摘要: 一杯茶的功夫部署完成機器學習模型!

在生產環境中部署機器學習模型是數據工程中經常被忽視的領域。網上的大多數教程/博客都側重于構建、訓練和調整機器學習模型。如果它不能用于實際的預測,那么它又有什么用呢? 接下來了解一下有哪些部署選項吧:
評估選項
在生產中部署機器學習模型時,有多種選擇。其中一種流行的方法是使用Azure Machine Learning Studio等云服務設計和訓練模型,這些服務具有使用拖放工具構建和訓練模型的能力。此外,將這些模型作為Web服務發布只需點擊幾下即可。此類設置的附加優勢在于,該部署會隨著應用程序使用量的增加而自動擴展。
雖然短時間看起來很方便,但從長遠來看,這種設置可能會有問題。當我們想要將應用程序從第三方云平臺遷移并將其部署在我們的服務器上時,就有難度了。由于這些工具與其各自的云平臺緊密集成,因此這種設置不可移植。此外,隨著應用程序的擴展,云計算的成本可能是一個令人望而卻步的因素。

如果我們構建自定義REST-API作為機器學習模型的終點,則可以避免這些問題。特別是,本文將使用基于Python的Flask Web框架來為模型構建API,然后將這個flask應用程序整齊地集成到Docker映像中來進行部署。Docker顯然適合解決這個問題,因為應用程序的所有依賴項都可以打包在容器中,并且可以通過必要時刻簡單地部署更多容器來實現可伸縮性。這種部署架構本質上是可擴展的、成本有效的和便攜的。
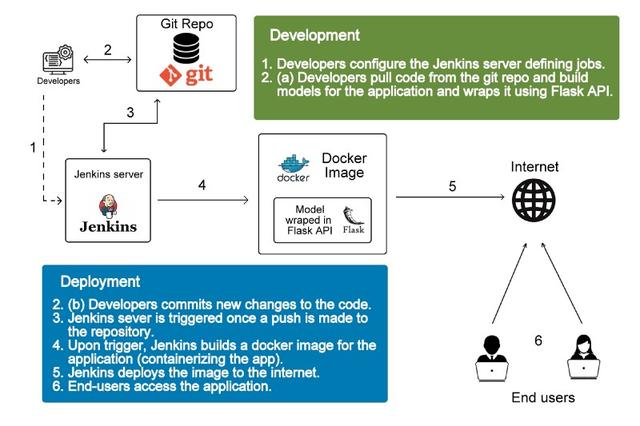
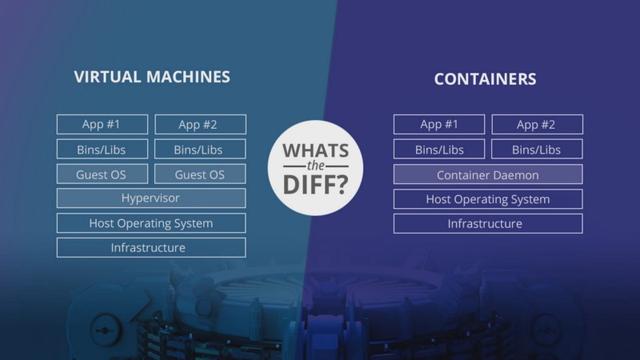
Docker:Docker是一種開源的容器化技術,允許開發人員將應用程序與依賴庫打包在一起,并將其與底層操作系統隔離開來。與VM不同,docker不需要每個應用程序的Guest虛擬機操作系統,因此可以維護輕量級資源管理系統。與容器相比,虛擬機更重量級,因此容器可以相對快速地旋轉,同時具有較低的內存占用,這有助于將來我們的應用程序和模型的可伸縮性。
Jenkins:Jenkins可能是最受歡迎的持續集成和持續交付工具,大約擁有1400個插件,可自動構建和部署項目。Jenkins提供了一個在其管道中添加GitHub web-hook的規定,這樣每次開發人員將更改推送到GitHub存儲庫時,它都會自動開始為修改后的模型運行驗證測試,并構建docker鏡像來進行部署。
ngrok:ngrok是一個免費工具,可將公共URL傳送到本地運行的應用程序它會生成一個可以在GitHub web-hook中用于觸發推送事件的URL。
Flask:Flask是一個用Python編寫的開源Web框架,內置開發服務器和調試器。雖然有許多可以替代Web框架來創建REST API,但Flask的簡單性備受青睞。
部署
你可能想知道“我進入了什么樣的環狀土地?”但我保證接下來的步驟將變得簡單實用。到目前為止,我們已經了解了部署體系結構中的不同組件以及每個組件的功能的簡要說明。在本節中,將介紹部署模型的詳細步驟。

部署過程可以暫時分為四個部分:構建和保存模型、使用REST API公開模型,將模型打包在容器內以及配置持續集成工具。
在繼續下一步之前,使用以下命令將GitHub存儲庫復制到本地計算機。 此存儲庫包含所有代碼文件,可用作部署自定義模型的參考。
git clone git@github.com:EkramulHoque/docker-jenkins-flask-tutorial.git注:雖然以上提到的步驟適用于Windows操作系統,但修改這些命令以在Mac或Unix系統上運行應該是很簡單的。
訓練和保存模型
在本例中,使用來自scikit-learn的鳶尾花數據集來構建我們的機器學習模型。在加載數據集后,提取用于模型訓練的特征(x)和目標(y)。為了進行預測,先創建一個名為“labels”的字典,其中包含目標的標簽名稱,這里將決策樹分類器用作模型。你可以在sklearn隨意嘗試其他分類器 ,通過調用模型上的方法來生成測試數據的預測標簽。
我們使用pickle庫將模型導出為pickle文件,并將模型保存在磁盤上。從文件加載模型后,我們將樣本數據作為模型的輸入并預測其目標變量。
#!/usr/bin/env python# coding: utf-8import picklefrom sklearn import datasetsiris=datasets.load_iris()x=iris.datay=iris.target#labels for iris datasetlabels ={ 0: "setosa


















