前言
上周剛來了個應屆小師弟,組長說讓我帶著,周二問了我這樣一個問題:師兄啊,我用top命令看了下服務器的內存占用情況,發現Redis內存占用嚴重,于是我就刪除了大部分不用的keys,為什么內存占用還是很嚴重,并沒有釋放呢?
嗯?為什么呢?今天就帶著這個問題來介紹一下如何正確釋放Redis的內存。
什么是內存碎片?
內存碎片這個概念應該不是第一聽說了,熟悉JVM或者操作系統的應該都熟悉,以火車賣票為例,一個車廂128個車位,由于高峰期,只剩余兩個位置了,但是此時三個人想要坐在一起,能夠吹吹牛批,喝喝酒的,那么這三個人肯定不會買這節車廂的兩個位置了,此時這兩個位置可以稱之為座位碎片 。
操作系統中對于內存分配也是一樣的,比如應用需要申請一塊連續N個字節的空間,雖然剩余內存總量大于N個字節,但是沒有一塊連續的內存空間是N個字節,那么剩余的空間就是內存碎片。如下圖:

上圖中的空閑3個字節和空閑2個字節都是內存碎片。
那么什么原因會造成內存碎片呢?這個其實大致分為兩個原因,一個是操作系統的內存分配策略,一個是Redis自身原因,下面就這兩個原因詳細分析。
內存分配器的分配策略
內存分配器的分配策略一般是按照固定大小來分配內存,而不是按照應用程序申請的內存空間按需分配。比如8字節、16字節、32字節......
Redis提供了多種的內存分配策略,比如libc、jemalloc、tcmalloc,默認使用jemalloc。
jemalloc這種分配策略,是按照固定的空間分配,比如8字節、32字節....2KB、4KB等。當應用程序申請的內存接近某個固定值的時候,jemalloc則會分配固定的大小。比如申請了6字節,則會分配8字節的空間。
這種分配的方式的好處很明顯,則會減少內存分配的次數,比如申請了20字節的內存,實際分配的是32字節的內存空間,當應用再寫入10字節的數據時,則不會再次分配,剩余的12字節足夠用了。這樣就避免了一次的內存分配。如下圖:
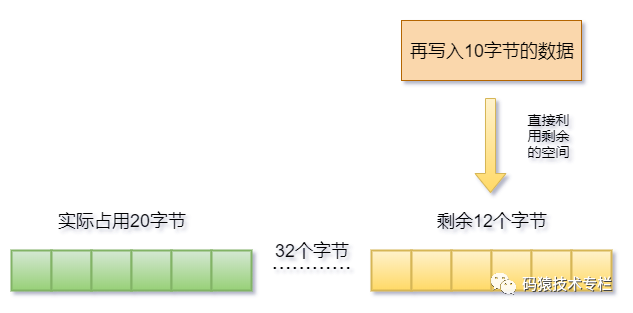
但是壞處也很明顯,申請的和分配的空間不一樣,則剩余的空間很可能形成內存碎片,一旦內存碎片多了,內存利用率也會隨之降低,這是很可怕的。
Redis自身的原因
Redis作為鍵值對存儲的數據庫,本身鍵值對的大小就是不確定的,正如上面的例子中,Redis申請了20字節的空間,但實際分配卻是32字節,那么剩余的12字節則會被閑置成為內存碎片。如下圖:
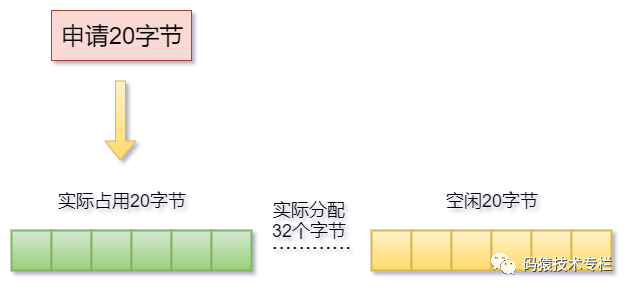
上圖中剩余12個字節空間則是閑置的,很有可能成為內存碎片,因此鍵值對大小不同則會造成一定的內存碎片,這是第一個原因。
第二個原因其實理解起來很簡單,鍵值對的修改或者刪除肯定會造成空間的擴容或者釋放;
一方面,如果修改后的鍵值對變大或者變小了,勢必會將占用的空間擴大或者釋放不用的空間,如下圖:
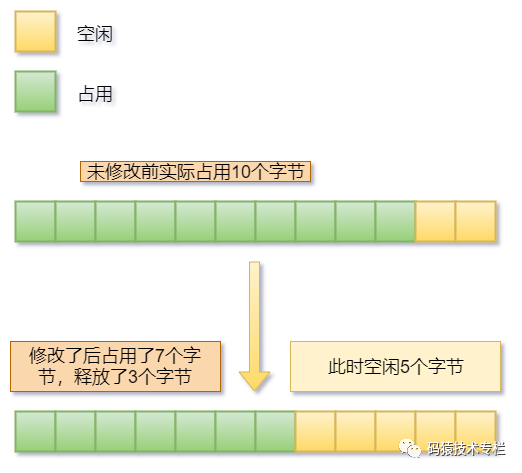
上圖中鍵值對修改后變小了,從原來的10個字節變成了7個字節,從而釋放了3個字節,此時剩余了5個字節的空閑空間。
另一方面,如果鍵值對刪除了,則會釋放掉占用的空間,形成空閑空間。
如何判斷存在內存碎片?
這個對于運維人員來說很重要,一旦出現Redis運行緩慢或者阻塞了,一定需要先判斷內存的占用情況,而不是說胡亂的重啟Redis。
Redis自身提供了INFO命令,可以用來查詢內存的使用情況,命令如下:
INFO?memory
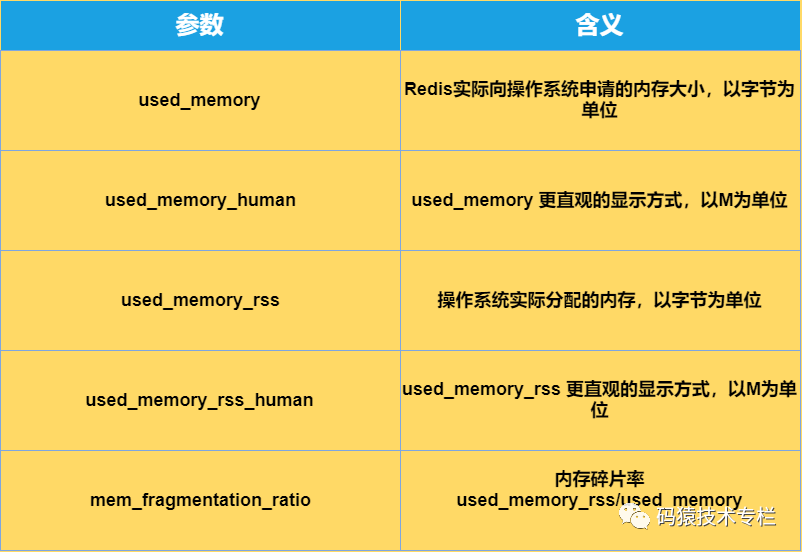
#?Memory
used_memory:1073741736
used_memory_human:1024.00M
used_memory_rss:1997159792
used_memory_rss_human:1.86G
…
mem_fragmentation_ratio:1.86
上面的各種屬性含義如下:
mem_fragmentation_ratio這個指標很清楚的展示了當前內存的碎片率,比如Redis申請了1000字節,但是操作系統實際分配的內存1800個字節,則mem_fragmentation_ratio=1800/1000=1.8
從上文也知道了,由于內存分配器的局限性,實際分配的內存絕大部分都是大于實際申請的內存,則如何通過mem_fragmentation_ratio這個值來衡量呢?這個值的范圍在多少是正常的呢?
作者這里參照了許多開發人員的建議,列出了以下經驗閥值:
>1&&<1.5:在這個范圍內是合理的,畢竟大部分情況下操作系統分配的內存總是總是大于實際申請的空間。>1.5:這表明內存碎片率已經超過50%,此時需要采取一些措施來降低碎片率了。<1:what?表明實際分配的內存小于申請的內存了,很顯然內存不足了,這樣會導致部分數據寫入到Swap中,之后Redis訪問Swap中的數據時,延遲會變大,性能會降低。
如何清理內存碎片?
既然存在內存碎片,那么的一定有方法清除內存碎片,最簡單的方法則是重啟Redis
但是這也存在一些風險,如下;
- 如果Redis未持久化,則數據會丟失(忽略從后端恢復)
- 即使持久化了,但是恢復數據時長不定,這個要根據AOF和RDB文件大小決定,在恢復階段則無法提供服務。
好在Redis 4.0-RC3版本之后,Redis自身提供了一種清除內存碎片的方法
清除的原理很簡單,通過復制拷貝將不連續的存放的數據搬到一起形成一塊連續的內存空間,如下圖:
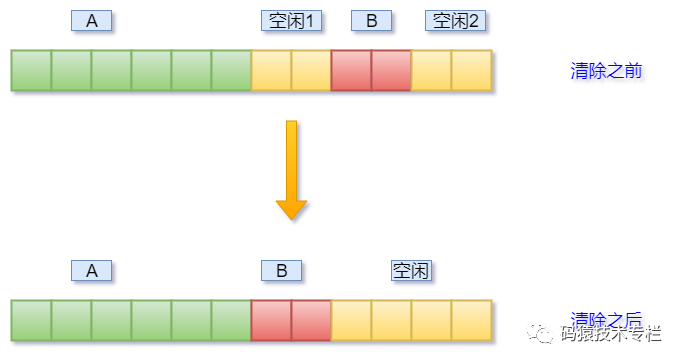
如上圖,清除之前A和B不是連續的,中間隔著兩個字節空閑1,但是在執行清除內存碎片操作之后,Redis拷貝了B到空閑1,釋放掉之前B的空間,此時空閑1和空閑2則變成了連續的空閑空間了。
那么問題來了,這種方式固然好,但是對于單線程的Redis來說,通過這種拷貝復制的方式顯然是一種耗時的操作,性能大大降低,那么有什么好的方法呢?
Redis提供了參數配置,可以控制清除內存碎片的時機,命令如下:
config?set?activedefrag?yes
以上命令啟動自動清理,但是具體什么時候清理,還要受以下兩個參數的影響:
active-defrag-ignore-bytes 400mb:如果內存碎片達到了400mb,開始清理(自定義)active-defrag-threshold-lower 20:內存碎片空間占操作系統分配給 Redis 的總空間比例達到20%時,開始清理(自定義)
以上兩個參數只有全部滿足才會開始清理
除了以上觸發清理內存碎片的參數,Redis還提供了兩個參數來保證在清理過程中不影響處理正常的請求,如下:
active-defrag-cycle-min 25:表示自動清理過程所用CPU時間的比例不低于25%,保證清理能正常開展active-defrag-cycle-max 75:表示自動清理過程所用CPU時間的比例不高于75%,一旦超過,就停止清理,從而避免在清理時,大量的內存拷貝阻塞 Redis,導致響應延遲升高。
以上兩個參數控制了清理過程中的CPU時間占比,保證了正常處理請求不受影響
總結
本文以師弟的一個疑問開頭介紹了刪除數據導致內存占用還是很高的原因是存在內存碎片,導致內存碎片大致分為兩個原因,如下:
- 內存分配策略局限性,一般都會分配固定的空間大小,導致實際分配的內存空間大于實際申請的,從而多出了許多不連續的空閑內存塊。
- 鍵值對的修改、刪除導致了內存的擴容或者釋放,導致多余的不連續的空閑內存塊。
介紹了如何通過INFO memory命令查看內存的碎片率,通過mem_fragmentation_ratio的經驗閥值來判斷異常。
介紹了Redis清理內存碎片的方式以、自動清理的兩個觸發條件、保證正常處理請求的兩個控制CPU時間的參數。
另外,作者已經完成了兩個專欄的文章Mybatis進階、Spring Boot 進階 ,已經將專欄文章整理成書,有需要的公眾號回復關鍵詞Mybatis 進階、Spring Boot 進階免費獲取。


往期推薦
給你一個億的keys,Redis如何統計?
《Spring Boot 進階》肝了五萬多字的專欄文章,整理成冊,免費獲取!!!
程序員需知的 58 個網站
宕機了,Redis數據丟了怎么辦?
單線程的Redis有哪些 "慢" 動作?
頭禿系列,二十三張圖帶你從源碼分析Spring Boot 啟動流程~








![考慮題4所示的日志記錄_[南開大學]18秋學期(1703)《數據庫基礎與應用》在線作業...](http://pic.xiahunao.cn/考慮題4所示的日志記錄_[南開大學]18秋學期(1703)《數據庫基礎與應用》在線作業...)

.ppt)








