前言
? ?StarRocks-2.0引入了低基數全局字典,可以通過全局字典將字符串的相關操作轉換成整型相關操作,極大提升了查詢性能。StarRocks 2.0+后的版本默認會開啟低基數字典優化。
一、低基數字典
? ? 對于利用整型替代字符串進行處理,通常使用字典編碼進行優化。一個 SQL 從輸入到輸出結果,往往會經過這幾個步驟,幾乎每一個階段都可以使用字典優化:Scan,Filter,Agg,Join,Shuffle,Sort。以 Filter為例:
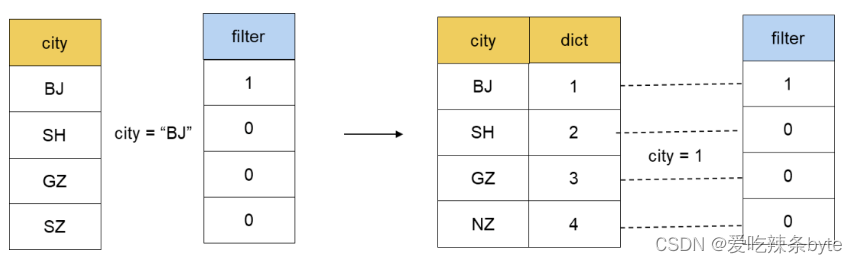
? ?對于 Filter 階段來說,如果某一個列是用字典編碼的,我們就可以直接使用編碼之后的整數進行比較,而不是直接用 String 進行比較操作。大多數情況下,整數之間的 Compare 性能會高于字符串之間的性能。
二、全局字典
??分布式執行引擎中,一個查詢可能會涉及多個機器多個任務之間數據交換。因此執行過程中需要保證字典全局性。字典數據始終貫穿?SQL 執行的整個生命周期,如果不是全局字典,那么加速只能在局部進行。例如如果兩個執行節點的字典編碼不一致,那么在網絡傳輸過程中需要同時把字典傳給對端機器,或者是需要提前把字典碼轉為字符串再通過網絡發送。StarRocks中有全局字典,各個節點之間共享同一個字典,那么就不需要發送后再進行解碼并轉換字典碼了。StarRocks 2.0+后的版本默認會開啟低基數字典優化。
三、全局字典構建
3.1?建表時定義
?用戶在建表的時候,指定對應的列為低基數列。?
?這種方式對用戶不友好,并且不易維護
ps:低基數列:取值區分度小的字段,例如性別,婚姻狀態等。StarRocks支持對低基數列創建Bitmap位圖索引來加速數據查詢。(高基數列:例如UserID)
3.2 導入時構建全局字典?
? ? 導入數據時,通過中心節點維護全局字典。每次遇到新的的字符都要通過中心節點創建一個新的字典碼。但是這么做的主要問題是中心節點很容易會成為瓶頸。另外中心節點因為需要同時處理維護并發控制。
3.3?StarRocks 全局字典的構建
3.3.1 數據存儲上的字典優化?
? ? 先回顧下?StarRocks的數據存儲的結構。?StarRocks的底層存儲單元為Segment,每個Segment 的存儲結構(簡易版)如下:

? ?StarRocks 的存儲結構天然為低基數字符串做了字典編碼。對于 Segment 上的低基數字符串列會有以下特點:
-
Footer上會存儲有這個Column 特有的字典信息,包括字典碼跟原始字符串之間的映射關系;
-
Data page 上存儲的不是原始字符串,而是整數類型的字典碼(整型)。

? ?當處理低基數?String column 的時候,直接使用編碼后的字典碼,而不是直接處理原始的 String 值。當需要原始的 String 值時,使用字典碼就可以很方便地在這個列的字典信息里面拿到原始 String 值。這么做帶來的明顯好處是:(1)減少了磁盤IO;(2)可以提前做一些過濾操作,提升處理速度。
3.3.2 全局字典的構建
? ?StarRocks 支持 CBO 優化器,并且存在一套統計信息機制,那么就可以通過統計信息來收集全局字典。我們通過統計信息,篩選出潛在的低基數列,再從潛在的低基數列的元數據中讀取字典信息,然后做去重/編碼操作,就可以收集到全量的字典了。
3.3.3 ?低基數String優化的特點
? 總結,StarRocks 的低基數String 優化,主要的特點有:
全局的字典加速,作用于 SQL 執行的各個階段。
不需要用戶通過 Schema 指定特定低基數列,而是基于CBO 優化器,自動選擇全局字典的加速策略。
四、使用 auto increment列構建全局字典
? ?這部分主要介紹【使用 auto increment 列構建全局字典以加速精確去重計算和 join】。
參考文章:
滴滴 x StarRocks:極速多維分析創造更大的業務價值-騰訊云開發者社區-騰訊云
國產數據庫-內核特性-低基數全局字典
StarRocks 技術內幕 | 基于全局字典的極速字符串查詢




![代碼隨想錄算法訓練營第二十四天 | 回溯算法理論基礎,77. 組合 [回溯篇]](http://pic.xiahunao.cn/代碼隨想錄算法訓練營第二十四天 | 回溯算法理論基礎,77. 組合 [回溯篇])
![[WebDav] WebDav基礎知識](http://pic.xiahunao.cn/[WebDav] WebDav基礎知識)

)






)



