這個問題在最近面試的時候被問了幾次,讓談一下Logistic回歸(以下簡稱LR)和SVM的異同。由于之前沒有對比分析過,而且不知道從哪個角度去分析,一時語塞,只能不知為不知。
現在對這二者做一個對比分析,理清一下思路。
相同點
1、LR和SVM都是分類算法(曾經我認為這個點簡直就是廢話,了解機器學習的人都知道。然而,雖然是廢話,也要說出來,畢竟確實是一個相同點。)
2、如果不考慮使用核函數,LR和SVM都是線性分類模型,也就是說它們的分類決策面是線性的。
其實LR也能使用核函數,但我們通常不會在LR中使用核函數,只會在SVM中使用。原因下面會提及。
3、LR和SVM都是監督學習方法。
監督學習方法、半監督學習方法和無監督學習方法的概念這里不再贅述。
4、LR和SVM都是判別模型。
判別模型和生成模型的概念這里也不再贅述。典型的判別模型包括K近鄰法、感知機、決策樹、Logistic回歸、最大熵、SVM、boosting、條件隨機場等。典型的生成模型包括樸素貝葉斯法、隱馬爾可夫模型、高斯混合模型。
5、LR和SVM在學術界和工業界都廣為人知并且應用廣泛。(感覺這個點也比較像廢話)
不同點
1、loss function不一樣
LR的loss function是

SVM的loss function是
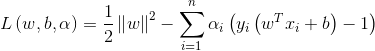
?
LR基于概率理論,通過極大似然估計方法估計出參數的值,然后計算分類概率,取概率較大的作為分類結果。SVM基于幾何間隔最大化,把最大幾何間隔面作為最優分類面。
2、SVM只考慮分類面附近的局部的點,即支持向量,LR則考慮所有的點,與分類面距離較遠的點對結果也起作用,雖然作用較小。
? SVM中的分類面是由支持向量控制的,非支持向量對結果不會產生任何影響。LR中的分類面則是由全部樣本共同決定。線性SVM不直接依賴于數據分布,分類平面不受一類點影響;LR則受所有數據點的影響,如果數據不同類別strongly unbalance,一般需要先對數據做balancing。
3、在解決非線性分類問題時,SVM采用核函數,而LR通常不采用核函數。
分類模型的結果就是計算決策面,模型訓練的過程就是決策面的計算過程。在計算決策面時,SVM算法中只有支持向量參與了核計算,即kernel machine的解的系數是稀疏的。在LR算法里,如果采用核函數,則每一個樣本點都會參與核計算,這會帶來很高的計算復雜度,所以,在具體應用中,LR很少采用核函數。
4、SVM不具有伸縮不變性,LR則具有伸縮不變性。
SVM模型在各個維度進行不均勻伸縮后,最優解與原來不等價,對于這樣的模型,除非本來各維數據的分布范圍就比較接近,否則必須進行標準化,以免模型參數被分布范圍較大或較小的數據影響。LR模型在各個維度進行不均勻伸縮后,最優解與原來等價,對于這樣的模型,是否標準化理論上不會改變最優解。但是,由于實際求解往往使用迭代算法,如果目標函數的形狀太“扁”,迭代算法可能收斂得很慢甚至不收斂。所以對于具有伸縮不變性的模型,最好也進行數據標準化。
5、SVM損失函數自帶正則項,因此,SVM是結構風險最小化算法。而LR需要額外在損失函數上加正則項。
所謂結構風險最小化,意思就是在訓練誤差和模型復雜度之間尋求平衡,防止過擬合,從而達到真實誤差的最小化。未達到結構風險最小化的目的,最常用的方法就是添加正則項。
?
參考博客
http://www.cnblogs.com/bentuwuying/p/6616761.html
![[轉載] python學習筆記2--操作符,數據類型和內置功能](http://pic.xiahunao.cn/[轉載] python學習筆記2--操作符,數據類型和內置功能)



![[轉載] python之路《第二篇》Python基本數據類型](http://pic.xiahunao.cn/[轉載] python之路《第二篇》Python基本數據類型)



![[轉載] python學習筆記](http://pic.xiahunao.cn/[轉載] python學習筆記)

)
![[轉載] Python學習:Python成員運算符和身份運算符](http://pic.xiahunao.cn/[轉載] Python學習:Python成員運算符和身份運算符)
)
![[轉載] Python 機器學習經典實例](http://pic.xiahunao.cn/[轉載] Python 機器學習經典實例)
![哈希表的最差復雜度是n2_給定數組A []和數字X,請檢查A []中是否有對X | 使用哈希O(n)時間復雜度| 套裝1...](http://pic.xiahunao.cn/哈希表的最差復雜度是n2_給定數組A []和數字X,請檢查A []中是否有對X | 使用哈希O(n)時間復雜度| 套裝1...)
)
![[轉載] Python-Strings](http://pic.xiahunao.cn/[轉載] Python-Strings)


![[轉載] python中的for循環對象和循環退出](http://pic.xiahunao.cn/[轉載] python中的for循環對象和循環退出)