
導讀
1. 什么是圖?圖的存儲方式?
2. 圖的遍歷(深度優先搜索,廣度優先搜索)
3. 最短路徑
1. 什么是圖?圖的存儲方式?
前面總結了“樹”這種數據結構,而這篇博客總結的是更為復雜的一種數據結構:圖(graph),它表明了物件與物件之間的“多對多”的一種復雜關系。圖包含了兩個基本元素:頂點(vertex, 簡稱V)和邊(edge,簡稱E)。
有向圖與無向圖
如果給圖的每條邊規定一個方向,那么得到的圖稱為有向圖。在有向圖中,從一個頂點出發的邊數稱為該點的出度,而指向一個頂點的邊數稱為該點的入度。相反,邊沒有方向的圖稱為無向圖。
有權圖與無權圖
如果圖中的邊有各自的權重,得到的圖是有權圖。比如地鐵路線圖,連接兩站的邊的權重可以是距離,也可以是價格,或者其他。反之,如果圖的邊沒有權重,或者權重都一樣(即沒有區分),稱為無權圖。
連通圖
如果圖中任意兩點都是連通的,那么圖被稱作連通圖。圖的連通性是圖的基本性質。無向圖中的一個極大連通子圖稱為其的一個連通分量。有向圖中,如果對任意兩個頂點
圖的存儲
常用的存儲方式有兩種:鄰接矩陣和鄰接表。
鄰接矩陣
采用一個大小為
一般情況下我用的鄰接矩陣的結構和初始化代碼如下,具體會根據使用需求有所改動。
struct GNode{int Nv; // number of verticesint Ne; // number of edgesint G[MaxVNum][MaxVNum];
};
typedef struct GNode *MGraph;
MGraph Graph = new GNode[MaxVNum];// 初始化圖
void InitGraph(int N,int E){Graph->Nv = N;Graph->Ne = E;for (int u=0;u<=N;u++)for (int v=0;v<=N;v++)Graph->G[u][v]=INF;
}
//插入邊(這里是有權重的無向邊)
void InsertEdge(int u,int v,int weight){Graph->G[u][v]= weight;Graph->G[v][u]=weight;
}鄰接表

另外,之前做習題的時候也會習慣用個二維數組來存儲鄰接表,比如上面的
一般情況下我用的代碼如下,會根據具體需求有大改動。
typedef struct VNode *AdjNode;
struct VNode{int node;AdjNode next;
};
AdjNode Graph = new VNode[MaxV];void InitGraph(int N,int E){Graph->Nv = N;Graph->Ne = E;for (int i=1;i<=N;i++){(Graph+i)->node=i;(Graph+i)->next=NULL;}
}
// 插入有向邊
void InsertEdge(int u,int v){AdjNode tmp1=new VNode;AdjNode tmp2 = new VNode;tmp1->node = v;tmp1->next = (Graph+u)->next;(Graph+u)->next=tmp1;tmp2->node = u;tmp2->next = (Graph+v)->next;(Graph+v)->next=tmp2;
}2. 圖的遍歷
圖的遍歷最常用的有兩種:深度優先搜索(Depth-first Search, DFS)和廣度優先搜索(Breadth-First Search, BFS)。
深度優先搜索
有點類似于樹的前序遍歷,即從一個選定的點出發,選定與其直接相連且未被訪問過的點走過去,然后再從這個當前點,找與其直接相連且未被訪問過的點訪問,每次訪問的點都標記為“已訪問”,就這么一條道走到黑,直到沒法再走為止。沒法再走怎么辦呢?從當前點退回其“來處”的點,看是否存在與這個點直接相連且未被訪問的點。重復上述步驟,直到沒有未被訪問的點為止。
從上述文字表述可以看出,DFS很適合使用遞歸,其代碼如下:
int visited[MaxN]={0}; //記錄頂點的訪問狀態
int result[MaxN]; //result數組記錄DFS遍歷結果
int N,E,k;// N為頂點數,E為邊數,k記錄遍歷結果下標void DFS(int v){visited[v]=1;result[k++]=v;for (int i=0;i<N;i++){if (G[v][i]==1 && visited[i]==0)DFS(i);}
}int main(){for (int i=0;i<N;i++){k = 0;if (visited[i]==0){DFS(i);//用{}打印出一個連通分量cout<<"{ ";for (int j=0;j<k;j++)cout<<result[j]<<' ';cout<<"}"<<endl;}}
return 0;
}廣度優先搜索
有點類似于樹的層序遍歷,也就是像剝洋蔥一樣,“一層一層地剝開???”。即從一個選定的點出發,將與其直接相連的點都收入囊中,然后依次對這些點去收與其直接相連的點。重復到所有點都被訪問然后結束。
類似樹的層序遍歷,BFS同樣可以通過一個隊列來實現,代碼如下:
int visited[MaxN]={0}; //記錄頂點的訪問狀態
int result[MaxN]; //result數組記錄BFS遍歷結果
int N,E,k;// N為頂點數,E為邊數,k記錄遍歷結果下標void BFS(int v){queue<int> q;q.push(v);visited[v]=1;result[k++]=v;while(!q.empty()){int u = q.front();q.pop();for(int i=0;i<N;i++){if (G[u][i]!=0 && visited[i]!=1){visited[i]=1;q.push(i);result[k++]=i;}}}
}int main(){for (int i=0;i<N;i++){k = 0;if (visited2[i]==0){BFS(i);//用{}打印出一個連通分量cout<<"{ ";for (int j=0;j<k;j++)cout<<result[j]<<' ';cout<<"}"<<endl;}}
return 0;
}上述BFS和DFS的時間復雜度均為。
3. 最短路徑
簡而言之,最短路徑就是找圖中連接兩個頂點所有邊權重和最小的路徑。
- 對無權圖而言,即是找邊最小的路徑;
- 如果給定起點,則是單源最短路徑,即從一固定起點到任意終點的最短路徑;
- 如果起點不確定,則是多源最短路徑,即求任意兩個頂點的最短路徑。
單源最短路徑
對于無向圖而言,可以借助BFS的“剝洋蔥”特性,看從起點到終點需要剝幾個洋蔥圈,剝的層數即是最短路徑長度。
對于有向圖而言,就不得不提到一個煊赫的名字:Dijkstra算法。陸續泛聽了幾個版本的數據結構,這個名字簡直太深入人心。
- Dijkstra算法
具體來說,Dijkstra算法的核心在于:從起點(或者說源點)開始,將其裝進一個“袋子”里,然后不斷往這個袋子里搜羅頂點,當頂點收進去后,能保證從源點到該頂點的當前最短路徑是確定的。每次收錄的頂點是在未收錄的集合里尋找最短路徑最小的點(即離源點最近的點),然后將與收進去的頂點直接相連的點的最短路徑進行更新。
如下圖所示,
值得注意的是:Dijkstra算法不適用于存在負權重邊的圖。
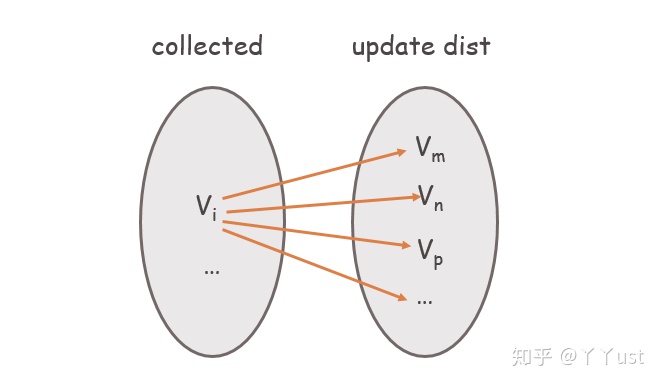
給出Dijkstra代碼前先對保存最短路徑的數組dist[]和收錄狀態的數組collected[]進行初始化:和源點直接相連的點的最短路徑即為該邊的權重,其余均初始化為一個很大的(一看就不可能的數)INF;collected中所有值初始化為false。
int dist[MaxN];
bool collected[MaxN];void InitDist(int start){for (int i=0;i<Graph->Nv;i++){dist[i]=Graph->G[start][i];collected[i]=false;}
}然后,我們需要尋找下一步被收錄的點:即在所有未被收錄的點中尋找dist最小的點。如果不存在(最小值為無窮大INF),則返回錯誤標識-1。這一步找最小值,我們可以每次都將所有頂點掃描一遍獲得,也可以很自然地想到將dist存在一個最小堆(優先隊列)里。對于前者,因為每次收錄都要掃描一次所有頂點,有
int findMinDist(int start){int MinD = INF;int MinV;for (int end =0;end<Graph->Nv;end++){if (collected[end]==false && dist[end]<MinD){MinD=dist[end];MinV=end;}}if (MinD<INF)return MinV;elsereturn -1;
}然后是Dijkstra算法主程序:在初始化后,先將源點收錄進袋,并且源點的最短路徑設為0, 然后開始循環尋找能被收錄的點:如果接受到的是錯誤標識-1,說明找不到符合要求的點了,程序結束。如果找到了,則先將這個點收錄進去,記錄為s; 然后遍歷從s出發的所有邊,對沒有收錄的點,更新他們的最小路徑值。更新的依據是:如果這個點t的當前的最小路徑值,大于s點的最小路徑值與s到t邊的權重值之和,則更新為
bool dijkstra(int start){InitDist(start);dist[start]=0;collected[start]=true;int s;while (1){s = findMinDist(start);if (s==-1)break;collected[s]=true;for (int t=0;t<Graph->Nv;t++){// if W is not collected and s->t existsif (collected[t]==false && Graph->G[s][t]<INF){// check if it is a negative-weighted edgeif (Graph->G[s][t]<0) return false;// check if dist[t] needs updateif (dist[t]>dist[s]+Graph->G[s][t])dist[t]=dist[s]+Graph->G[s][t];}}}return true;
}多源最短路徑
按照上面已有的Djikstra算法,可以直接將Djikstra算法在每個頂點調用一遍,然后找最小值。時間復雜度為:
直接找dist最小:。
最小堆維護dist:。
另外還有一種更為直接的算法是Floyd算法,且代碼看著簡潔直觀優美。。。
bool Floyd(){int i, j, k;for (k=0;k<Graph->Nv;k++)for (i=0;i<Graph->Nv;i++)for (j=0;j<Graph->Nv;j++)if (dist[i][k]+dist[k][j]<dist[i][j]){dist[i][j]=dist[i][k]+dist[k][j];if (i==j && dist[i][j]<0) //發現負值回路return false;}return true;
}三重循環嵌套,可以直觀看出時間復雜度為
參考資料:
- coursera的《算法分析與設計》(以前的課程)
- MOOC網的《數據結構與算法》
小結
距離上次更新已經有很長的時間,一方面是因為沒整理好,包括現在記錄的也覺得很混亂,就這么先把筆記記下來吧,不然時間久了更迷糊。另一方面是身體原因,年紀輕輕竟然椎間盤膨出了,不知道知乎上有沒有啥治療良方,反正去了好幾次醫院都說沒事,直到痛得不行讓拍CT了才知道是腰椎間盤膨出???
扯遠了???,剩下還有一些最小生成樹,和拓撲排序啥的等我更明白點再寫吧~~~









 for 'xxx' is missing)



案例...)

)



