本文講的是Kubernetes基礎組件概述【編者的話】最近總有同學問Kubernetes中的各個組件的相關問題,其實這些概念內容在官方文檔中都有,奈何我們有些同學可能英文不好,又或者懶得去看,又或者沒有找到,今天有時間就專門寫了這篇博客。
【深圳站|3天燒腦式Kubernetes訓練營】培訓內容包括:Kubernetes概述、架構、日志和監控,部署、自動駕駛、服務發現、網絡方案等核心機制分析,進階篇——Kubernetes調度工作原理、資源管理及源碼分析等。
本文主要介紹Kubernetes的基礎組件,先介紹Master節點上的控制管理組件,再介紹Node節點上的計算組件,最后是附加組件,后邊會找時間再寫一篇介紹Kubernetes中的各種資源及使用。
kube-proxy本身實際上并不負責請求轉發和負載均衡,而時從kube-apiserver獲取Service和POD的狀態更新,生成對應的DNAT規則到本地的iptabels,最終的轉發和負載均衡動作有iptabels實施,所以kube-proxy組件即使出現問題,已經更新到iptabels的轉發規則依然能夠生效。
有了上邊介紹的Master節點組件和Node節點組件后,基礎的Kubernetes環境算是已經構建好了:
原生的docker網絡結構:docker在啟動的時候會創建一個網橋docker0(172.17.0.0),容器啟動的時候會創建一對Veth pair,這個Veth pair成對出現用于鏈接容器與docker0網橋(可以將其理解成一根網線的兩個插頭,一頭插在容器內改名為eth0,另一頭插在宿主機的docker0網橋上),這樣同一臺宿主機上的容器就可以互相訪問了,此時的路由表記錄:
但是對于不同的宿主機A和宿主機B來說,它們的docker網絡一模一樣,IP也是一樣,網絡與網絡之間也不通。
Flannel來了之后,在每個宿主機上增加了個P2P的虛擬網卡flannel0(172.17.0.0),一頭對接docker0網橋,一頭由Flanneld服務監聽。Etcd管理著整個Flannel網絡的子網分配,宿主機A和宿主機B分別用分到的子網
模擬下Flannel網絡下宿主機A上的docker容器(172.17.1.10)發送數據到宿主機B上的docker容器(172.17.2.15)的過程:
Flannel的Github上有張比較詳細的原理圖:
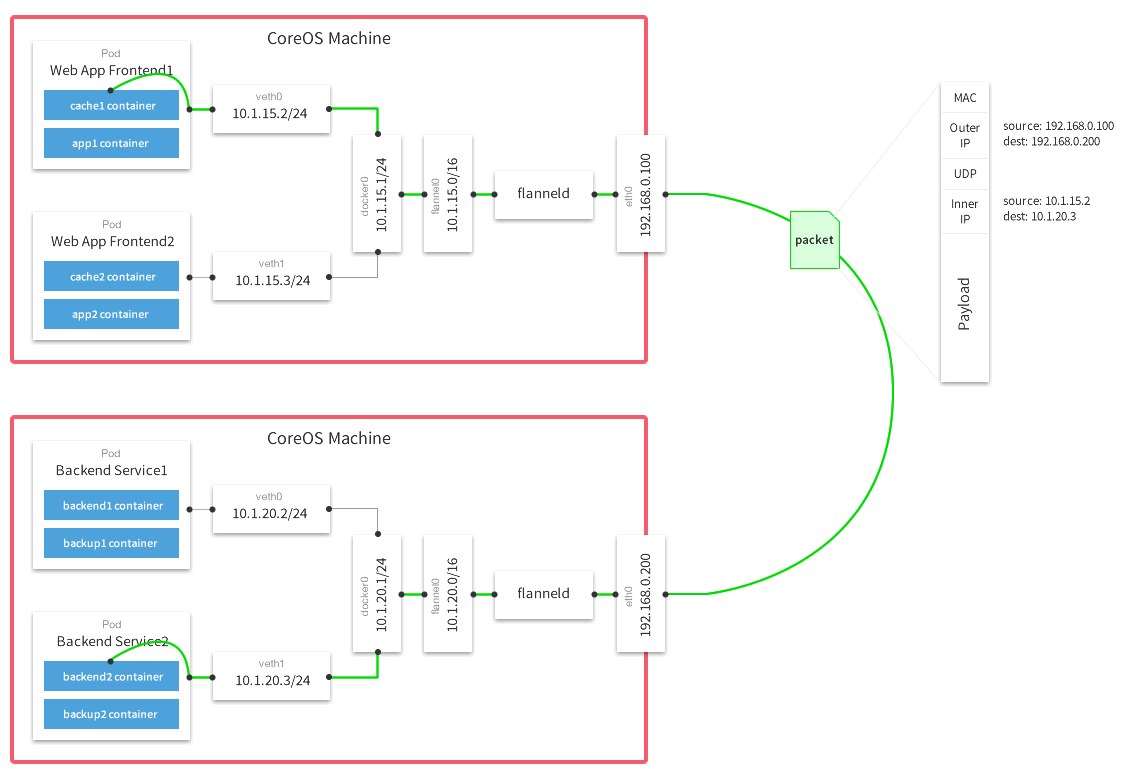
圖中的Flanneld運行在每個宿主機上,負責數據的發送、監聽、封包、解包等任務。
強調下,Flannel的backend有UDP和VXLAN、GRE等實現,默認使用UDP,性能大約只有本地物理網絡的一半,VXLAN推薦使用,性能損耗很小,不過需要3.9+的內核支持。
Clico網絡模型的特點:
Calico 的核心組件:
Felix:Calico agent,跑在每臺需要運行workload的節點上,主要負責配置路由及 ACLs等信息來確保endpoint的連通狀態;
etcd:分布式鍵值存儲,主要負責網絡元數據一致性,確保Calico網絡狀態的準確性;
BGP Client(BIRD):主要負責把Felix寫入kernel的路由信息分發到當前Calico網絡,確保workload間的通信的有效性;
BGP Route Reflector(BIRD):大規模部署時使用,摒棄所有節點互聯的mesh模式,通過一個或者多個BGP Route Reflector來完成集中式的路由分發;
默認的kube-dns的service_ip:10.96.0.10,默認的域名后綴為:cluster.local,如果是kubeadm部署的Kubernetes集群,kubelet的配置參數文件是:
DNS解析的A記錄規則為:
POD實例創建后,其中的Container內的resolver.conf的配置如下:
因為添加了search domain,在POD的容器內訪問其他Service時可以用縮略域名訪問,如訪問kube-dns服務:kube-dns(同namespace內訪問),kube-dns.kube-system(跨namespace訪問)。
可以通過官方提供的YAML模板創建:
【深圳站|3天燒腦式Kubernetes訓練營】培訓內容包括:Kubernetes概述、架構、日志和監控,部署、自動駕駛、服務發現、網絡方案等核心機制分析,進階篇——Kubernetes調度工作原理、資源管理及源碼分析等。
本文主要介紹Kubernetes的基礎組件,先介紹Master節點上的控制管理組件,再介紹Node節點上的計算組件,最后是附加組件,后邊會找時間再寫一篇介紹Kubernetes中的各種資源及使用。
1 Master節點組件
Master節點組件是指運行在Kubernetes集群中的Master節點上,提供整個集群的管理控制功能的組件,例如調度組件(kube-scheduler),接口組件(kube-apiserver)等1.1 kube-apiserver
kube-apiserver主要負責暴露Kubernetes API,不管是kubectl還是HTTP調用來操作Kubernetes集群各種資源,都是通過kube-apiserver提供的接口進行操作的。詳細介紹、文檔、配置參數:API-Server配置。
1.2 kube-controller-manager
管理控制器負責整個Kubernetes的管理工作,保證集群中各種資源的狀態處于期望狀態,當監控到集群中某個資源狀態不正常時,管理控制器會觸發對應的調度操作,主要由以下幾部分組成:- 節點控制器(Node Controller)
- 副本控制器(Replication Controller)
- 端點控制器(Endpoints Controller)
- 命名空間控制器(Namespace Controller)
- 身份認證控制器(Serviceaccounts Controller)
詳細介紹、文檔、配置參數:Controller-Manager配置。
1.3 cloud-controller-manager
云管理控制器是Kubernetes 1.6新加入的組件(組件抽象了一層IaaS平臺的接口,具體的實現由各云廠商負責提供),主要負責與基礎計算云平臺(IaaS)的交互,目前還處于測試開發階段,我們也還沒有使用過該組件。該組件的具體實現包括:- 節點控制器(Node Controller)
- 路由控制器(Route Controller)
- 負載均衡服務控制器(Service Controller)
- 數據卷控制器(Volume Controller)
1.4 kube-scheduler
調度器負責Kubernetes集群的具體調度工作,接收來自于管理控制器(kube-controller-manager)觸發的調度操作請求,然后根據請求規格、調度約束、整體資源情況等因素進行調度計算,最后將任務發送到目標節點的kubelet組件執行。詳細介紹、文檔、配置參數:Scheduler配置。
1.5 etcd
etcd是一款用于共享配置和服務發現的高效KV存儲系統,具有分布式、強一致性等特點。在Kubernetes環境中主要用于存儲所有需要持久化的數據。2 Node節點組件
Node節點組件是指運行在Node節點上,負責具體POD運行時環境的組件。2.1 kubelet
kubelet是Node節點上最重要的核心組件,負責Kubernetes集群具體的計算任務,具體功能包括:- 監聽Scheduler組件的任務分配
- 掛載POD所需Volume
- 下載POD所需Secrets
- 通過與docker daemon的交互運行docker容器
- 定期執行容器健康檢查
- 監控、報告POD狀態到kube-controller-manager組件
- 監控、報告Node狀態到kube-controller-manager組件
2.2 kube-proxy
kube-proxy主要負責Service Endpoint到POD實例的請求轉發及負載均衡的規則管理。kube-proxy本身實際上并不負責請求轉發和負載均衡,而時從kube-apiserver獲取Service和POD的狀態更新,生成對應的DNAT規則到本地的iptabels,最終的轉發和負載均衡動作有iptabels實施,所以kube-proxy組件即使出現問題,已經更新到iptabels的轉發規則依然能夠生效。
詳細介紹、文檔、配置參數:Kube-Proxy配置。
3 附加組件
BTW:所謂的附加組件并不是說這類組件在kunernetes環境中可有可無,只是為了區別于底層的基礎計算組件。有了上邊介紹的Master節點組件和Node節點組件后,基礎的Kubernetes環境算是已經構建好了:
kubectl調用apiserver發送創建pod的請求,scheduler收到調度任務發送到符合要求的node節點,node節點上的kubelet與docker daemon通訊創建docker容器。但是離真正可用的Kubernetes集群還有一定距離,例如Container IP管理,內部DNS解析,簡單的管理控制臺等。
3.1 Flannel
Flannel是由ConreOS主導設計的用于容器技術的覆蓋網絡(Overlay Network),在Flannel管理的容器網絡中,每一個宿主機都會擁有一個獨立子網,用于分配給其上的容器使用。通信方式是基于隧道協議的UDP和VXLAN等方式封包、解包及傳輸。原生的docker網絡結構:docker在啟動的時候會創建一個網橋docker0(172.17.0.0),容器啟動的時候會創建一對Veth pair,這個Veth pair成對出現用于鏈接容器與docker0網橋(可以將其理解成一根網線的兩個插頭,一頭插在容器內改名為eth0,另一頭插在宿主機的docker0網橋上),這樣同一臺宿主機上的容器就可以互相訪問了,此時的路由表記錄:
172.17.0.0?????0.0.0.0?????????255.255.0.0???????U?????0??????0????????0?docker0
但是對于不同的宿主機A和宿主機B來說,它們的docker網絡一模一樣,IP也是一樣,網絡與網絡之間也不通。
Flannel來了之后,在每個宿主機上增加了個P2P的虛擬網卡flannel0(172.17.0.0),一頭對接docker0網橋,一頭由Flanneld服務監聽。Etcd管理著整個Flannel網絡的子網分配,宿主機A和宿主機B分別用分到的子網
172.17.1.0和172.17.2.0創建docker0網橋,然后又悄悄地修改了一下docker daemon的啟動參數--bip=172.17.1.1/24,同時添加路由表記錄:#宿主機A 172.17.0.0?????0.0.0.0?????????255.255.0.0???????U?????0??????0????????0?flannel0 172.17.1.0?????0.0.0.0?????????255.255.255.0?????U?????0??????0????????0?docker0
宿主機B
172.17.0.0?????0.0.0.0?????????255.255.0.0???????U?????0??????0????????0?flannel0 172.17.2.0?????0.0.0.0?????????255.255.255.0?????U?????0??????0????????0?docker0模擬下Flannel網絡下宿主機A上的docker容器(172.17.1.10)發送數據到宿主機B上的docker容器(172.17.2.15)的過程:
- 根據源容器和目的容器的IP匹配路由規則,同時匹配兩個IP的路由規則是
172.17.0.0/16,如果是同一個宿主機上的容器訪問,匹配的是172.17.1.0或者172.17.2.0 - 數據從docker0網橋出來以后投遞到flannel0網卡
- 監聽flannel0網卡的Flanneld服務收到數據后封裝成數據包發送到宿主機B
- 宿主機B上的Flanneld服務接收到數據包后解包還原成原始數據
- Flanneld服務發送數據到flannel0網卡,根據目的容器地址匹配到路由規則
172.17.2.0/24(docker0) - 投遞數據到docker0網橋,進而進入到目標容器172.17.2.15。
Flannel的Github上有張比較詳細的原理圖:
圖中的Flanneld運行在每個宿主機上,負責數據的發送、監聽、封包、解包等任務。
強調下,Flannel的backend有UDP和VXLAN、GRE等實現,默認使用UDP,性能大約只有本地物理網絡的一半,VXLAN推薦使用,性能損耗很小,不過需要3.9+的內核支持。
詳細介紹、文檔、源碼:Flannel Github。
3.2 Calico
Calico是純三層的SDN實現,它基于BPG協議和Linux的路由轉發機制,不依賴特殊硬件,沒有使用NAT或Tunnel等技術。能夠方便的部署在物理服務器,虛擬機(如OpenStack)或者容器環境下,可以無縫集成像OpenStack這種IaaS云架構,能夠提供可控的VM、容器、裸機之間的IP通信,同時它自帶的基于Iptables的ACL管理組件非常靈活,能夠滿足比較復雜的安全隔離需求。Clico網絡模型的特點:
- 在Calico中的數據包并不需要進行封包和解封。
- Calico中的數據包,只要被policy允許,就可以在不同租戶中的workloads間傳遞或直接接入互聯網或從互聯網中進到Calico網絡中,并不需要像overlay方案中,數據包必須經過一些特定的節點去修改某些屬性。
- 因為是直接基于三層網絡進行數據傳輸,TroubleShooting會更加容易,同時用戶也可以直接用一般的工具進行操作與管理,比如ping、Whireshark等,無需考慮解包之類的事情。
- 網絡安全策略使用ACL定義,基于iptables實現,比起overlay方案中的復雜機制更直觀和容易操作。
Calico 的核心組件:
Felix:Calico agent,跑在每臺需要運行workload的節點上,主要負責配置路由及 ACLs等信息來確保endpoint的連通狀態;
etcd:分布式鍵值存儲,主要負責網絡元數據一致性,確保Calico網絡狀態的準確性;
BGP Client(BIRD):主要負責把Felix寫入kernel的路由信息分發到當前Calico網絡,確保workload間的通信的有效性;
BGP Route Reflector(BIRD):大規模部署時使用,摒棄所有節點互聯的mesh模式,通過一個或者多個BGP Route Reflector來完成集中式的路由分發;
詳細介紹、文檔、源碼:Calico Github。
3.3 DNS
kube-dns負責Kubernetes集群內的域名解析,解析服務通過dnsmasq實現。通過官方提供的Deployment和Service模板,可以很方便地部署kube-dns服務,并且可以任意伸縮POD實例來保證其高可用性。默認的kube-dns的service_ip:10.96.0.10,默認的域名后綴為:cluster.local,如果是kubeadm部署的Kubernetes集群,kubelet的配置參數文件是:
/etc/systemd/system/kubelet.service.d/10-kubeadm.conf。DNS解析的A記錄規則為:
my-svc.my-namespace.svc.cluster.local,例如kube-dns的service的A記錄為:kube-dns.kube-system.svc.cluster.local。POD實例創建后,其中的Container內的resolver.conf的配置如下:
search?kube-system.svc.cluster.local?svc.cluster.local?cluster.local nameserver?10.96.0.10 options?timeout:1?rotate options?ndots:5
因為添加了search domain,在POD的容器內訪問其他Service時可以用縮略域名訪問,如訪問kube-dns服務:kube-dns(同namespace內訪問),kube-dns.kube-system(跨namespace訪問)。
詳細介紹、文檔:Kube-Dns文檔。
3.4 Dashboard
Dashboard是官方提供的kubernetes集群的UI界面,提供了一些基礎的查看及簡單操作,隨便用用還行。可以通過官方提供的YAML模板創建:
kubectl create -f https://rawgit.com/kubernetes/dashboard/master/src/deploy/kubernetes-dashboard.yaml。詳細介紹、文檔:Kube-Dashboard文檔。
原文發布時間為:2017-04-26
本文作者:史紹虎
本文來自云棲社區合作伙伴Dockerone.io,了解相關信息可以關注Dockerone.io。
原文標題:Kubernetes基礎組件概述

![[轉載] C Primer Plus 第6章 C控制語句 6.16 編程練習及答案](http://pic.xiahunao.cn/[轉載] C Primer Plus 第6章 C控制語句 6.16 編程練習及答案)


![[轉載] python——if語句、邏輯運算符號](http://pic.xiahunao.cn/[轉載] python——if語句、邏輯運算符號)


![[轉載] python中for語句用法_詳解Python中for循環的使用_python](http://pic.xiahunao.cn/[轉載] python中for語句用法_詳解Python中for循環的使用_python)


![[轉載] 使用Python編寫打字訓練小程序](http://pic.xiahunao.cn/[轉載] 使用Python編寫打字訓練小程序)


![[轉載] Python進階:設計模式之迭代器模式](http://pic.xiahunao.cn/[轉載] Python進階:設計模式之迭代器模式)


![[轉載] 大數據分析Python For循環教程](http://pic.xiahunao.cn/[轉載] 大數據分析Python For循環教程)


