ChatGPT等大型語言模型在自然語言處理領域表現出色。但有時候會表現得過于自信,對于無法回答的事實問題,也能編出一個像樣的答案來。
這類胡說亂說的答案對于醫療等安全關鍵的領域來說,是致命的。

為了彌補這一缺陷,研究者們提出了檢索增強技術,通過引入外部知識源來減少模型的錯誤信息。然而,頻繁的檢索不僅增加開銷,還可能引入不準確或誤導性的信息。
因此,檢索的時機就變得很重要了。如果僅在LLMs對問題感到不確定時進行檢索檢索,將大大提高效率。
但是新問題又來了,如何讓過度自信的LLMs誠實的表達出“我不知道”呢?
中科院計算所的研究團隊對此進行了深入研究,定量評估了大型語言模型對知識邊界的感知能力,并發現它們確實存在過度自信的問題。團隊進一步探討了模型對問題確定性與外部檢索信息依賴之間的關系,并提出了幾種創新方法來增強模型對知識邊界的感知,從而減少過度自信。
這些方法不僅有助于提升模型的性能,還能在減少檢索調用次數的同時,實現與傳統檢索增強相當甚至更好的效果。
論文標題:
When Do LLMs Need Retrieval Augmentation? Mitigating LLMs’ Overconfidence Helps Retrieval Augmentation
公眾號「夕小瑤科技說」后臺回復“When”獲取論文PDF!
1. 衡量模型的自信程度
任務定義
開放領域問答
對于給定問題 和一個包含大量文檔的集合,本文要求LLMs根據語料庫提供問題的答案,而且通過提示 輸出關于答案的確定性 ,這可以描述如下:
![]()
當時, 表示模型認為答案是正確的, 而則意味著相反。
檢索文檔增強LLMs
從語料庫中為給定問題檢索一組相關文檔,利用這些文檔來增強LLMs的知識,表示為:
![]()
利用LLMs的置信度來指導何時進行檢索。其格式為:
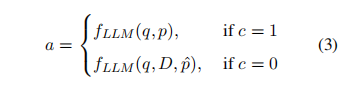
實驗設置
數據集
在兩個挑戰性的開放領域問答基準數據集——自然問題(NQ)和HotpotQA上進行了實驗。NQ數據集基于谷歌搜索查詢構建,包含帶注釋的簡短和長篇答案;HotpotQA則需要多跳推理,數據由亞馬遜 Mechanical Turk 收集。由于HotpotQA難度較高,其檢索增強需求可能與NQ不同。實驗聚焦于NQ測試集和HotpotQA開發集,僅采用帶簡短答案的問題,并將這些答案作為標簽。
評估了五個代表性模型:兩個開源模型(Vicuna-v1.5-7B和LLaMA2-Chat7B)及三個黑盒模型(GPT-Instruct、ChatGPT和GPT-4)。
對黑盒模型,限制最大輸出長度為256個標記,其他參數設為默認值。對開源模型,為求穩定結果,將溫度參數設為0。
指標
本文使用準確性來評估問答性能,若回答與基準答案相符,則視為正確。同時,通過不確定響應的比例(簡稱Unc-rate)來衡量模型的信心水平,比例較低表示模型信心較高。準確性和信心的匹配情況分為四種,相關數據展示在表1中。

▲回答正確與模型置信度之間各種匹配情況下 的樣本計數
為了精準評估模型對知識邊界的感知能力,提出了三個指標。
-
計算Alignment = (Ncc + Niu) / N,可以評估模型的綜合感知水平。
-
使用Overconfidence = Nic / N來衡量模型的過度自信。
-
利用Conservativeness = Ncu / N 來衡量模型的保守性程度。
在計算后兩個指標時,不采用Ncc + Nic和Ncu + Niu作為分母,因為模型的不確定性比例同樣會影響其是否過度自信或保守。
2. LLMs的知識邊界感知
下表展示了LLM在自然問題(NQ)數據集HotpotQA數據集上的問答性能和事實知識邊界知。"Conserv."和"Overconf."分別代表保守性和過度自信。

-
問答性能與LLMs的自信度之間的一致性并不高,即便是最強大的模型GPT-4也顯示出過度自信的特點。以NQ為例,GPT-4正確回答的問題占比不到49%,然而卻有高達18.94%的情況錯誤地確認其答案正確。
-
過度自信的問題比保守性更為嚴重,這表明模型對知識邊界的不清晰感知主要源于其過度自信。
-
模型的準確性與知識邊界感知之間并沒有明顯的相關性。換句話說,準確性更高的模型可能具有較低的一致性。這意味著對對話數據的進一步訓練可能會提升模型對知識邊界的感知,但同時也可能會降低其問答性能。
3. 模型對外部信息依賴的程度
在檢索增強下,我們需要了解LLMs何時對問題表現出不確定性,以及它們是否會利用提供的外部信息。
實驗設置
通過兩種不同的提示模板如下圖所示,引導模型在正確回答問題同時輸出對答案的把握程度,并根據這兩個響應,將置信度分為四個級別。

▲一般模板

▲
如果模型兩次都表達出不確定,這表明缺乏自信,而兩次都表達出確定則表明模型高度自信。這四個置信度級別如下界定:級別0:c = 0, c? = 0;級別1:c = 0;級別2:c = 1;級別3:c =1, c? = 1。置信水平從級別0遞增到級別4。
增強文檔類型
本文著重關注兩種類型的支持文檔之間的關系:
-
黃金文檔:使用DPR檢索增強得到的真實文檔,其中包含問題的真實答案,有1691個帶有黃金文件的問題。
-
腐敗文檔:只是將文件中正確答案替為“Tom”,其他部分與黃金文檔相同。
提示模板
要求模型自行決定是依靠其內部知識還是依賴于檢索文檔來回答問題。提示模板如下圖所示:

評估指標
測試模型包括LLaMA2、GPT-Instruct和ChatGPT,并通過兩個指標評估結果:
-
利用率Utilization Ratio:對于給定的問題和文檔,以及無增強的響應和帶增強的響應。如果,則推斷模型依賴于文檔。其中γ為閾值,文本設為0,Overlap代表文檔之間的重疊程度。
-
錯誤率Corruption Rate:無增強的響應正確而帶增強的響應錯誤的問題百分比。
利用率用于黃金文件,錯誤率用于腐敗文檔。雖然依賴黃金文檔并不等同于答案的準確性,因為模型可能參考了文檔的其他部分,但答案與文檔之間的重疊增加仍然是一個重要指標。相比之下,當模型依賴腐敗文件時,生成錯誤答案的概率顯著提高。
因此,如果模型在本來應該回答正確的問題上給出了錯誤的答案,則認為它是過度依賴了文檔。
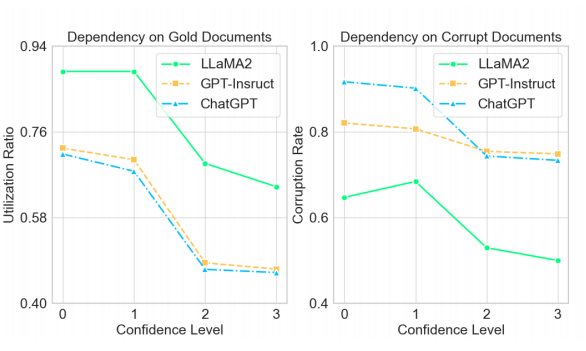
實驗結果
-
隨著置信度的提高,所有模型在文檔依賴性方面都表現出下降。這表明當語言模型表達不確定性時,它們傾向于更多地依賴外部文檔。
-
總體上,無論文檔是否包含正確答案,LLMs對文檔的依賴性都相當高。這意味著LLMs傾向于信任輸入內容,因此在利用檢索增強時特別需要謹慎,尤其是當檢索器表現不佳時。
4. 提升知識邊界感知的方法
上文得出LLM對知識邊界的認知不足主要是由于它們過于自信所致。因此,通過減輕過度自信可以增強對知識邊界的認知。分別從敦促LLM謹慎行事,以及提高模型提供正確答案的能力兩大方面入手。
1. 敦促LLM謹慎行事
為了減少大型語言模型(LLMs)的過度自信,研究提出了三種策略:
-
懲罰Punish:通過在提示中加入“如果回答不正確但你確定的話,你將會受到懲罰”,鼓勵模型在給出確定答案前更加謹慎。

-
挑戰Challenge:對生成的答案的正確性提出疑問,迫使模型表達更多的不確定性。

-
Think Step by Step:明確要求模型逐步思考,先回答問題,然后在下一步輸出自信度。希望當要求逐步思考時,模型能認識到自己的過度自信。

2. 提高正確答案能力:Generate和Explain
為了提高LLMs給出正確答案的能力,研究提出了Generate和Explain兩種方法。
-
生成Generate:讓模型自己生成一份有助于回答問題的短文檔,從而提高回答的準確性。

-
解釋Explain:在提供答案之前要求模型解釋其答案的原因,這樣不僅可以獲得輔助信息,還可能通過要求模型解釋答案來減少沒有合理解釋的錯誤回答的風險。

3.兩者結合
為了結合謹慎和增強問答性能的概念,本文還將懲罰和解釋方法合并為一種方法,稱為懲罰+解釋。

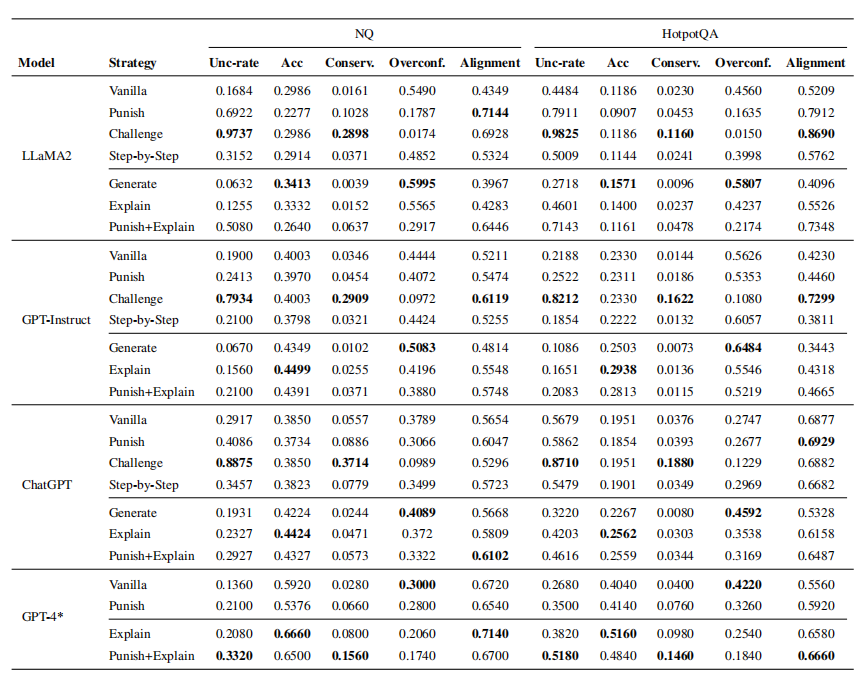
實驗結果
-
挑戰方法顯著提高了不確定響應比例并降低了過度自信,表明LLMs易過度相信輸入并削弱自身判斷。
-
懲罰方法減少了過度自信,避免過度保守,通常能改善答案對齊度。
-
逐步思考方法在NQ上有效,但在HotpotQA上加劇了過度自信,效果有限。
-
生成方法產生最高過度自信分數,因為LLMs依賴生成的文檔,導致過度自信。
-
解釋方法通常減少過度自信,保持較低保守水平,增強LLMs對知識邊界的認識。ChatGPT在HQ數據集上過度自信最低,難以進一步提高準確性。
-
結合謹慎性和QA性能概念,本文結合Punish+Explain方法,提高了對齊性而不影響準確性。
-
所有促使模型謹慎的方法都導致預期的不確定響應比例增加。
-
提高QA性能的方法旨在增加答案準確性。
-
對于LLaMA2,因其嚴重過度自信和較弱生成能力,懲罰方法非常有效。而GPT-4因較低過度自信和強大生成能力,解釋方法非常有效。
5. 自適應檢索增強(Adaptive Retrieval Augmentation)
本文主要是確定何時進行檢索,而不是一直觸發檢索,同時增強LLMs利用未知質量文檔的能力。因此結合懲罰+解釋的方法,開展自適應檢索增強研究。
實驗設置
本文在兩種設置下進行檢索增強:
-
靜態檢索增強:對所有問題啟用檢索增強。
-
自適應檢索增強:當模型認為基于其內部知識無法回答問題時,自適應地啟用檢索增強。
實驗中使用了三種類型的支持文檔:稀疏檢索文檔、密集檢索文檔和包含正確答案的黃金文檔。這些文檔分別代表了實際情況的下限和上限。
采用了兩個開放域QA基準數據集:Natural Questions (NQ) 和 HotpotQA,以及五個不同的模型,包括兩個開源模型和三個黑盒模型。
實驗使用的提示(prompts)包括Vanilla、Punish、Explain和Punish+Explain四種。
實驗結果

-
對于自適應檢索增強,Punish+Explain 方法在大多數情況下取得了最佳結果。
-
自適應檢索增強僅利用最小數量的檢索嘗試就取得了與靜態增強的性能相當甚至更好的效果索嘗試。
-
當利用稀疏檢索器檢索的文檔時,靜態增強在NQ上性能出現下降。這是因為檢索提供低質量的文檔誤導了模型。相比之下,自適應檢索增強可以減少性能損失。
-
Explain策略在大多數場景下獲得了最高準確性,該方法本質上增強了性能并且具有相對較小的不確定率。
-
在使用黃金文檔進行增強時,靜態增強在幾乎所有情況下均實現了最高準確性。這表明包含答案的文檔通常有助于回答問題。
-
自適應檢索增強使LLMs對不相關的文檔更加穩健。
-
在實際搜索場景中,Explain和Punish+Explain策略比靜態增強更高效,當文檔有助于提高準確率時,這些策略通常能夠實現與靜態增強相當或更好的性能,同時需要更少的檢索嘗試。
6. 結論
在本研究中 提出了一系列方法來減輕大型語言模型的過度自信問題,并通過這些方法增強了模型對知識邊界的感知,從而提高了檢索增強的效果。
局限與未來探索方向:
本文將模型對其回答的置信度劃分為兩個組成部分,沒有進一步細化。未來的研究可以探索更細粒度的置信度劃分,以更精確地理解和指導模型的行為。
另外本文通過提示來減輕LLMs的過度自信,這可能對于那些過度自信程度特別高的模型(例如Vicuna-v1.5-7B)的調整有限。對于開源模型,可能存在更有效的訓練方法。此外,我們的研究主要集中在LLMs對其事實知識邊界的感知水平上,而對于不同類型知識的知識邊界感知仍有待研究。
公眾號「夕小瑤科技說」后臺回復“When”獲取論文PDF!



:UpdateError, UpgradeFailure)




)

)







![306_C++_QT_創建多個tag頁面,使用QMdiArea容器控件,每個頁面都是一個新的表格[或者其他]頁面](http://pic.xiahunao.cn/306_C++_QT_創建多個tag頁面,使用QMdiArea容器控件,每個頁面都是一個新的表格[或者其他]頁面)
)

