什么是緩存雪崩
通常我們為了保證緩存中的數據與數據庫中的數據一致性,會給 Redis 里的數據設置過期時間,當緩存數據過期后,用戶訪問的數據如果不在緩存里,業務系統需要重新生成緩存,因此就會訪問數據庫,并將數據更新到 Redis 里,這樣后續請求都可以直接命中緩存。
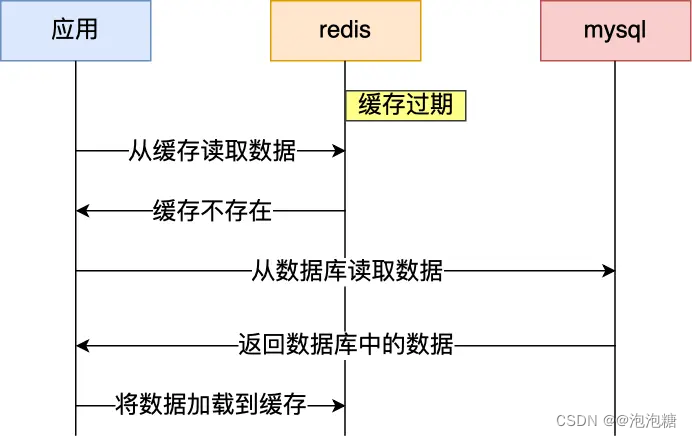
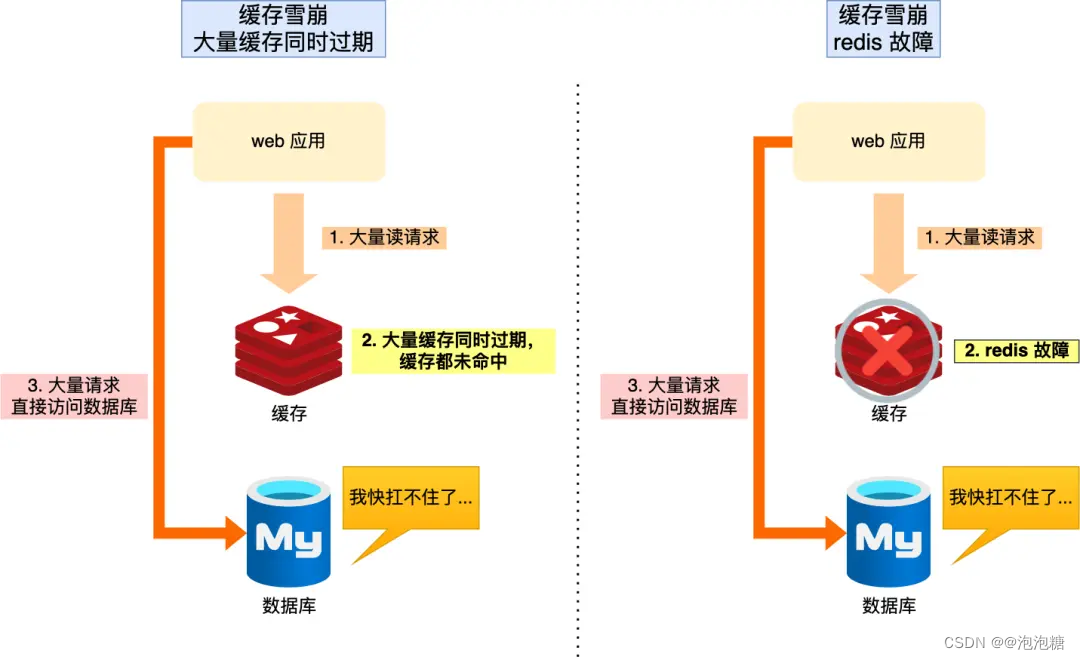
那么,當大量緩存數據在同一時間過期(失效)或者 Redis 故障宕機時,如果此時有大量的用戶請求,都無法在 Redis 中處理,于是全部請求都直接訪問數據庫,從而導致數據庫的壓力驟增,嚴重的會造成數據庫宕機,從而形成一系列連鎖反應,造成整個系統崩潰,這就是緩存雪崩的問題。
緩存雪崩的原因
可以看到,發生緩存雪崩有兩個原因:
- 大量數據同時過期;
- Redis 故障宕機;
不同的誘因,應對的策略也會不同。
大量數據同時過期
針對大量數據同時過期而引發的緩存雪崩問題,常見的應對方法有下面這幾種:
- 均勻設置過期時間;
- 互斥鎖;
- 后臺更新緩存;
1. 均勻設置過期時間
如果要給緩存數據設置過期時間,應該避免將大量的數據設置成同一個過期時間。我們可以在對緩存數據設置過期時間時,給這些數據的過期時間加上一個隨機數,這樣就保證數據不會在同一時間過期。
2. 互斥鎖
當業務線程在處理用戶請求時,如果發現訪問的數據不在 Redis 里,就加個互斥鎖,保證同一時間內只有一個請求來構建緩存(從數據庫讀取數據,再將數據更新到 Redis 里),當緩存構建完成后,再釋放鎖。未能獲取互斥鎖的請求,要么等待鎖釋放后重新讀取緩存,要么就返回空值或者默認值。
實現互斥鎖的時候,最好設置超時時間,不然第一個請求拿到了鎖,然后這個請求發生了某種意外而一直阻塞,一直不釋放鎖,這時其他請求也一直拿不到鎖,整個系統就會出現無響應的現象。
3. 后臺更新緩存
業務線程不再負責更新緩存,緩存也不設置有效期,而是讓緩存“永久有效”,并將更新緩存的工作交由后臺線程定時更新。
事實上,緩存數據不設置有效期,并不是意味著數據一直能在內存里,因為當系統內存緊張的時候,有些緩存數據會被“淘汰”,而在緩存被“淘汰”到下一次后臺定時更新緩存的這段時間內,業務線程讀取緩存失敗就返回空值,業務的視角就以為是數據丟失了。
解決上面的問題的方式有兩種。
第一種方式,后臺線程不僅負責定時更新緩存,而且也負責頻繁地檢測緩存是否有效,檢測到緩存失效了,原因可能是系統緊張而被淘汰的,于是就要馬上從數據庫讀取數據,并更新到緩存。
這種方式的檢測時間間隔不能太長,太長也導致用戶獲取的數據是一個空值而不是真正的數據,所以檢測的間隔最好是毫秒級的,但是總歸是有個間隔時間,用戶體驗一般。
第二種方式,在業務線程發現緩存數據失效后(緩存數據被淘汰),通過消息隊列發送一條消息通知后臺線程更新緩存,后臺線程收到消息后,在更新緩存前可以判斷緩存是否存在,存在就不執行更新緩存操作;不存在就讀取數據庫數據,并將數據加載到緩存。這種方式相比第一種方式緩存的更新會更及時,用戶體驗也比較好。
在業務剛上線的時候,我們最好提前把數據緩起來,而不是等待用戶訪問才來觸發緩存構建,這就是所謂的緩存預熱,后臺更新緩存的機制剛好也適合干這個事情。
)





函數)

)

)






)

