排序,也稱為排序算法,可以說是我們學習算法的過程中遇到的第一個門檻,也是實際應用中使用得較為頻繁的算法,我將自己對所學的排序算法進行一個歸納總結與分享,如有錯誤,歡迎指正!
排序算法學習分享(一)選擇排序
排序算法學習分享(二)交換排序---冒泡排序與快速排序
排序算法學習分享(三)插入排序
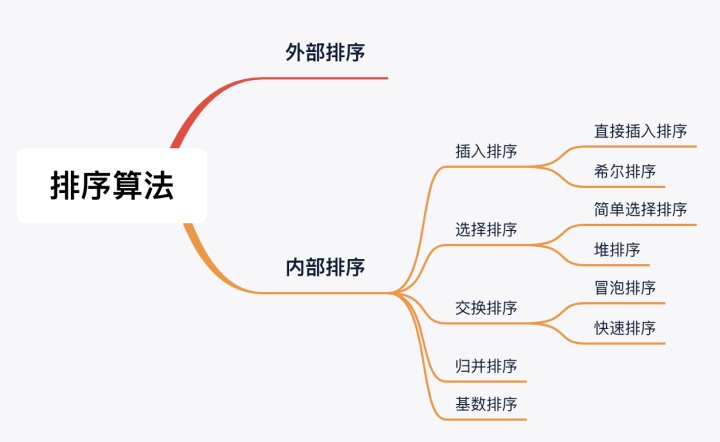
(一)排序的分類
排序算法主要分為內部排序與外部排序,當數據量大時,數據無法全部加載到內存中,因此需要接抓外部存儲(文件、磁盤等)進行排序。而內部排序則是指將要處理的所有數據加載到內部存儲器中,并在內存中就完成排序。
本文針對的為內部排序。
(二)內部排序
4 希爾排序
前文我介紹了插入排序,但是插入排序會出現一個問題。如果我們拿到的是一個較小的數進行插入排序,那么元素后移的次數會明顯增加,那么就會嚴重影響整個排序的效率。
接下來介紹的希爾排序就是經典的對插入排序的一種優化。
希爾排序,也稱遞減增量排序,是插入排序的一種更高效的改進版本。我們都知道,插入排序對已經有序的或者是有序程度高的序列排序是非常快的,但一般情況下,由于插入排序每插入一個元素都只能一個一個元素地進行移動,因此它的效率是十分低下的。
顯然要優化插入排序的移動是很困難的,而希爾排序取巧地不去優化它的移動,希爾排序的思想我用一句話去概括:盡可能的在數組進行下一輪的排序時,提高數組的有序程度。
先記住一點:在序列的排序中,元素越少,需要交換的次數越少,排序越快。
那么怎么去提高一個數組的有序程度呢?用一個很有趣的東西——增量。
這類似于分治思想,但它又不是。希爾排序利用增量這一個東西去將序列分割成若干個子序列,再將每個子序列分別排好。 那么究竟什么是增量?又要怎么利用增量?
增量就是一個等差數列的差值,比如1,3,5,7,9。它們的增量是2。一開始盡可能使用一個大的增量,使得每個子序列中的元素少,比如第一輪就盡量使得一個子序列的元素只有兩個。
增量越大,那么分的組就會越多,每個組中的元素數目就會小。每一輪都比上一輪的增量按照一定的規律遞減,那么分的組就會比上一輪的分的組少,而每個組中的元素就要比上一輪的元素要多,當增量一直減到1的時候,我們就會發現只有一個組了,而這個組中的元素就是整個序列的所有元素,這就是遞減增量。
利用增量這樣子分割序列是為了什么呢?是為了使下一輪的有序程度變高。為什么我說希爾排序是一種取巧呢?就是因為它耍賴皮,有序程度低的時候,增量就大,分組就多,組內元素就少,排序就快。當這一輪排序完成的時候,全體序列的有序程度一定是要比上一輪的有序程度要高的(有一些特殊情況,嚴謹地應該說是不低于)。
增量每一次發生遞減,那么序列的有序程度就提高了那么一點,當增量遞減到1的時候,序列的有序程度就已經很高的,這時再進行一輪插入排序,就很快了。
這么將還是有些抽象,我們舉一個實例,上一些圖來說明。

這是一個原始數組,可以看到它的有序程度并不高。
我們對它進行第一次增量分組,使得每組中的元素盡可能少。最少的話是一個元素一個組,但是如果組中只有一個元素,那么組內的排序根本沒有意義,因此第一次的這個盡可能少,就是兩兩一組。此時的增量為4。
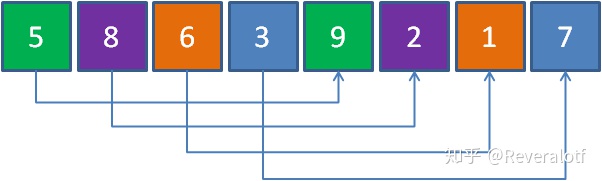
我們對每個子數組內進行排序。由于每個子數組內的元素很少,因此排序很快,排序完如下:
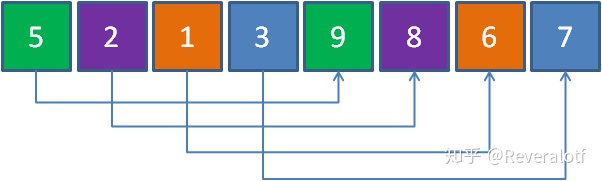
我們已經可以看到只是經過簡單的幾個交換后數組的有序程度就已經顯著提升了,那么接下來就是進入到下一輪。
遞減增量,直接使增量減半(希爾增量),新的增量為4 / 2 = 2,將2作為新的增量重新進行分組,分組如下。

我們對每個分組內進行排序,因為經過了上一輪的排序,可以看到每個組內的有序程度比上一輪如果也按照這個增量分組的有序程度要高。
這就達到了希爾排序的目的,就是每一輪都要比上一輪的有序程度要高,這很像我們做產品時候的不斷迭代。
排序好后如下:

這一輪結束后增量再遞減就變成1了,最后再進行一輪插入排序即可,此時需要移動的數僅僅就是5和3,8和9。有序程度比原數組高到不知道哪里去了。再來一輪插入排序就完成啦!

其實遞減增量的規則有很多種,不止折半這一種,有時候根據需求改變遞減增量的方式會取得更優的性能。
下面嘗試用代碼實現希爾排序:

希爾排序使用的增量是折半的方式遞減的,這種方式的增量叫做希爾增量。希爾排序利用增量分組粗調一般情況下是減少了插入排序的工作量,使得插入排序的時間復雜度低于O(n2)。
但是,在一種極端的情況下,希爾排序所做的粗略調整不但沒有減少插入排序的工作量,反而增大的插入排序的工作量。
舉一個例子:

我們利用希爾增量來分組,當增量為4時,分組為:(2,7),(1,6),(5,9),(3,8)。我們可以看到它在組內是有序的,再折半減少增量為2,分組為(2,5,7,9),(1,3,6,8),還是有序的,經過兩輪增量排序,它的有序程度并沒有提高,比起直接插入排序反而還增加分組排序的這一個步驟,增加了工作量。
會出現這種情況的原因在于希爾增量,希爾增量之間是等比的,這代表著等比之間是可以出現一定的盲區的,就像上面這個例子,就完美地處在了希爾增量之間的盲區。
那么才能使得增量之間沒有盲區呢?最好的方式就是使得每一輪彼此的增量“互質”。而增量的方式很多,最為典型的就是Hibbard增量和Sedgewick增量。因為本文講的是希爾排序,就不繼續往下介紹了。
希爾排序是一個不穩定的排序算法,是因為在分組的過程中,兩個元素的交換的跨度有時候是會很大的。比如m > i = j > k,而原數組是( i ,j ,k ,m ),那么第一輪希爾排序后,i 就到 j 后面了。
希爾排序的介紹就到這里啦!希爾排序的中心思想就是: 盡可能的在數組進行下一輪的排序前,提高數組的有序程度。即每一輪都比上一輪時候的有序程度要高。











文件分割(IO綜合例子))





 ICNet分割網絡學習)

