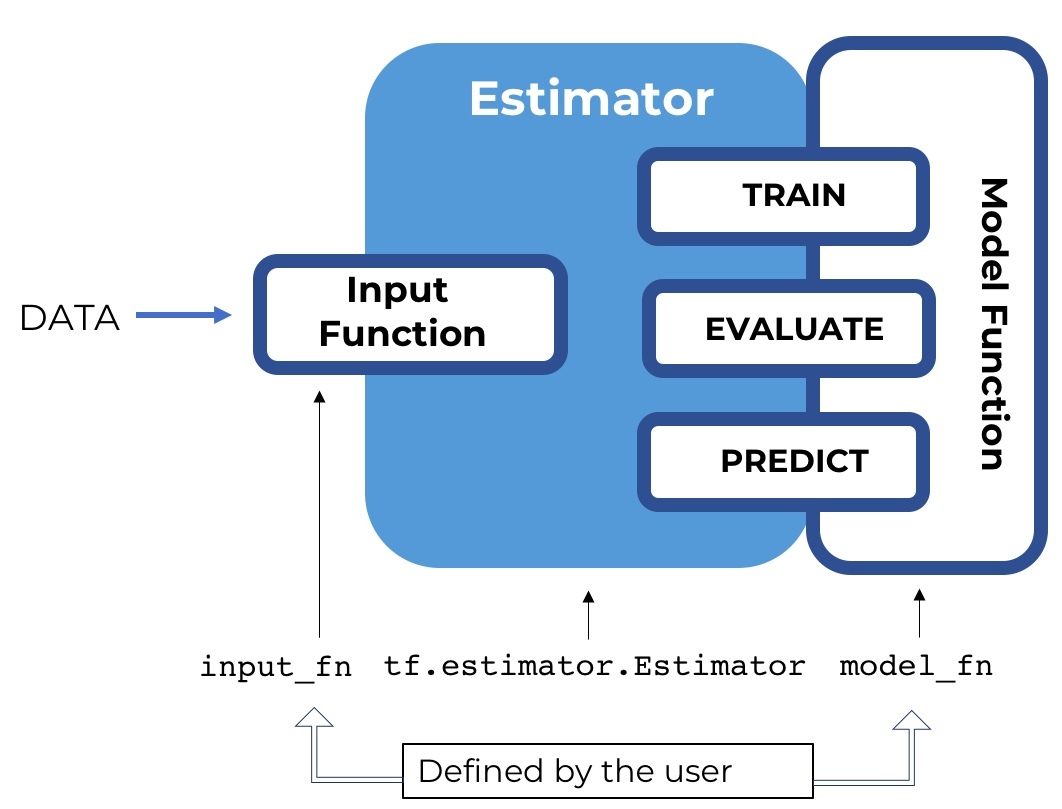
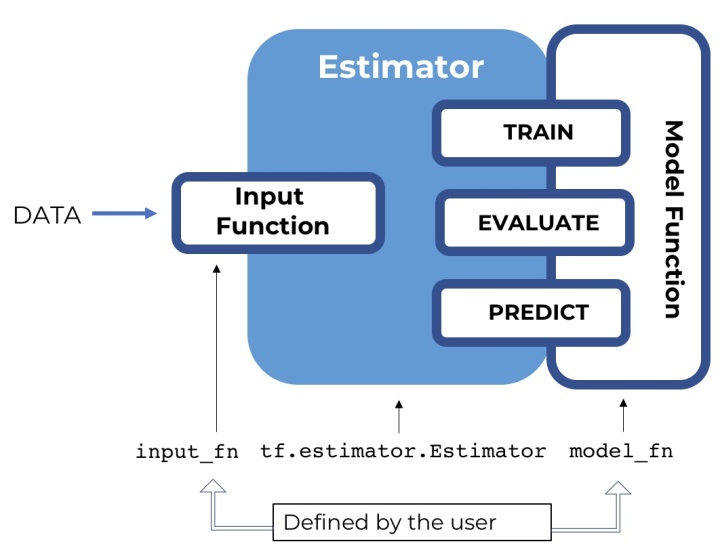
本文將主要介紹tensorflow 的Estimator 這個高級API,它的主要作用就是提出一個高級范式(paradigm),將模型的訓練,驗證,預測,以及保存規范起來,免去了tensorflow的Session.run 的操作,并且很好地結合了 tf.data.Dataset 作為數據處理的包裝,使得整個思路變得非常清晰。
Estimator 并沒有改變網絡結構的定義,而是將訓練,驗證,測試的管理抽象起來,并且簡單化,形成一個范式,用戶可以通過實現對應的部分,從而使得模型的管理便捷起來。
BERT的源碼實現采用的是TPU的estimator的方式,但是大家日常訓練模型的時候,很多都無法使用得?上TPU,雖然 TPUEstimator 會自動適配到CPU 或者 GPU 的普通 Estimator, 但是我在使用tensorflow==1.14.0的時候,會發現在訓練過程中的logging無法獲得訓練過程中的loss變化等,只有下圖的log信息。see github issue
具體改動后的代碼詳見:https://github.com/dongxiaohuang/TextClassifier_Transformer/blob/master/run_classifier_serving_gpu.py
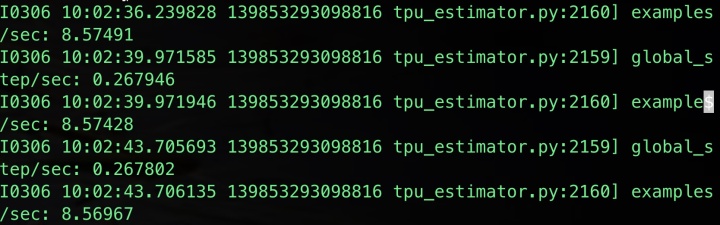
這些信息對于debug來說是遠遠不夠的,當然可以通過增加log hook的方式定時打印需要的log,但是即使這樣日志還是多條才看能到一次loss。于是我就將 TPUEstimator 收到改成普通的 Estimator 實現,并且成功地獲得正常的日志輸出。

本文將會介紹總體介紹 Estimator, 然后介紹各個component,并配以bert實現進行講解。有問題麻煩指出,謝謝。
Estimator 組成
首先我們創建一個estimator,它對外暴露了4個接口,分別是: train(), evaluate(), predict(), export_savedmodel(),對應的是模型的訓練,驗證,預測,以及導出。estimator 通過用戶實現 model_fn 構建模型,并且通過 model_fn 的實現不同的mode(ModeKeys.TRAIN,ModeKeys.EVAL,ModeKeys.PREDICT),返回不同的EstimatorSpec。
對于 train, evaluate, predict 都需要傳入相應的 input_fn, 代表訓練集,驗證集,以及測試集。input_fn 將返回features,以及lables。具體的 input_fn 的將會單獨介紹,我們只需要知道它構造 tf.data.Dataset, 作為estimator不同模式的數據源就行了。
def input_fn(dataset):... #manipulate dataset, extracting teh feature dict and the labelreturn feat_dict, label
我們可以通過不同hooks,在estimator執行的不同階段,執行自己的某些操作,例如增加log,或者是early stopping等。
使用 estimator 構建模型
使用 estimator 構建模型,你需要實現 model_fn(features, labels, mode, params) -> tf.estimator.EstimatorSpec , 該函數有嚴格的函數簽名,并且將會hold 模型圖定義。
- features:input_fn 返回的第一個參數,即輸入數據的特征Tensor
- labels: input_fn 返回的第二個參數,即輸入數據的label
- mode: string,根據這個mode (PREDICT, EVAL or TRAIN) 去決定我們要運行 model_fn 中哪一部分的graph要被建立。我們會在 model_fn 中實現三種模式的不同的graph,然后通過estimator的不同的方法(train/evaluate/predict)被調用,執行不同部分,而build 不同的graph。
- params:一個參數的字典,與 estimator 的參數之一 params 對應,例如我們有一個params 的字典
params = {'buffer': 15000,'lstm_size': 100,'words': str(Path(DATADIR, 'vocab.words.txt')),'chars': str(Path(DATADIR, 'vocab.chars.txt')),'tags': str(Path(DATADIR, 'vocab.tags.txt')),'glove': str(Path(DATADIR, 'glove.npz'))
}
我們要使用buffer,可以直接通過 params['buffer'] 使用。當然我們不使用這一參數也可以,我們可以通過構建一個 model_fn_builder() 將參數傳入這個builder中,最后返回 model_fn(),BERT中也是這么實現的,待會會具體介紹。
模型的 model_fn 的主要實現框架如下,通過features的輸入傳入模型,得到輸出,然后根據不同mode,實現特定輸出。Estimator是通過 model_fn 進行配置的,該函數構建了tensorflow的圖,并且返回了足夠的信息使得模型可以進行訓練,驗證,測試及導出。使用自定義的estimator只需要實現這個函數。大概的實現框架如下圖
def model_fn(features, labels, mode, params):# Define the inference graphgraph_outputs = some_tensorflow_applied_to(features)if mode == tf.estimator.ModeKeys.PREDICT:# Extract the predictionspredictions = some_dict_from(graph_outputs)return tf.estimator.EstimatorSpec(mode, predictions=predictions)else:# Compute loss, metrics, tensorboard summariesloss = compute_loss_from(graph_outputs, labels)metrics = compute_metrics_from(graph_outputs, labels)if mode == tf.estimator.ModeKeys.EVAL:return tf.estimator.EstimatorSpec(mode, loss=loss, eval_metric_ops=metrics)elif mode == tf.estimator.ModeKeys.TRAIN:# Get train operatortrain_op = compute_train_op_from(graph_outputs, labels)return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)else:raise NotImplementedError('Unknown mode {}'.format(mode))
定義inference 圖
首先我們將根據我們的特征輸入,構建我們的graph。下面的代碼主要是通過數據的features傳入 BERT模型, 然后獲得模型的loss, probabilities 等結果,然后通過預訓練模型進行初始化,具體原理參考BERT詳解。
# 正常圖構造
input_ids = features["input_ids"]
input_mask = features["input_mask"]
segment_ids = features["segment_ids"]
label_ids = features["label_ids"]
is_real_example = None
if "is_real_example" in features:is_real_example = tf.cast(features["is_real_example"], dtype=tf.float32)
else:is_real_example = tf.ones(tf.shape(label_ids), dtype=tf.float32)(total_loss, per_example_loss, probabilities, predictions) = create_model(albert_config, is_training, input_ids, input_mask,segment_ids, label_ids, num_labels, use_one_hot_embeddings)
# 模型參數通過預訓練模型進行初始化,fine-tuning
tvars = tf.trainable_variables()
initialized_variable_names = {}
if init_checkpoint:(assignment_map, initialized_variable_names) = modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint)tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
Train Mode
在訓練模式的時候,EstimatorSpec需要返回三個參數
- mode(所有模式都必須有的)
- loss:訓練的loss
- train_op:訓練的operation,一般是通過 optimizer.minimise(loss)
if mode == tf.estimator.ModeKeys.TRAIN:train_op = optimization.create_optimizer(total_loss, learning_rate, num_train_steps, num_warmup_steps, False)output_spec = tf.estimator.EstimatorSpec(mode=mode,loss=total_loss,train_op=train_op)
Eval Mode
在 tf.estimator.ModeKeys.EVAL 模式下,我們需要返回
- - mode
- - loss
- - eval_metric_ops: 評測的Metric operation 指標。這是一個字典(metrics dictionary)的形式,key是評測指標的名稱(string),value是tuple的形式,tuple由以下兩個tensor 組成:
- 第一個元素是 value_op,它指的是真實最終的metrics value。
- 第二個元素是 update_op,它指的是用來更新metrics value的tensor,為什么這樣設計是因為,我們通常在做驗證的時候,數據不能一下子fit進memory 或者其它原因,我們不能通過一次性在驗證集上進行驗證,我們是通過mini batch的方式進行評測的,而batch的方式就導致我們需要每驗證一個batch就更新我們的metrics value,而不是單獨地使用某一個batch的metrics value作為結果。
其中 Metrics 是layers的一個特殊類,通常用于做evaluation:它的輸入是真是值 labels,以及預測值 predictions,可選項權重weights;輸出是metric 例如說是 log-likelihood, accuracy,或者MSE等。該輸出由兩個Tensor組成,update op:這每一個 minibatch 都會計算; 然后是 value op:這個計算最后的metric value。所以我們可以借助metrics這個類,來計算我們需要的驗證指標,例如列了常見了幾種metric的計算方式,其中 tf_metrics以及ref 里面實現了accuracy以及recall,f1等評測指標。
'accuracy': tf.metrics.accuracy(labels=label_ids, predictions=predictions, weights=is_real_example)
'loss': tf.metrics.mean(values=per_example_loss, weights=is_real_example)
'Recall@5': metrics.streaming_sparse_recall_at_k(predictions, tf.cast(labels["class_idx"], tf.int64), 5)
'precision': tf_metrics.precision(tags, pred_ids, num_tags, indices, weights),
'recall': tf_metrics.recall(tags, pred_ids, num_tags, indices, weights),
'f1': tf_metrics.f1(tags, pred_ids, num_tags, indices, weights),
其中tf_metrics 可以通過以下指令安裝: pip install git+https://github.com/guillaumegenthial/tf_metrics.git
其中BERT的實現如下:
elif mode == tf.estimator.ModeKeys.EVAL:def metric_fn(per_example_loss, label_ids, predictions, is_real_example):accuracy = tf.metrics.accuracy(labels=label_ids, predictions=predictions, weights=is_real_example)loss = tf.metrics.mean(values=per_example_loss, weights=is_real_example)for metric_name, op in metrics.items(): # tensorboardtf.summary.scalar(metric_name, op[1])return {"eval_accuracy": accuracy,"eval_loss": loss,}eval_metric_ops = metric_fn(per_example_loss, label_ids, predictions, is_real_example)output_spec = tf.estimator.EstimatorSpec(mode=mode,loss=total_loss,eval_metric_ops=eval_metric_ops
Prediction Mode
prediction mode是最簡單的模式,我們需要返回:
- mode
- predictions:這是一個字典,字典的key是我們要返回的tensor的名字,字典的value是我們要返回的tensor,例如說, 我們需要返回兩個tensor,分別是 probabilities, predictions, 我們將他們直接構建一個字典,傳入predictions這個參數中。
_,top_3 = tf.nn.top_k(probabilities,k=3)
output_spec = tf.estimator.EstimatorSpec(mode=mode,predictions={"probabilities": probabilities,"predictions": predictions,"top_3":top_3})
BERT的model_fn 實現
bert的 model_fn 實現,并沒有使用到estimator傳入的params,而是通過構建一個 model_fn_builder, 將各種參數傳入其中,最后返回需要的 model_fn(features, labels, mode, params) 函數。
def model_fn_builder(albert_config, num_labels, init_checkpoint, learning_rate,num_train_steps, num_warmup_steps, use_one_hot_embeddings):def model_fn(features, labels, mode, params): # pylint: disable=unused-argument"""The `model_fn` for TPUEstimator."""tf.logging.info("*** Features ***")for name in sorted(features.keys()):tf.logging.info(" name = %s, shape = %s" % (name, features[name].shape))input_ids = features["input_ids"]input_mask = features["input_mask"]segment_ids = features["segment_ids"]label_ids = features["label_ids"]is_real_example = Noneif "is_real_example" in features:is_real_example = tf.cast(features["is_real_example"], dtype=tf.float32)else:is_real_example = tf.ones(tf.shape(label_ids), dtype=tf.float32)is_training = (mode == tf.estimator.ModeKeys.TRAIN)(total_loss, per_example_loss, probabilities, predictions) = create_model(albert_config, is_training, input_ids, input_mask,segment_ids, label_ids, num_labels, use_one_hot_embeddings)tvars = tf.trainable_variables()initialized_variable_names = {}if init_checkpoint:(assignment_map, initialized_variable_names) = modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint)tf.train.init_from_checkpoint(init_checkpoint, assignment_map)tf.logging.info("**** Trainable Variables ****")for var in tvars:init_string = ""if var.name in initialized_variable_names:init_string = ", *INIT_FROM_CKPT*"tf.logging.info(" name = %s, shape = %s%s", var.name, var.shape,init_string)output_spec = Noneif mode == tf.estimator.ModeKeys.TRAIN:train_op = optimization.create_optimizer(total_loss, learning_rate, num_train_steps, num_warmup_steps, False)output_spec = tf.estimator.EstimatorSpec(mode=mode,loss=total_loss,train_op=train_op)elif mode == tf.estimator.ModeKeys.EVAL:def metric_fn(per_example_loss, label_ids, predictions, is_real_example):accuracy = tf.metrics.accuracy(labels=label_ids, predictions=predictions, weights=is_real_example)loss = tf.metrics.mean(values=per_example_loss, weights=is_real_example)return {"eval_accuracy": accuracy,"eval_loss": loss,}eval_metric_ops = metric_fn(per_example_loss, label_ids, predictions, is_real_example)output_spec = tf.estimator.EstimatorSpec(mode=mode,loss=total_loss,eval_metric_ops=eval_metric_ops)else:output_spec = tf.estimator.EstimatorSpec(mode=mode,predictions={"probabilities": probabilities,"predictions": predictions})return output_specreturn model_fn
初始化Estimator
在定義完estimator之后,就可以初始化estimator了,estimator有四個參數:
- model_fn:我們上面定義的模型model_fn
- model_dir:模型保存的路徑,如果沒有設置,會使用config中的 model_dir 參數的值,如果兩個都設置了,必須一致,如果兩個都沒有設置,那么將會保存在一個temp的路徑下。
- config:estimator的config,下面會具體介紹
- params=None:params,字典形式,將會傳給model_fn的params參數
- warm_start_from:string,checkpoint or SavedModel的文件路徑用來warm_start
RunConfig
Runconfig主要用來設置模型保存的路徑model_dir, 以及模型保存的頻率 save_checkpoints_steps or save_checkpoints_secs (默認是600 seconds 保存一次,如果兩個參數都設置未None,則不保存),以及Session的設置 session_config,例如說XLA是否開啟等等。 或者說分布式策略設置train_distributeor eval_distribute 等等。
config = tf.compat.v1.ConfigProto()if FLAGS.horovod:tf.compat.v1.logging.info("Multi-GPU training with TF Horovod")tf.compat.v1.logging.info("hvd.size() = %d hvd.rank() = %d", hvd.size(), hvd.rank())global_batch_size = FLAGS.train_batch_size * FLAGS.num_accumulation_steps * hvd.size()master_process = (hvd.rank() == 0)hvd_rank = hvd.rank()config.gpu_options.visible_device_list = str(hvd.local_rank())if FLAGS.use_xla:config.graph_options.optimizer_options.global_jit_level = tf.compat.v1.OptimizerOptions.ON_1run_config = tf.estimator.RunConfig(model_dir=FLAGS.output_dir if master_process else None,session_config=config,save_checkpoints_steps=FLAGS.save_checkpoints_steps if master_process else None,keep_checkpoint_max=1)
實例化代碼
estimator = tf.estimator.Estimator(model_fn=model_fn,config=run_config,params=None)
Estimator使用
estimator初始化完了之后,我們就很容易通過調用它的train 進行訓練, 調用 evaluate進行驗證, 調用predict 進行預測,同時調用export_saved_model導出SavedModel。通常我們還可以使用tf.estimator.train_and_evaluate()進行模型的訓練及驗證(推薦)。
訓練
訓練的腳本很簡單,我們傳入訓練的input_fn(暫不cover在這個tutorial),以及hooks(下面會介紹),以及saving_listeners(每次checkpoint保存之后執行)。 train( input_fn, hooks=None, steps=None, max_steps=None, saving_listeners=None ) 具體的bert訓練的腳本就是如下:
num_train_steps = int(len(train_examples) / FLAGS.train_batch_size * FLAGS.num_train_epochs)
estimator.train(input_fn=train_input_fn,max_steps=num_train_steps,hooks=[early_stopping_hook])
驗證
evaluate(input_fn, steps=None, hooks=None, checkpoint_path=None, name=None
)
evaluate 函數將傳入驗證集的input_fn,驗證的步數steps, hooks,以及模型的 checkpoint_path 注意如果:
- steps:驗證步數,如果未None,則運行到input_fn raises an end-of-input exception.
- checkpoint_path:需要驗證的模型的路徑,如果 None, 會使用 model_dir 中最新的checkpoint。如果 model_dir 不存在或者沒有checkpoints,會使用新初始化的參數下去驗證,在我們bert例子中,就是用預訓練的模型而不是fine-tuning的模型下去驗證。
函數返回值是一個字典,即我們定義在 tf.estimator.ModeKeys.EVAL 模式下的字典結果。
result = estimator.evaluate(input_fn=eval_input_fn, steps=None, checkpoint_path=None)
for key in sorted(result.keys()):tf.logging.info(" %s = %s", key, str(result[key]))
預測
predict共有五個參數
predict(input_fn, predict_keys=None, hooks=None, checkpoint_path=None,yield_single_examples=True
)
- input_fn:測試集的傳入input_fn
- predict_keys:list,如果未None,則返回所有的tf.estimator.EstimatorSpec里的 predictions 的所有key的值,否則,則只返回 predict_keys 里的key的值,過濾掉其他的keys。
- checkpoint_path:這個作用和evaluate的作用一致,如果沒指定,則使用 model_dir 里最新的checkpoint,還是沒有的話,則使用新初始化的參數模型進行預測。
- yield_single_examples:True 返回的結果以單條呈現,否則則按照feed進predictor的batch返回。
返回的是一個generator,yield 的是values of predictions tensors,其為字典形式,根據EstimatorSpec中predictions來的。我們要取用某個值時,跟平常字典使用類似。 例如我們要取得我們bert中的 probabilities 的值,我們可以采用以下的方式:
result = estimator.predict(input_fn=predict_input_fn)
for (i, (example, prediction)) in enumerate(zip(predict_examples, result)):probabilities = prediction["probabilities"]
導出
tensorflow具有三種模型保存的方式
- checkpoint
- SavedModel
- frozen graph
之后會專門出一篇介紹, 并介紹如何使用SavedModel進行single example和batch預測。我們這邊主要講一下 export_saved_model API,
export_saved_model(export_dir_base, serving_input_receiver_fn, assets_extra=None, as_text=False,checkpoint_path=None, experimental_mode=ModeKeys.PREDICT
)
- export_dir_base: 導出的路徑,導出SavedModel
- serving_input_receiver_fn: 一個無參函數,返回 tf.estimator.export.ServingInputReceiver or tf.estimator.export.TensorServingInputReceiver.具體的作用就是定義我們模型的輸入placeholders。
- assets_extra: 一個字典說明如何在SavedModel 路徑下產生assets.extra 文件夾,None 代表不產生。
- as_text: 是否將 SaveModel 保存為 Text 格式
- checkpoint_path: 要被導出的checkpoint的路徑,如果是None,則使用 model_dir 里最新的checkpoint
- experimental_mode: tf.estimator.ModeKeys 值,代表哪一個Mode要被exported。正常來說默認是 ModeKeys.PREDICT
具體可以參考:
def serving_input_fn():label_ids = tf.placeholder(tf.int32, [None], name='label_ids')input_ids = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='input_ids')input_mask = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='input_mask')segment_ids = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='segment_ids')input_fn = tf.estimator.export.build_raw_serving_input_receiver_fn({'label_ids': label_ids,'input_ids': input_ids,'input_mask': input_mask,'segment_ids': segment_ids,})()return input_fnif FLAGS.do_export:estimator._export_to_tpu = Falseestimator.export_saved_model(FLAGS.output_dir, serving_input_fn)train_and_evaluate
這個工具函數提供了一個estimator的train,evaluate,和export(可選)的接口。
所有訓練相關的配置都在 train_spec 中配置(包括training input_fn 和 training max steps, etc),所有的驗證相關的配置都在 eval_spec 中(evaluation input_fn 和 steps, etc),
這個函數函數的好處在于他將train 和 evaluate結合起來,然后在訓練和驗證之間的轉換的時候,不需要銷毀和重建graph,而之前的 estimator.train 和 estimator.evaluate 是異步的。使用這個函數之后,就能夠很高效地實現訓練和驗證集合。并且它支持分布式訓練等。 此外它支持導出最優模型的配置 BestExporter。
具體參考下面BERT的使用:
if FLAGS.do_train:train_spec = tf.estimator.TrainSpec(input_fn=train_input_fn,max_steps=num_train_steps,hooks=[early_stopping_hook])exporter = tf.estimator.BestExporter(serving_input_receiver_fn= serving_input_fn,exports_to_keep=2)eval_spec = tf.estimator.EvalSpec(input_fn=eval_input_fn,steps=None, # steps=None, evaluate on the entire eval datasetexporters=exporter)tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
注意:EvalSpec中的 steps需要顯性設置未None, 否則默認是100。并不是在整個驗證集上面進行驗證。
hooks
我們可以為訓練 estimator.train() 和測試 estimator.evaluate() 增加hooks。hooks 顧名思義,就是鉤子,指的是如果一個事件發生了,先被特定hook捕獲,然后執行hook的操作,然后在傳入下個pipeline。也即這項技術就是提供了一個入口,能夠針對不同的消息或者API在執行前,先執行你的操作,你的操作也稱為「鉤子函數。
常見的操作有
- early_stopping_hooks
我們可以通過tf.estimator.experimental.stop_if_no_decrease_hook 或者 tf.contrib.estimator.stop_if_no_increase_hook 實現early stopping hook。比如說eval_loss 多少個steps都不下降,那么我們啟動early stopping,或者說 f1 在多少個steps都不上升,那么我們進行early stopping。因為 hook somehow 假設模型 model’s eval_dir 已經存在,所以我們需要在其未存在的時候提前創建路徑。
具體參考下面的代碼:
Path(estimator.eval_dir()).mkdir(parents=True, exist_ok=True)
early_stopping_hook = tf.estimator.experimental.stop_if_no_decrease_hook(estimator=estimator,metric_name='eval_loss',max_steps_without_decrease=3*FLAGS.save_checkpoints_steps,eval_dir=None,min_steps=0,run_every_secs=None,run_every_steps=FLAGS.save_checkpoints_steps)
或者是
Path(estimator.eval_dir()).mkdir(parents=True, exist_ok=True)
hook = tf.contrib.estimator.stop_if_no_increase_hook(estimator, 'f1', 500, min_steps=8000, run_every_secs=120)
- LoggingHooks
logging_hook = tf.train.LoggingTensorHook({"loss": total_loss}, every_n_iter=10)
然后將我們這個hook加到
estimator.train(input_fn=train_input_fn,max_steps=num_train_steps,hooks=[early_stopping_hook, logging_hook])
或者是
train_spec = tf.estimator.TrainSpec(input_fn=train_input_fn,max_steps=num_train_steps,hooks=[early_stopping_hook, logging_hook])
ref
- https://towardsdatascience.com/first-contact-with-tensorflow-estimator-69a5e072998d
- https://arxiv.org/pdf/1708.02637.pdf
- https://towardsdatascience.com/an-advanced-example-of-tensorflow-estimators-part-1-3-c9ffba3bff03
- https://guillaumegenthial.github.io/serving-tensorflow-estimator.html
- https://github.com/tensorflow/docs/blob/master/site/en/guide/estimator.ipynb
- https://b23.tv/av80286594/p1
- https://guillaumegenthial.github.io/introduction-tensorflow-estimator.html
- https://github.com/NVIDIA/DeepLearningExamples/tree/master/TensorFlow/LanguageModeling/BERT








)










