摘要
IN 一定走索引嗎?那當然了,不走索引還能全部掃描嗎?好像之前有看到過什么Exist,IN走不走索引的討論。但是好像看的太久了,又忘記了。哈哈,如果你也忘記了MySQL中IN是如何查詢的,就來復習下吧。
問題
問題要從之前的統計 店鋪數關注人數說起
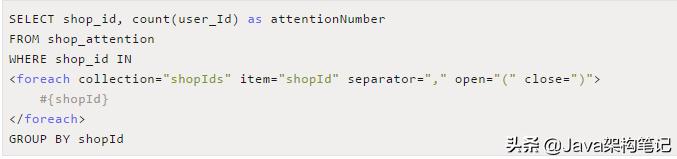
當時是從緩存的角度來分析如何進行優化。有興趣看這篇微服務化后緩存怎么做
將這個查詢收斂,應用端做了緩存后,確實沒什么大問題了。但是隨著店鋪關注數的增加,慢SQL開始出現了
在我們的業務中,將100ms的SQL查詢定義為慢查詢,需要優化的。優化不了必須要控制查詢頻次。同時超過5s的數據庫操作會被kill掉,防止拖垮整個數據庫,導致相關應用都受到牽連。
該SQL執行時間耗時已經幾百ms了,必須要優化了。阿里云對這個SQL的檢測報告時
掃描行數和返回行數比例超過了100使用了groupby函數,注意檢查groupby是否用到了索引分析
首先可以確定的是,group by 的 shop_id字段肯定是建了索引的,那么掃描行數和返回行數比例為什么這么大呢?
先復習下分析查詢語句的三大要素
- 響應時間,意思很明確,不多解釋了
- 掃描行數 整個查詢過程中掃描了多少行
- 返回行數 查詢結果命中的行數 一般來說掃描行數和返回行數一樣,是最好的,但是這是理想情況,事實并非如此。關聯查詢/范圍排序查詢時都會使得掃描行數大于返回行數。一般這個比例要控制在10以下,否則可能會有性能問題。
題外話,我一直覺得mysql explain的展示字段不如mongo的直觀。mongo索引原理同mysql一樣,有興趣的可以看下Mongo Index分析
那么現在問題來了,為什么這個查詢掃描行數/返回行數比例這么大呢。
那么就explain 一下了
實驗1

結果

和我預想的一樣,類型是 range走了shopId的索引,沒毛病。那怎么掃描行數/返回行數比例這么大的。
實驗2
再試一把,將IN的范圍增大了。

結果

結果不一樣了,類型是 index,也就是沒有走范圍掃描,而是走的是索引掃描。
實驗3
強制走索引

結果

這時候走的是范圍掃描,而不是索引掃描。但是你會發現這次的執行時間并不沒有比·上一次的執行時間短。
mysql對這個查詢進行了優化,使其不走范圍掃描。而是走的是索引掃描。那么必然會隨著IN的條件越來越多, 掃描的行數越多,執行的時間越長。
所以這個問題的優化的辦法呢,就是在應用端做切割,分批去查。每次查N個,保證每次的查詢都很快。
總結
根據實際的情況,需要控制IN查詢的范圍。原因有以下幾點
- IN 的條件過多,會導致索引失效,走索引掃描
- IN 的條件過多,返回的數據會很多,可能會導致應用堆內內存溢出。
所以必須要控制好IN的查詢個數
點擊了解更多獲取更多Java進階知識 !!!
↓↓↓↓↓↓



















