
跟aggregate一樣,transform也是一個有著嚴格條件的特殊函數:傳入的函數只能產生兩種結果,要么產生一個可以傳播的標量值(如np.mean),要么產生一個相同大小的結果數組。最一般化的GroupBy方法是apply,apply會將待處理的對象拆分成多個片段,然后對各片段調用傳入的函數,最后嘗試將各片段組合到一起。
apply方法
舉例:根據分組選出最高的5個tip_pct值。
首先,編寫一個選取指定列具有最大值的行的函數。(原文比較拗口,其實就是“在 指定列找出最大值,然后把這個值所在的行選取出來。”)
In [1]: def top(df,n=5,column='tip_pct'): ...: return df.sort_index(by=column)[-n:] ...: 新寫法:注意與上面的差別
In [2]: def top(df,n=5,column='計劃發出單量'): ...: return df.sort_values(by=column)[-n:] ...:In [3]: top(tips,n=6)Out[3]: total_bill tip smoker day time size tip_pct109 14.31 4.00 Yes Sat Dinner 2 0.279525183 23.17 6.50 Yes Sun Dinner 4 0.280535232 11.61 3.39 No Sat Dinner 2 0.29199067 3.07 1.00 Yes Sat Dinner 1 0.325733178 9.60 4.00 Yes Sun Dinner 2 0.416667172 7.25 5.15 Yes Sun Dinner 2 0.710345如果對smoker分組并用該函數調用apply,就會得到:
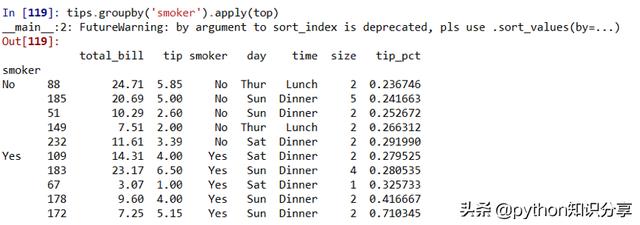
top函數在DataFrame的各個片段上調用,然后結果由pandas.concat組裝到一起,并以分組名稱進行了標記。于是,最終結果就有了一個層次化索引,其內層索引值來自原DataFrame。
如果傳給apply的函數能夠接受其他參數或關鍵字,則可以將這些內容放在函數名后面一并傳入:

注意:除這些基本用法之外,能否充分發揮apply的威力很大程度上取決于你的創造力。傳入的那個函數能做什么全由你說了算,它只需返回一個pandas對象或標量值即可。本章后續部分的示例主要用于講解如何利用groupby解決各種各樣的問題。
在GroupBy對象上調用describe:

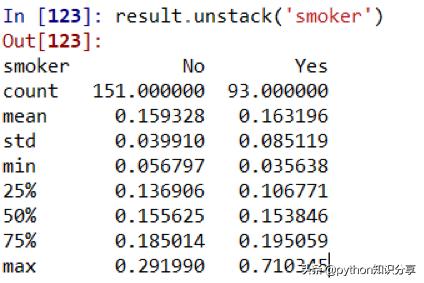
在GroupBy中,當調用諸如describe之類的方法時,實際上只是應用了下面兩條代碼的快捷方式而已:
f = lambda x: x.describe()
Grouped.apply(f)
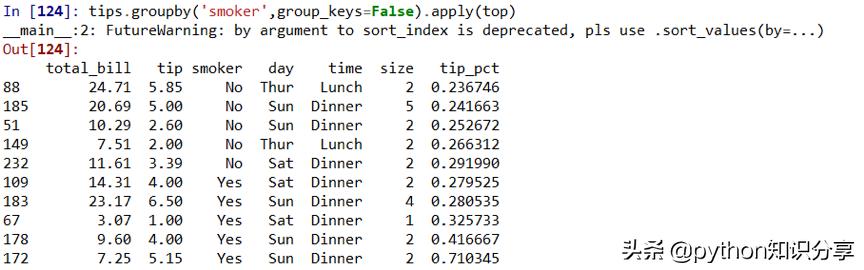
禁止分組鍵:group_keys=False
分組鍵會跟原始對象的索引共同構成結果對象中的層次化索引。將group_keys=False傳入groupby即可禁止該效果:
python好書推薦
推薦一本python好書,初學者和數據分析必備,小編已讀:
Slave DNS及高級特性)





![【洛谷 P2513】 [HAOI2009]逆序對數列(DP)](http://pic.xiahunao.cn/【洛谷 P2513】 [HAOI2009]逆序對數列(DP))

希爾排序)










