原創網址:https://blog.csdn.net/qq_27150893/article/details/80169736
sklearn是非常流行的機器學習庫,實現了很多的機器學習模型。官網:http://scikit-learn.org/stable/? 里面有全面的實例和模型參數講解,用到哪個模型就去官方查看說明文檔。
基本功能主要被分為六大部分:分類,回歸,聚類,數據降維,模型選擇和數據預處理。
?Estimator框架的基本使用套路:
? ? ?model = EstimatorObject()? #得到模型
? ? ?model.fit(dataset.data, dataset.target)? ?#訓練模型
? ? ?model.predict(dataser.data)? ? #預測
本文對主要的機器學習模型進行實例演示,具體模型的參數結合的自己需求設置。
1.分類問題
數據集為 Car Ecaluation,根據汽車的若干屬性對汽車性能進行評價。下載地址:http://archive.ics.uci.edu/ml/datasets/Car+Evaluation
預處理:將數據集保存后將后綴直接改為csv,并將里面用字符串表示的等級轉化為數字。如small,low,unacc轉化為1,2,3
1.1 SVM支持向量機模型
from sklearn import svmimport pandas as pdimport numpy as npfrom sklearn.model_selection import train_test_split#SVM模型實現汽車性能評測car_data = pd.read_csv(r'D:\pyproject\sklearn\car.csv')car_data = car_data.dropna() #去掉缺失值#提取特征和類別X= car_data.ix[:, :'safety']y= car_data.ix[:,'class']#劃分訓練集和測試集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)# 建立模型。 設置算法內核類型,有 'linear’, ‘poly’, ‘rbf’, ‘sigmoid’;懲罰參數為1,一般為10的冪次方svc_model = svm.SVC(kernel='rbf', C= 1)svc_model.fit(X_train, y_train)predict_data = svc_model.predict(X_test)accuracy = np.mean(predict_data==y_test)print(accuracy)?
運行結果:
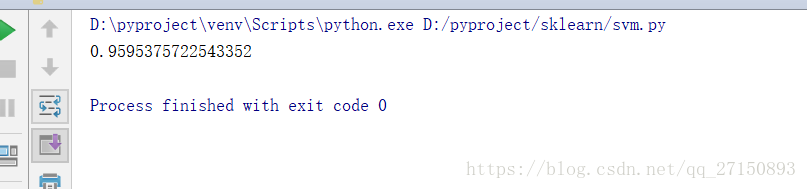
1.2 MLP神經網絡模型
from sklearn.neural_network import MLPClassifierimport pandas as pdimport numpy as npfrom sklearn.model_selection import train_test_split#MLP神經網絡模型實現汽車性能評測car_data = pd.read_csv(r'D:\pyproject\sklearn\car.csv')car_data = car_data.dropna() #去掉缺失值#提取特征和對象類別X= car_data.ix[:, :'safety']y= car_data.ix[:,'class']#劃分訓練集和測試集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)#建立MLP神經網絡模型 ,MLP的求解方法為adam,可選lbfgs、sgd,正則化懲罰alpha = 0.1mpl_model = MLPClassifier(solver='adam', learning_rate='constant', learning_rate_init=0.01,max_iter = 500,alpha =0.01)mpl_model.fit(X_train, y_train)predict_data = mpl_model.predict(X_test)accuracy = np.mean(predict_data == y_test)print(accuracy)???????
運行結果:
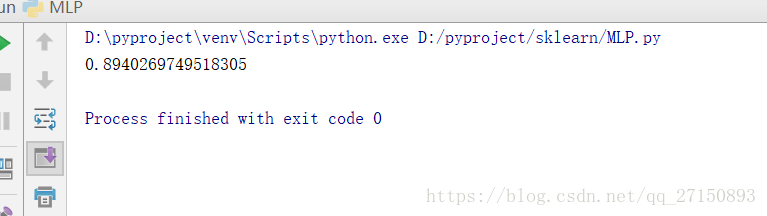
1.3 邏輯回歸模型
import pandas as pdimport numpy as npfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegression#邏輯回歸模型實現汽車性能預測car_data = pd.read_csv(r'D:\pyproject\sklearn\car.csv')car_data = car_data.dropna() #去掉缺失值#提取特征和對象類別X= car_data.ix[:, :'safety']y= car_data.ix[:, 'class']#劃分訓練集和測試集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)#建立邏輯回歸模型 ,懲罰參數為100lr_model = LogisticRegression(C= 100, max_iter=1000)lr_model.fit(X_train, y_train)predict_data = lr_model.predict(X_test)accuracy = np.mean(predict_data == y_test)print(accuracy)?
運行結果:
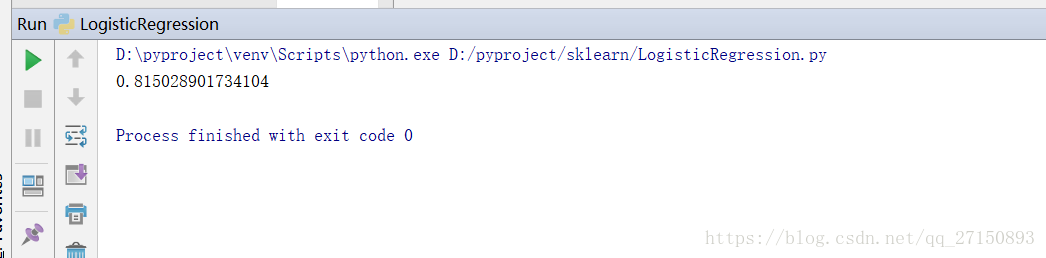
?
1.4 決策樹模型
from sklearn import treeimport pandas as pdimport numpy as npfrom sklearn.model_selection import train_test_split#決策樹模型實現汽車性能預測car_data = pd.read_csv(r'D:\pyproject\sklearn\car.csv')car_data = car_data.dropna() #去掉缺失值#提取特征和類別X= car_data.ix[:, :'safety']y= car_data.ix[:,'class']#劃分訓練集和測試集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)# 建立決策樹模型,選擇算法為熵增益,可選gini,entropy,默認為ginitree_model = tree.DecisionTreeClassifier(criterion='gini')tree_model.fit(X_train, y_train)predict_data = tree_model.predict(X_test)accuracy = np.mean(predict_data==y_test)print(accuracy)???????
運行結果:
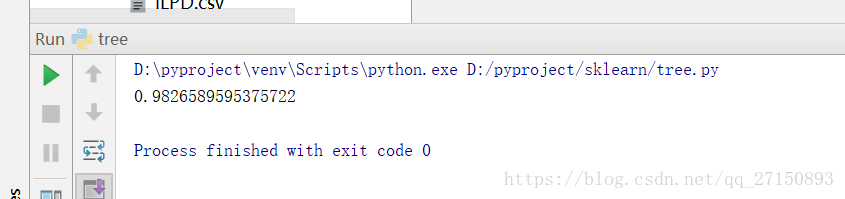
?
1.5 KNN(K最臨近模型)
-
from sklearn import neighbors -
import pandas as pd -
import numpy as np -
from sklearn.model_selection import train_test_split -
#K最鄰模型實現汽車性能預測 -
car_data = pd.read_csv(r'D:\pyproject\sklearn\car.csv') -
car_data = car_data.dropna() #去掉缺失值 -
#提取特征和類別 -
X= car_data.ix[:, :'safety'] -
y= car_data.ix[:, 'class'] -
#劃分訓練集和測試集 -
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) -
# 建立KNN模型,鄰居數選為7,默認為5 -
knn_model = neighbors.KNeighborsClassifier(n_neighbors = 7) -
knn_model.fit(X_train, y_train) -
#對測試集進行預測 -
predict_data = knn_model.predict(X_test) -
accuracy = np.mean(predict_data==y_test) -
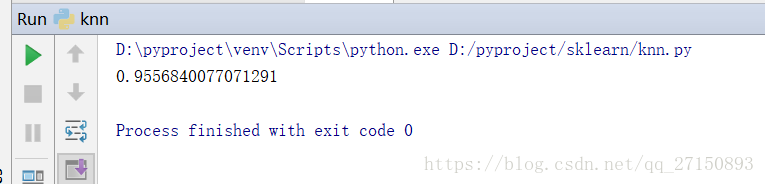
print(accuracy)
運行結果:
?
2. 回歸問題
? 這里使用sklearn自帶的數據集,數據集為波斯頓房價,根據波斯頓地區若干指標對房價進行預測。
? 2.1 線性回歸模型實現
-
from sklearn.linear_model import LinearRegression -
from sklearn.datasets import load_boston -
from sklearn.model_selection import train_test_split -
#導入結果評價包 -
from sklearn.metrics import mean_absolute_error -
#利用線性回歸模型預測波斯頓房價 - ?
-
#下載sklearn自帶的數據集 -
data = load_boston() -
#建立線性回歸模型 -
clf = LinearRegression() -
#劃分訓練集和測試集 -
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3, random_state=0) -
clf.fit(X_train, y_train) -
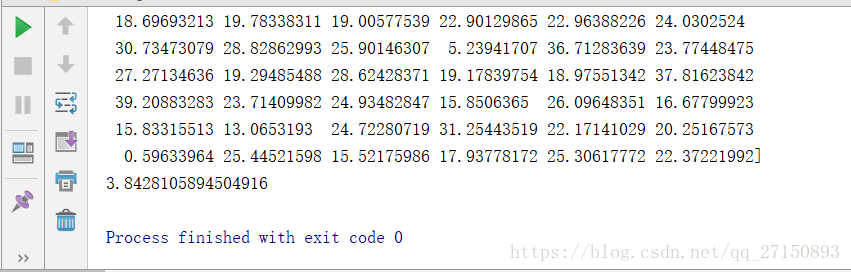
predict_data = clf.predict(X_test) -
print(predict_data) -
#平均絕對值誤差對結果進行評價 -
appraise = mean_absolute_error(y_test, predict_data) -
print(appraise)
運行結果:



)

:sess.run())



-加入DI-dagger2)

)







