pandas中的concat的功能:
假設你現在需要將多個數據合并,前提是:這幾個文件列名都一致,也就是說這幾個文件格式完全一樣,只是數據不太一樣,類似于合并多個文件這種,實際數據分析中也會遇到這種情況,那該怎么做呢?(可能也會遇到格式不一樣的情況,當然也是可以合并的正文也會講解)下面來一起學習下在pandas中如何快速合并文件:
主要分為兩種情況
縱向合并:
需要注意的是,axis=0也就是默認值的時候,合并的時候是按照兩個數據的列名稱作為鍵來和合并的。
s1 = pd.Series(['a', 'b'])s2 = pd.Series(['c', 'd'])pd.concat([s1, s2])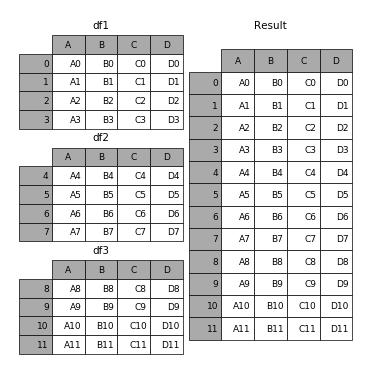
橫向合并:(axis=1,)
類似于merge,但是和merge也不一樣,如果設置axis=1合并的時候是按照索引來合并的,merge可以設置左右兩個數據的合并鍵,這點要區分。
result = pd.concat([df1, df4], axis=1)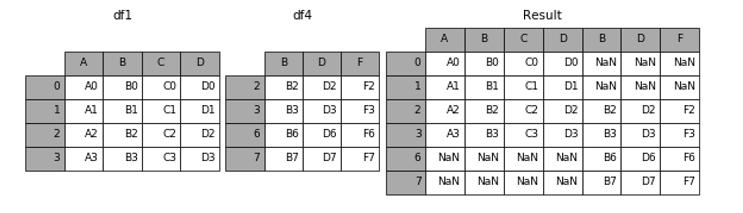
需要重點掌握的概念:
- concat和merge不一樣,雖然都是合并,但是merge更多的是數據匹配,根據共同的鍵來匹配,和sql中的查詢很類似,和excel中的vlookup很像,而concat是數據合并,不需要設置合并的鍵,
- 合并的keys:axis=0是按照列名,axis=1是按照索引來合并
- concat的概念不僅存在于數據合并,在數據分組groupby中也隱藏著它的蹤跡,先分組,每個分組統計,然后合并,其意義與我們合并數據是一樣的
- 當axis=1的時候也就是橫向合并,它的意義和merge很類似,需要好好區分
通過上面兩個簡單的例子,應該能初步認識concat
下面通過實例完整的掌握這個知識點:
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)
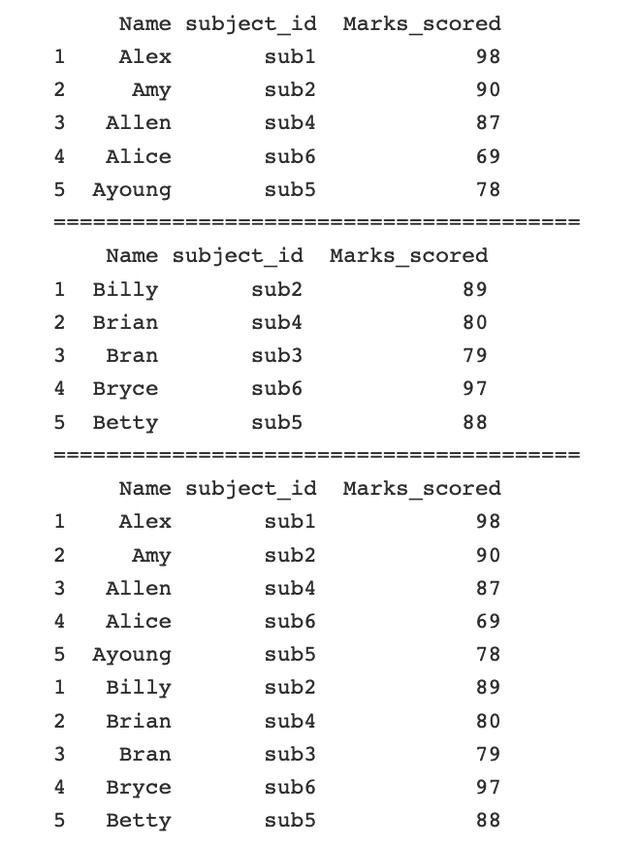
最簡單的縱向合并(有人也叫軸向合并,但是我總分不清楚,就叫它縱向合并吧)
import pandas as pdone = pd.DataFrame({ 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'subject_id':['sub1','sub2','sub4','sub6','sub5'], 'Marks_scored':[98,90,87,69,78]}, index=[1,2,3,4,5])two = pd.DataFrame({ 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'subject_id':['sub2','sub4','sub3','sub6','sub5'], 'Marks_scored':[89,80,79,97,88]}, index=[1,2,3,4,5])rs = pd.concat([one,two])print(rs)結果:
objs︰ 傳入一個需要合并的序列
axis: {0,1,...},默認值為 0。要連接沿軸。
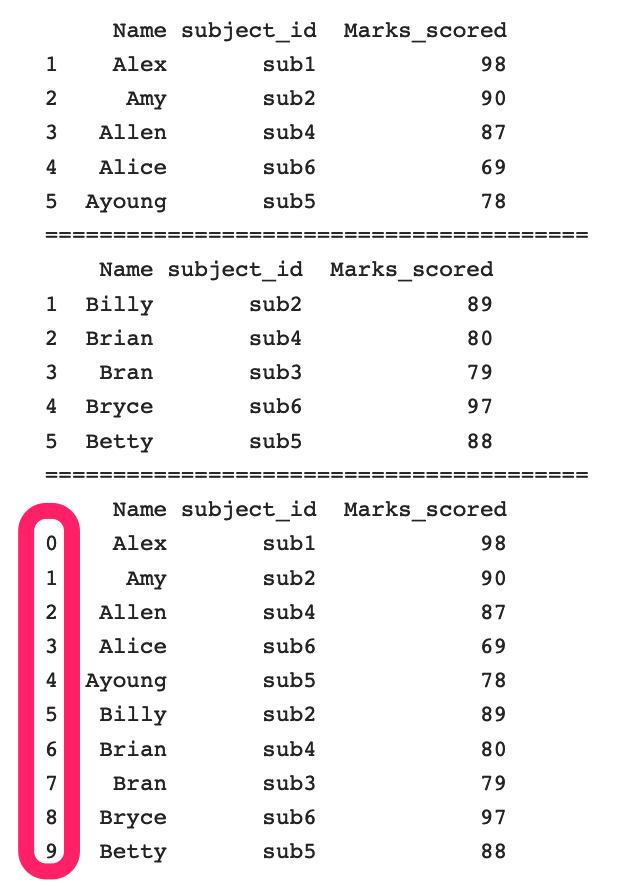
ignore_index︰ 布爾值、 默認 False。這個參數很重要,縱向合并多個文件時,默認為原來的索引,這樣勢必導致會有重復的索引值,如果想要一個全新的索引,就設置這個參數為True
在沒有設置這個參數的時候可以看到結果中的索引均為各自原先的索引,下面看看設置后的:
rs = pd.concat([one,two],ignore_index=True)結果:
keys︰ 序列,默認為無。構建分層索引使用通過的鍵作為最外面的級別。如果多個級別獲得通過,應包含元組。
如果你寫成下面這種方式,keys的結果會被ignore覆蓋掉
rs = pd.concat([one,two],ignore_index=True,keys=["a
線程安全問題產生的原因)



:fcntl 函數與文件鎖)



![[MVC學習筆記]1.項目結構搭建及單個類在各個層次中的實現](http://pic.xiahunao.cn/[MVC學習筆記]1.項目結構搭建及單個類在各個層次中的實現)
方法以及JavaScript中的示例)




)



