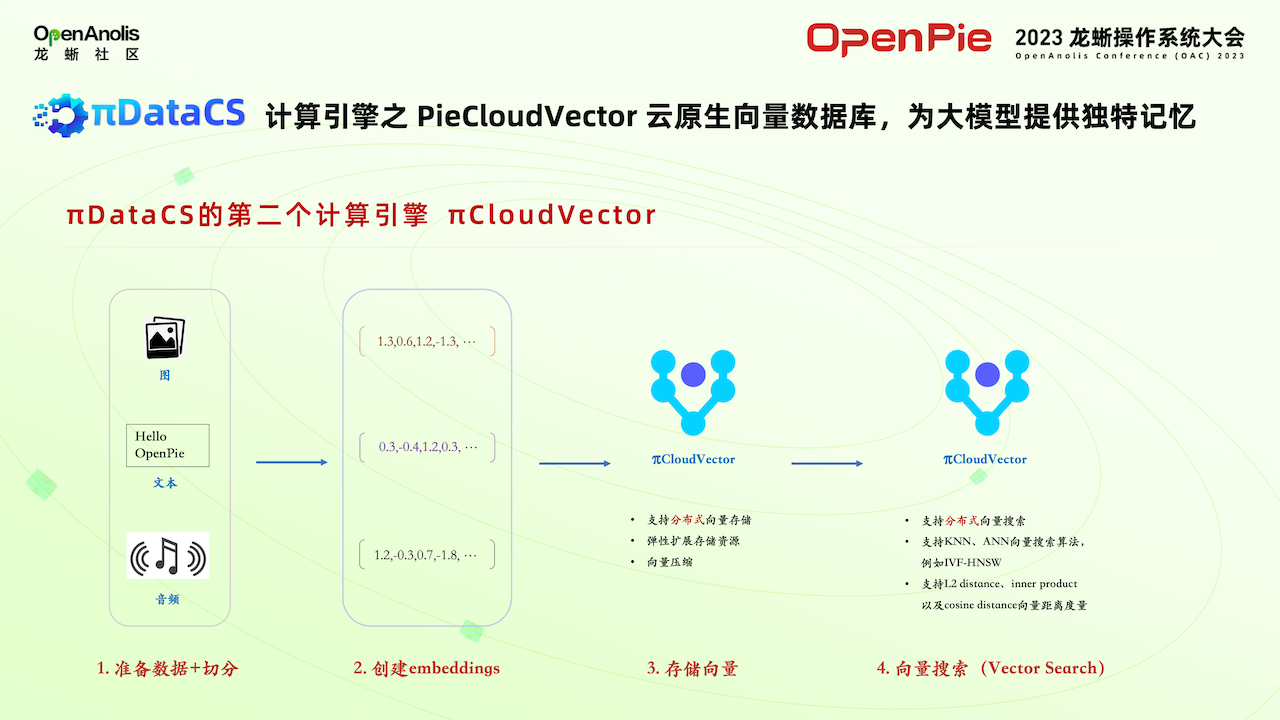
把用戶收集的數據或者是公有的數據,通過特征提取,創建一系列 embeddings,存儲到向量數組中,再通過其他一些開源框架和大模型進行一個交互。相當于 PieCloudVector 為客戶自己構建自有大模型提供存儲底座。相對于其他的向量數據庫,包括一些專用的數據庫,還有傳統的關鍵數據庫有這些向量的插件。
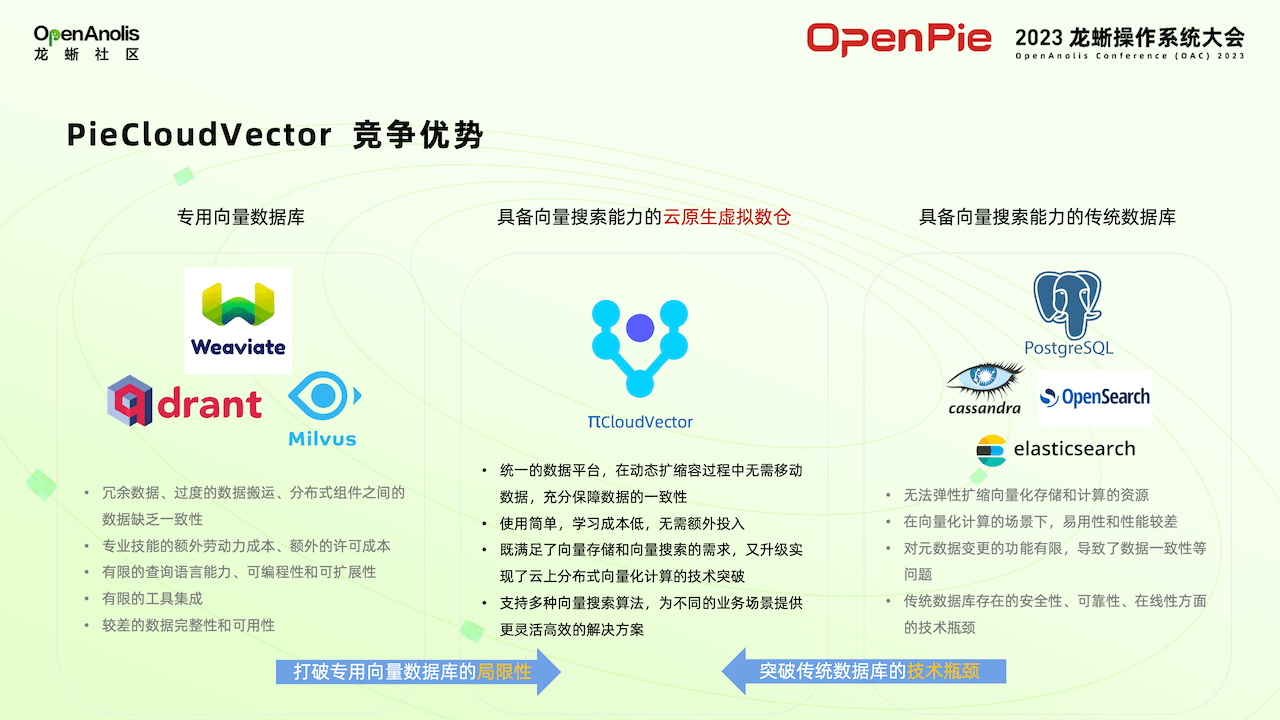
相比這兩種方案,我們這套系統有哪些優勢呢?第一,使用專用的向量數據庫,其他一些相關數據,例如存儲在數據庫中的關鍵型數據等,需要進行若干數據移動。傳統的數據庫在高可用或者擴展方面有缺陷。所以 PieCloudVector 集中了兩方面優勢,比較方便進行水平的擴縮容,第二個同時具有這兩方面的優點,既可以存儲普通的關系型數據,也可以存儲向量數據。
第三款計算引擎是正在開發的新一代(大模型)機器學習 PieCloudML,在現有這些架構的基礎上,通過新一代 PieCloudML,增加機器學習、圖像數據處理等大模型系統提供更深一步的支持。

大模型數據計算系統,面向國內市場提供云上云版、社區版、企業版、一體機四個版本,滿足企業不同業務場景需求。πDataCS 有三種部署方式。第一種直接部署在云上,第二種部署在客戶現有的云平臺,第三種是一體機系統,用戶接上網線,插上電源可以直接使用。
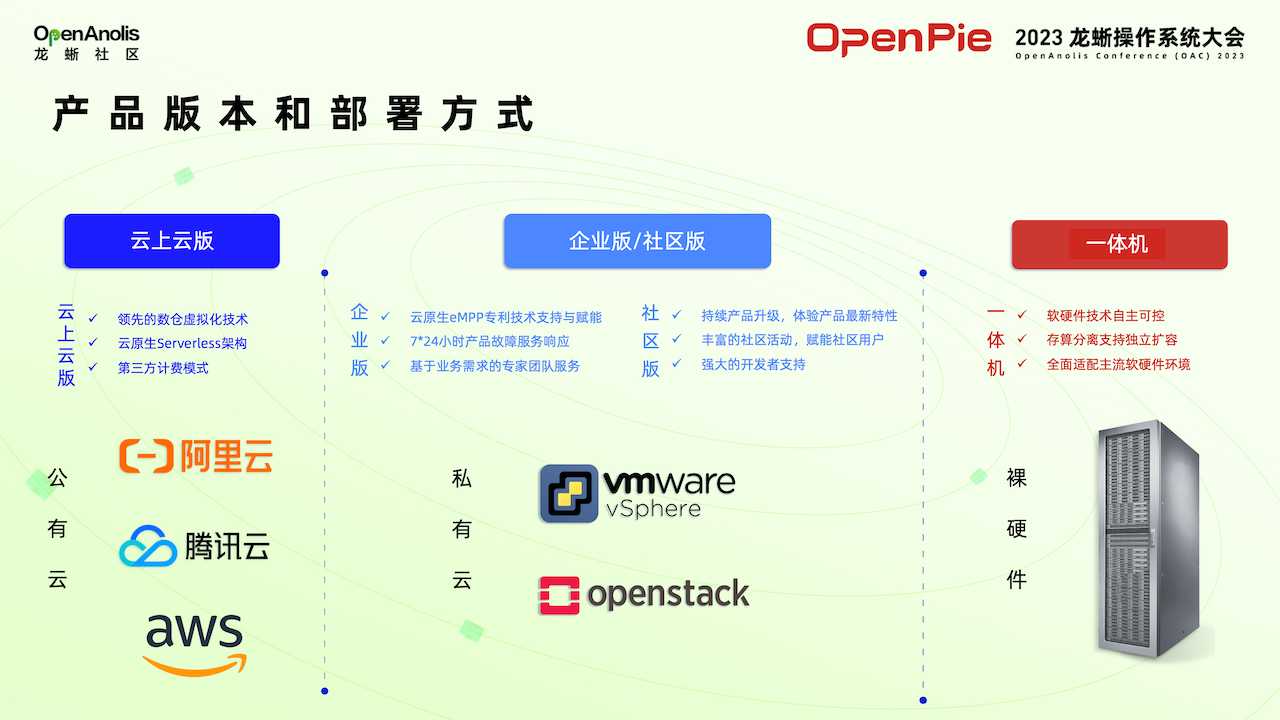
拓數派一直秉持著“開放互信、合作共贏”的理念,致力于構建蓬勃的數據生態。πDataCS 也非常注重軟件生態打造,注重與社區方面的合作。πDataCS 需要適配各種各樣的云環境,所以需要打造強大的軟件生態系統。拓數派團隊針對不同的部署方式與龍蜥平臺進行了全方位的測試,測試結果顯示,龍晰平臺安全穩定、性能優異。因此,我們確信,龍蜥平臺可以支持 πDataCS 良好運行。 除了龍蜥外,πDataCS 也完成了與其他主流軟硬件平臺的適配工作。拓數派將繼續努力,打造完善的產品生態,為用戶提供更安全穩定、高性能、易用的大模型數據計算平臺。








)

)


)





|Day57(動態規劃))
