1. 初識http
?????????HTTP 最新的版本應該是 HTTP/3.0,目前大規模使用的版本 HTTP/1.1;
? ? ? ? 下面來簡單說明一下使用 HTTP 協議的場景:
1、瀏覽器打開網站 (基本上)
2、手機 APP 訪問對應的服務器 (大概率)
????????前面的 TCP與UDP 和http不同,HTTP 的報文格式,主要分兩個部分來看待:請求與響應,因為HTTP 協議,是一種"一問一答"結構模型的協議,同時請求和響應的協議格式,是有所差異的
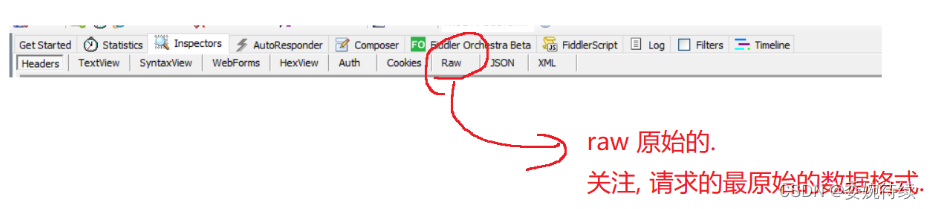
1.1 抓包工具?
1.1.1 下載和安裝fiddler
? ? ? ? 我們如果要查看到 HTTP 請求和響應的格式就需要使用抓包工具,所謂的抓包就是把網卡上經過的數據獲取到,并顯示出來;
? ? ? ? 下面主要學習一下fiddler的下載和使用:
1.1.2? fiddler的介紹
?????????fiddler 打開之后,是一個左右結構的程序,左側有一個列表,列出了抓到的包有哪些,右側則是包的詳情:
點擊某個包后如下圖所示:
????????右側上方,是請求詳情
????????右側下方,是響應詳情:
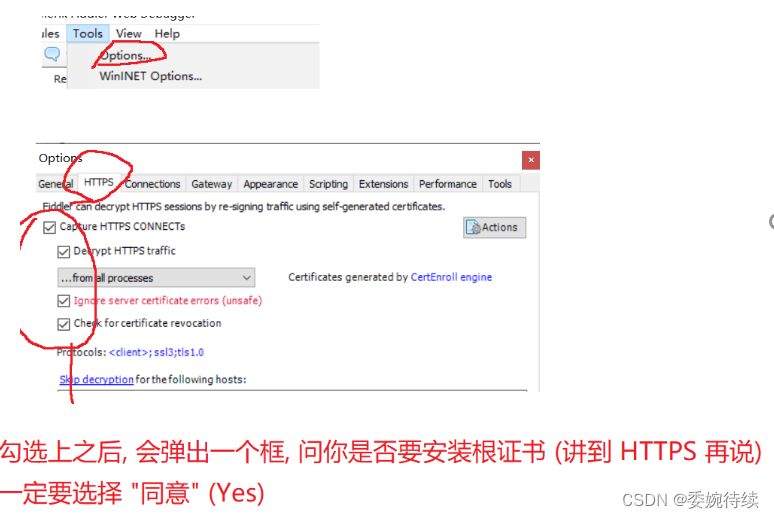
????????新安裝的 fiddler 需要手動開啟 HTTPS 功能,并且安裝證書(否則只能抓 http),主要是因為當前互聯網環境上,HTTPS 為主,純 HTTP 非常少見了,操作如下:

????????Fiddler 本質上是一個"代理”,可能會和其他的代理軟件沖突;?
1.1.3?fiddler 實際使用
? ? ? ?1、 ctrl +a全選所有的請求.,delete 刪除,對于左側fiddler抓到的包,根據不同的顏色來進行簡單的區分:
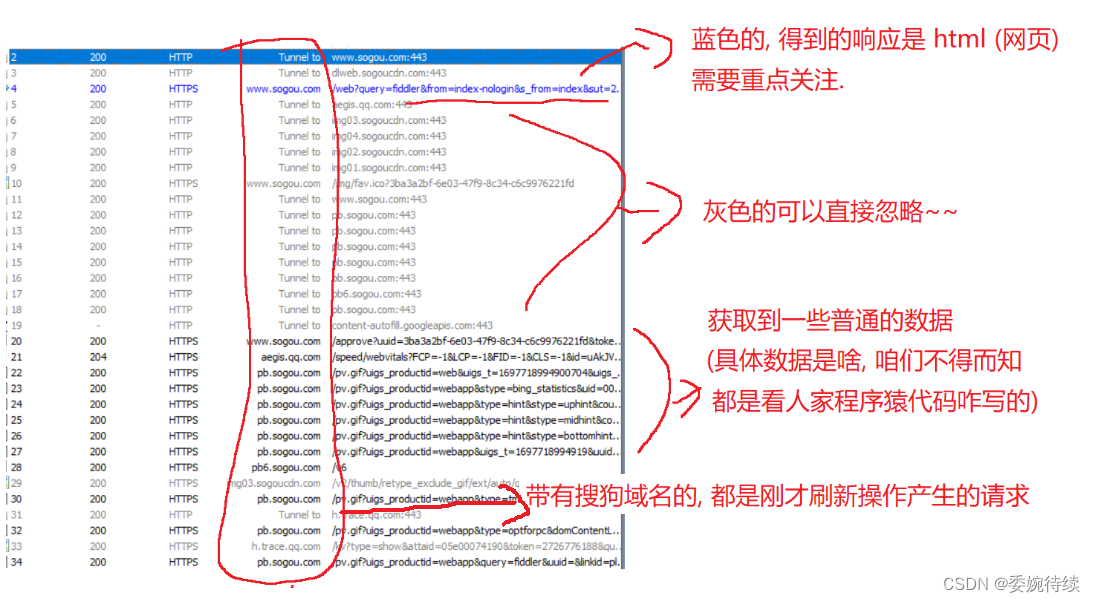
? ? ? ? 當我們打開一個網頁的時候,往往不只是和服務器進行一次操作,大概率是多次操作
? ? ? ?1、關于請求
????????點擊左側抓到的包,之后進行下面操作:
? ? ? ? 點擊如下操作:
? ? ? ? 得到詳細的請求信息:
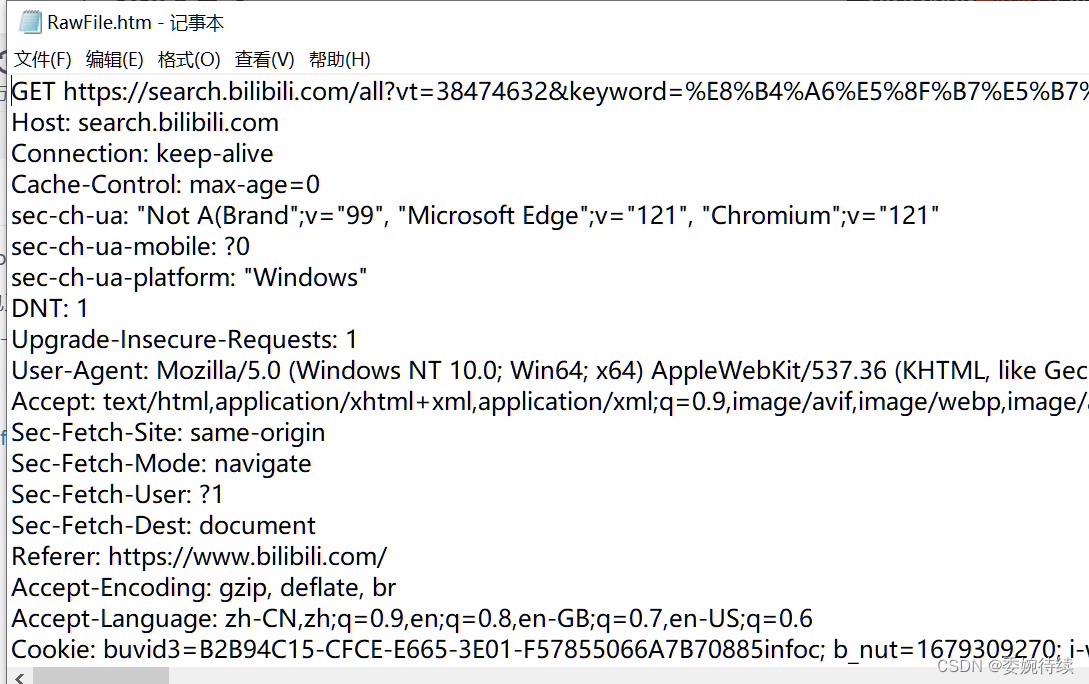
? ? ? ? 這里注意HTTP 協議是文本格式的協議(協議里的內容都是字符串);TCP,UDP,IP... 都是二進制格式的協議
? ? ? ? 2、關于響應
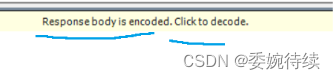
????????HTTP 響應也是文本的.直接査看,往往能看到二進制的數據(壓縮后的);至于HTTP 響應經常會被壓縮,且壓縮之后,體積變小,?傳輸的時候,節省網絡帶寬(臺服務器,最貴的硬件資源, 就是網絡帶寬,但是,壓縮和解壓縮,是需要消耗額外的 cpu 和 時間的)
? ? ? ? 下面進行解壓縮操作:
? ? ? ? 查看響應信息:
????????解壓縮之后,可以看到,響應的數據其實是 html;瀏覽器上顯示的網頁,就是 html,,往往都是瀏覽器先請求對應的服務器,從服務器這邊拿到的頁面數據 (html)

1.2 關于請求和響應
? ? ? ? 請求的格式如下:
1、首行
????????HTTP 請求的第一行,有三個部分信息,三個部分使用空格分割
1) 、GET,?HTTP 請求的"方法”(method)
2)、URL 唯一資源定位符,描述了一個資源在網絡上的位置。
3) 、版本號:HTTP/1.12、請求頭 (header)
????????是一個鍵值對結構的數據.(有很多鍵值對),每個鍵值對, 都是獨占一行的。鍵和值之間,使用 :空格來區分,這里的鍵值對都是屬于"標準規定”的。3、空行
????????請求頭的結束標記4、正文 (body)
????????有的 HTTP 請求有,有的沒有。

? ? ? ? ?響應的格式如下:
1、首行
1)、版本號 HTTP/1.1
2)、狀態碼(200) 描述了請求的結果.
3)、狀態碼描述(OK)2、響應頭 (header)
????????也是鍵值對結構(有多個鍵值對),每個鍵值對獨占一行,鍵和值之間使用 :空格 來區分.
鍵值對也是"標準規定” 的;3、空行
????????響應頭的結束標記4、正文 (body)
????????正文里的內容可能比較長,也可能是多種格式包括HTML, CSS,JS,JSON,XML, 圖片, 字體,視頻,音頻..

1.3 關于URL
?????????URL是計算機中的非常重要的概念,不僅僅是在 HTTP 中涉及到,我們之前學習jdbc的時候就接觸到的,如下所示:

? ? ? ? 同時下面就是對url的詳細講解:

????????#ch1 片段標識符:
????????有的網頁內容比較長,就可以分成多個"片段”,通過片段標識符,就可以完成頁面內部的跳轉;
????????對于 query string 來說,如果 value 部分要包含一些特殊符號的話,往往需要進行 urlencode 操作。主要是因為+?:/. 這些符號在 url 中都已經有特殊用途了,如果在 value 中,也包含特殊符號,可能就會使瀏覽器/http服務器,對于 url 的解析就出現 bug ,urlencode 本質上是一種"轉義字符",+的 ascii 就是 2B, 在前面加上 % 表示這是轉義的結果,即效果如下所示:

2. 深入學習http
2.1 連接請求的方法
????????GET 請求,通常會把要傳給服務器的數據,加到 url的 query string 中;POST 請求,通常把要傳給服務器的數據,加到 body 中.
? ?? ? 1、 關于找到html網頁的分析:
????????藍色字體,是獲取到網頁 (得到 html 的響應),如下所示:
? ? ? ? 首先剛才最開始沒有抓到這里的返回頁面的請求是因為命中了瀏覽器緩存;
? ? ? ? 其次瀏覽器顯示的網頁,其實是從服務器這邊下載的 htnml,htm| 內容可能比較多,體積可能比較大,通過網絡加載,消耗的時間就可能會比較多,瀏覽器一般都會自己帶有緩存,就會把之前加載過的頁面,保存在本地硬盤上,再次訪問就直接讀取本地硬盤的數據即可;
? ? ? ? 2、對于在網頁上上傳圖片進行抓包;
????????上傳頭像的 body 比較長,body 就是圖片本體,圖片本身是二進制數據,此處把圖片放到 http 請求中,往往要進行base64 轉碼,
? ? ? ? 所謂的base64 轉碼,就是針對二進制數據重新編碼(轉義),確保編碼之后的數據就是純文本的數據

2.2 學習http請求的方法
? ? ? ? http的請求方法如下所示:
? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
? ? ? ? 在當前的使用環境中,部分請求方法已經不經常使用了,大部分使用的請求方法只有三個,get,post和put,同時任何使用 POST 的場景,換成 PUT 完全可以;
? ? ? ? q:談一下 GET 和 POST 的區別:
? ? ? ? a:首先,?GET 和 POST 沒有本質區別,(即雙方可以替換對方的)
? ? ? ? ??????其次,雖然沒有本質區別,但是在使用習慣上,還是存在一些差異的:
1、GET 請求通常會把要傳給服務器的數據,加到query string 中;POST 請求則是經常放在?body 中.(使用習慣上最大的差異)(上述情況并非絕對,GET 也可以使用 body, POST 也可以使用 query string.使用的前提是客戶端/服務器都得按照一樣的方式來處理代碼
2、語義上的差異.(雖然語義上 HTTP 的使用是比較混亂的,但是相比之下, GET 和 POST 還是比較明確的),GET 大多數還是用來獲取數據,POST 大多數還是用來提交數據 (登錄 + 上傳)
????????GET 和 POST 之間的差別,有些說法,需要大家來注意:
1、?GET 請求能傳遞的數據量有上限, POST 傳遞的數據量沒有上限.
? ? ? ? 這是錯誤的,這個說法是一個"歷史遺留"問題,早期版本的瀏覽器(硬件資源非常匱乏),針對 GET 請求的 URL 的長度做出了限制,實際上,RFC 標準文檔中并沒有明確規定 URL 能有多長。目前的瀏覽器和服務器的實現過程中,URL 可以非常長的,(甚至說可以使用 URL 傳遞一些圖片這樣的數據);
2、GET 請求傳遞數據不安全.POST 請求傳遞數據更安全.
? ? ? 依據是:如果使用 GET 請求來實現登錄,點擊登錄的時候,就會把用戶名和密碼放到 url?中,進一步的顯示到瀏覽器的地址欄,會被人看到;?相比之下,POST 則是在 body 中,不會在界面上顯示出來,所以就更安全.????????這是錯誤的說法,我們通常所說的“安全”指的是我們傳遞的數據,不容易被黑客獲取或者被黑客獲取到之后,不容易被破解,所謂密碼的安全性安全性,和 post 無關.關鍵在于是否加密,能否被人獲取之后破譯出來;
3、GET 只能給服務器傳輸文本數據,POST 可以給服務器傳輸文本和二進制數據
? ? ? ? 這是錯誤的;
1)、GET 也不是不能使用 body (body 中是可以直接放二進制的)
2) 、GET 也可以把二進制的數據進行 base64 轉碼,放到 url 的 query string 中4、GET 請求是冪等的.POST 請求不是冪等的.[不夠準確, 但是也不是完全錯]
? ? ? ? 所謂冪等 ,就是輸入相同的內容,輸出是穩定的,
????????GET 和 POST 具體是否是冪等,取決于代碼的實現,GET 是否冪等,也不絕對.只不過 RFC 標準文檔,建議 GET 請求實現成冪等的;
5、GET 請求可以被瀏覽器緩存,POST 不可以被緩存(冪等性的延續. 如果請求是冪等, 自然就可以緩存)
6、.GET 請求可以被瀏覽器收藏夾收藏,POST 不能 (收藏的時候可能會丟失 body)
2.3?認識 Header
????????Header 里的鍵值對是很多的.下面主要是挑幾個重要的介紹一下;
Host:服務器所在的ip和端口號
????????即Host:www.bilibili.com,這個信息在url中也存在,但是在使用代理的情況下,Host的內容是可能和url中的內容是不一樣的;
content-Length:body中數據的長度
Content-Type:body 中數據的格式
????????請求里有 body,才會有這兩個屬性.通常情況下 GET 請求沒有 body; POST 請求有 body;
? ? ? ? 由于TCP 涉及到粘包問題,HTTP 在傳輸層就是基于 TCP 的。使用同一個 TCP 連接傳輸多個 HTTP 數據包,就會使多個 HTTP 數據包在 TCP 接收緩沖區中挨在一起,接收方解析的時候,就需要能夠清楚 HTTP 數據包之間的邊界;對于 GET 這種沒有 body 的請求,直接使用空行(分隔符),對于post這種有 body 的請求,就結合空行和content-Length;
? ? ? ? body 中的格式,可以選擇的方式是非常多的,如下所示:
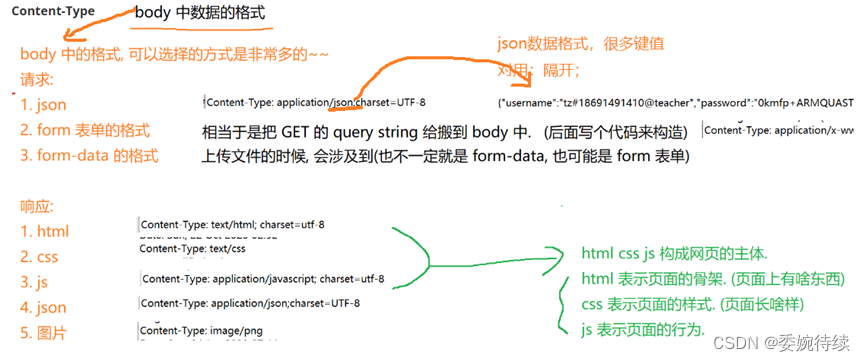
????????后續給服務器提交給請求,不同的 Content-Type,服務器處理數據的邏輯是不同的;服務器返回數據給瀏覽器,也需要設置合適的 Content-Type,瀏覽器也會根據不同的 Content-Type 做出不同的處理;
2.4?User-Agent(簡稱 UA)

????????上古時期,網頁非常簡單,就只是一些單純的文字,瀏覽器功能也比較原始.后來,網頁內容越來越豐富了,瀏覽器的功能也開始逐漸升級.
????????這個升級過程也是很快的.(新的瀏覽器出現的很快),新的瀏覽器誕生之后,并不是立即就占據全部市場.相當一部分時間里,新瀏覽器和舊瀏覽器是并存的;網站的開發者就遇到困難了,網站開發者就需要考慮到是否要兼容舊版本瀏覽器;事實上,就可以使用 User-Agent 來進行區分的.UA 中記錄了瀏覽器的版本. 哪個版本的瀏覽器都支持哪些特性,哪些特性是容易獲取的,網站開發者就可以看看 UA 里的內容;
????????現在,瀏覽器之間的差異非常小了.此時的UA 的作用就沒那么關鍵了,所以UA主要是用來區分 PC端還是移動端。
ps:本次的學習內容就到這里了,如果大家感興趣的話就請一鍵三連哦!!!



)

:關鍵詞搜索)

可行性分析)




----------Apache相關配置與優化)
)

可行性分析)



