背景
- 近期在做外賣分類的項目,外賣分類屬于細粒度圖像分類,在分類的過程中要從圖片的行人中和非機動車中區分出各類外賣(主要是美團、餓了嗎)。剛好近期發現了一片關于細粒度圖像分類較新的論文(See Better Before Looking Closer: Weakly Supervised Data Augmentation Network for Fine-Grained Visual Classification),于是就準備親生嘗試一下。
- 論文地址:https://arxiv.org/pdf/1901.09891.pdf?點擊閱讀
目錄
- Weakly Suprevised Learning(弱監督學習)
- Data Augmentation(數據增強)
- WS-DAN (Weakly Supervised Data Augmentation Network)(弱監督數據增強網絡)
Weakly Suprevised Learning(弱監督學習)
什么是弱監督學習
弱監督是相對監督而言,所謂的監督簡單的說就是label,所以監督的強弱就是從label來劃分的,弱監督就是data的label并不是很完善的情況,其種類如下:
- 不完整監督: 部分樣本label缺失。 即只有訓練數據集的一個(通常很小的)子集有標簽,其它數據則沒有標簽。在很多任務中都存在這種情況。例如,在圖像分類中,真值標簽是人工標注的;從互聯網上獲得大量的圖片很容易,然而由于人工標注的費用,只能標注其中一個小子集的圖像。
- 粗粒度監督: 只有粗粒度的標簽。 又以圖像分類任務為例。我們希望圖片中的每個物體都被標注;然而我們只有圖片級的標簽而沒有物體級的標簽。比如說你有一張水果的圖片,但是你不知道圖片中的水果具體是蘋果還是梨。
- 不準確監督:給的label包含噪聲,甚至是錯誤的label,比如把“行人”標注為“汽車”。 即給定的標簽并不總是真值。出現這種情況的原因有,標注者粗心或疲倦,或者一些圖像本身就難以分類。
Data Augmentation(數據增強)
數據增強是常用的增加數據訓練數據量的方法,被用來預防過擬合和提高深度學習模型的表現。在計算機視覺領域實踐應用中常用的數據增強方法主要有:剪裁、翻轉、旋轉、比例縮放、位移、高斯噪聲以及更高級的增強技術條件型生成對抗網絡(Conditional GAN)。
- 剪裁(Crop):從原始圖像中隨機抽樣一部分,然后將此部分調整為原圖像大小。這種方法通常也被稱為
隨機剪裁。 - 翻轉(Flip):可以對圖片進行水平和垂直翻轉。
- 旋轉(Rotation):對圖像按照圖像中心進行旋轉一定角度,并將大小作為原圖的大小。
- 比例縮放(Scale):圖像可以向內或者向外縮放。向內縮放后通常圖像會小于原圖,通常會對超出邊界做處內容假設;向外縮放后通常會大于原圖,通常會新圖中剪裁出一部分。(它和隨機剪裁得到對圖像具有一定區別,有興趣可以自己拿一張圖片試一下看一下效果)
- 位移(Translation):對同圖像中對目標按照x或y方向平移,因為多數情況,我們的目標對象可能出現在圖像的任何位置。
- 高斯噪聲(Gaussian Noise):當神經網絡試圖學習高頻特征(即非常頻繁出現的無意義模式),而這些高頻特征對模型提升沒有什么幫助的時候發生過擬合(Overfitting)。因此,對這些數據人為加入噪聲,使其特征失真,減弱其對模型的影響,
高斯噪聲就是這種方法之一, - 條件型生成對抗網絡(Conditional GANs):是一種強大的神經網絡,能將一張圖片從一個領域轉換到另一個領域中去,比如改變風景圖片的季節、轉換圖片風格等。
講了那么多數據增強的方法,和弱監督學習有什么關系呢?
常用的數據增強方法中有很多采用的是隨機的方法增廣,像隨機圖像剪裁,對圖像處理時是采用隨機對目標圖像進行剪裁對方法,這樣做有一定的概率是能剪裁到我們需要對目標,但是更大的概率是會剪裁到我們并不需要的目標,比如背景等噪聲目標。’(WS-DAN)Weakly Supervised Data Augmentation Network’(弱監督數據增強網絡)在訓練過程中通過弱監督學習產生一個用來表征目標顯著特征的’attention map’;然后利用’attention map’有目標性的指導數據增強(包括注意力剪裁’attention cropping’和注意力丟棄’attention dropping’等)。
WS-DAN (Weakly Supervised Data Augmentation Network)(弱監督數據增強網絡)
‘WS-DAN’通過兩種渠道增強圖像分類的表現,一種方式:因為我們從圖片中提取了顯著的特征,使圖片看起來更加有效’See Better’;另一種方式:注意力圈定了目標的位置,使得模型能夠更‘近’的觀察我們的目標從而提高模型表現’Look Closer’。
Attention Cropping和Attention Dropping能夠使模型做到See Better Before Looking Closer。See Better:Attention map表示了目標的顯著特征部分。我們可以隨機選擇其中的一個顯著特征部分將它刪除,進而產生更加顯著的特征部分;或者將閑著特征部分剪裁下來用于提取更加詳細的特征。
?
-

?
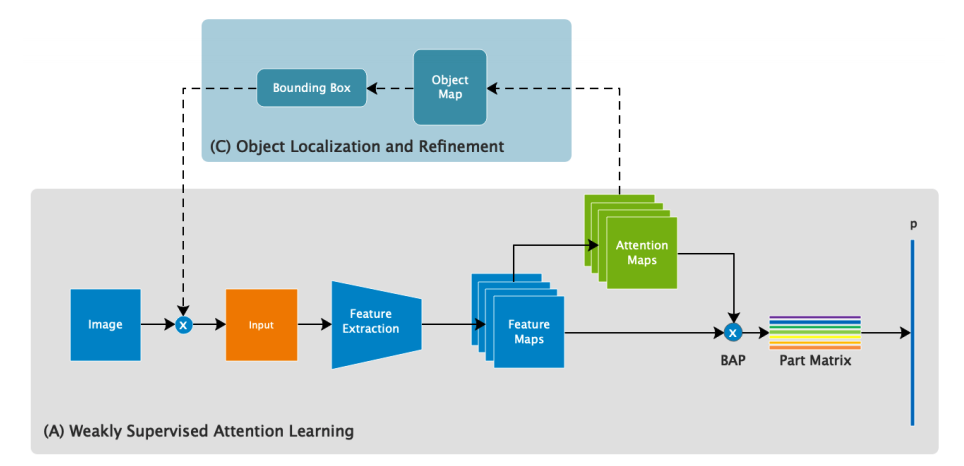
- 訓練過程:(a)弱監督注意力學習,通過弱監督注意力學習對每一張訓練圖片生成一個注意力圖(attention maps)來表征對象對顯著特征部分。(b)注意力引導數據增強,隨機選擇一張注意力圖,通過注意力剪裁和注意力刪除的方式去增強這張圖片,最后原圖和增強對數據都會被作為輸入數據進行訓練。
?
-

?
- 測試過程:首先原圖通過弱監督學習輸出目標的類別概率和注意力圖;然后通過目標定位和精煉定位目標的位置;最后將前兩個階段的數據結合。
?
-
?
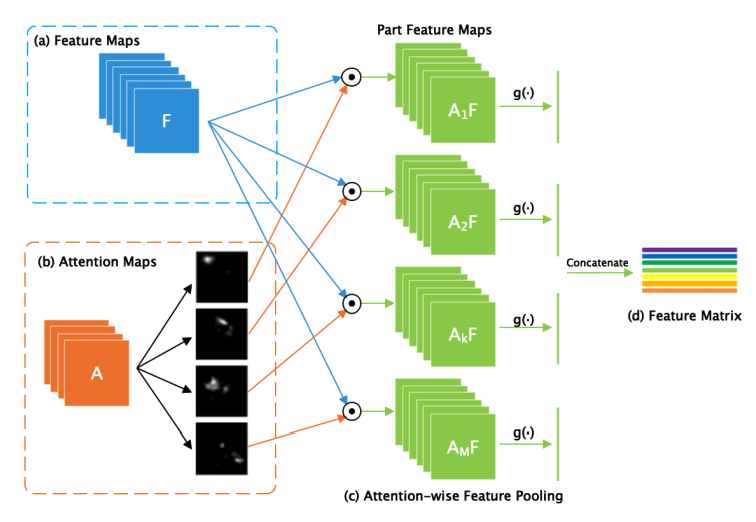
- BAP(Bilinear Attention Pooling)的過程:首先通過網絡的主干(如resnet18)部分分別得到特征圖(a)和注意力圖(b)。每一個注意力圖都代表了目標的特定部分。通過對注意力圖和特征圖的元素點乘得到各個分部特征圖,讓后利用卷積或者池化處理分部特征圖,最后將各個分部特征圖結合得到特征矩陣。
?
實踐比較
- 注意力剪裁和隨機剪裁的比較: 隨機剪裁容易剪裁到圖像的背景,而注意力剪裁知道取那些部分會see better。
?
-

?
- 注意力丟棄和隨機丟棄的比較: 隨機丟棄可能會將整個目標丟棄或者只丟棄背景部分,而注意力丟棄對剔除目標顯著部分和的注意力求具有更高的效率。
?

補充
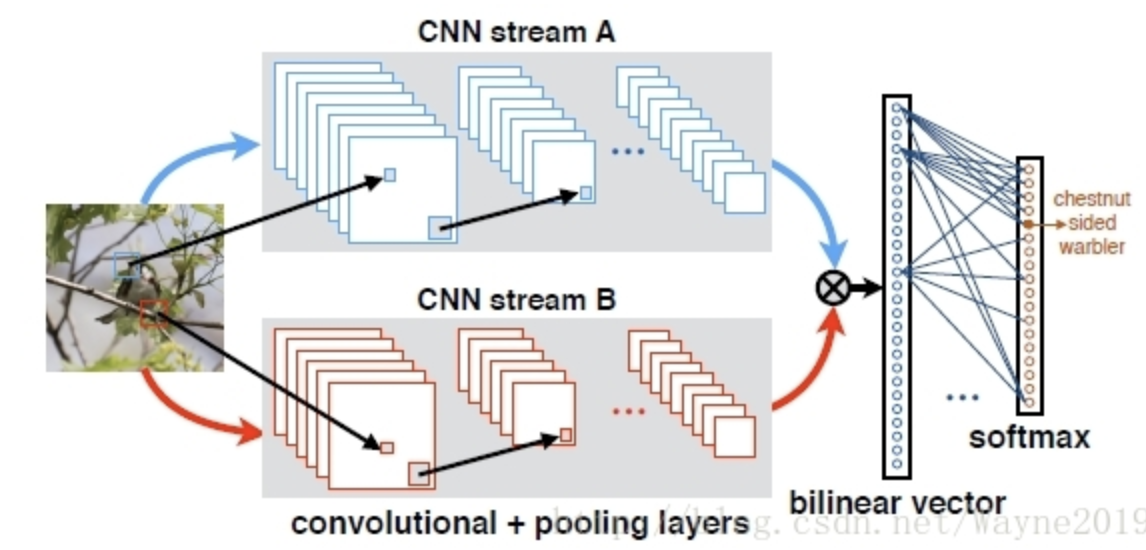
- bilinear pooling:主要是外積,主要用于組合cnn(a和b)的feature map
?
-
?
- 代碼地址:https://github.com/GuYuc/WS-DAN.PyTorch?點擊跳轉
?

)

)
)









)

:客戶端的請求在服務器中經歷了什么...)


