0. 簡介
3D占據預測在機器人感知和自動駕駛領域具有重要的潛力,它將3D場景量化為帶有語義標簽的網格單元。最近的研究主要利用3D體素空間中的完整占據標簽進行監督。然而,昂貴的注釋過程和有時模糊的標簽嚴重限制了3D占據模型的可用性和可擴展性。為了解決這個問題,《RenderOcc: Vision-Centric 3D Occupancy Prediction with 2D Rendering Supervision》提出了RenderOcc,一種新的范式,用于僅使用2D標簽訓練3D占據模型。具體地,我們從多視圖圖像中提取類似NeRF的3D體積表示,并利用體積渲染技術建立2D渲染,從而能夠通過2D語義和深度標簽直接進行3D監督。此外,我們引入了一種輔助射線方法來解決自動駕駛場景中稀疏視角的問題,利用連續幀來為每個對象構建全面的2D渲染。據我們所知,RenderOcc是首次嘗試僅使用2D標簽訓練多視圖3D占據模型,減少了對昂貴的3D占據注釋的依賴。大量實驗證明,RenderOcc實現了與完全受3D標簽監督的模型相當的性能,突顯了這種方法在實際應用中的重要性。我們的代碼可在Github找到。
1. 主要貢獻
針對上述問題,我們引入了RenderOcc,這是一種新的范式,用于訓練3D占據模型,使用2D標簽,而不依賴于任何3D空間注釋。如圖1所示,RenderOcc的目標是消除對3D占據標簽的依賴,僅依靠像素級的2D語義在網絡訓練期間進行監督。具體而言,它從多視圖圖像構建了類似NeRF的3D體積表示,并利用先進的體積渲染技術生成2D渲染。這種方法使我們能夠僅使用2D語義和深度標簽提供直接的3D監督。通過這種2D渲染監督,模型通過分析來自各種攝像機的相交錐體射線來學習多視圖一致性,從而更深入地理解3D空間中的幾何關系。值得注意的是,自動駕駛場景通常涉及有限的視角,這可能會影響渲染監督的有效性。考慮到這一點,我們引入了輔助射線的概念,利用相鄰幀的射線來增強當前幀的多視圖一致性約束。此外,我們還開發了一種動態采樣訓練策略,用于篩選出不對齊的射線,并同時減輕與其相關的額外訓練成本。本文主要貢獻總結如下:
- 我們引入了RenderOcc,這是一個基于2D渲染監督的3D占據框架。我們首次嘗試僅使用2D標簽訓練多視圖3D占據網絡,摒棄了昂貴且具有挑戰性的3D注釋。
- 為了從有限的視角學習有利的3D體素表示,我們引入了輔助射線來解決自動駕駛場景中稀疏視角的挑戰。同時,我們設計了一種動態采樣訓練策略,用于平衡和凈化輔助射線。
- 大量實驗證明,與受3D標簽監督的基線相比,RenderOcc在僅使用2D標簽時取得了競爭性的性能。這展示了2D圖像監督在3D占據訓練中的可行性和潛力。
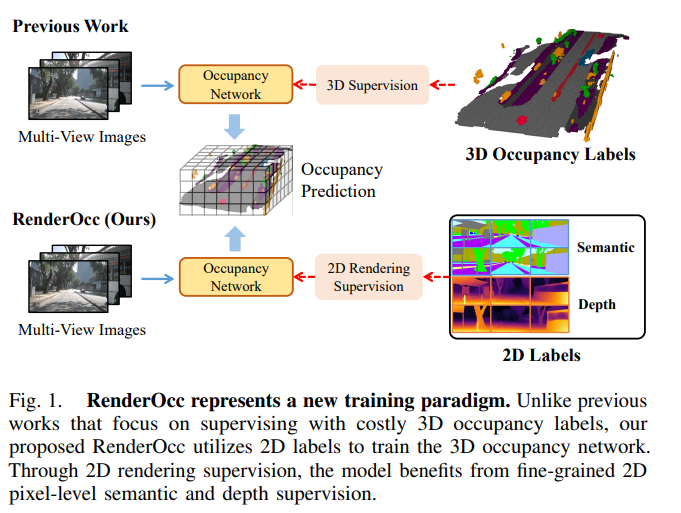
圖1. RenderOcc代表了一種新的訓練范式。與以往側重于使用昂貴的3D占據標簽進行監督的作品不同,我們提出的RenderOcc利用2D標簽來訓練3D占據網絡。通過2D渲染監督,模型可以從細粒度的2D像素級語義和深度監督中受益。
2. 問題設置
我們的目標是利用多攝像頭RGB圖像來預測周圍場景的密集語義體積,稱為3D占據情況。具體來說,對于時間戳 t t t的車輛,我們將 N N N個圖像 { I 1 , I 2 , ? ? ? I N } \{I^1,I^2,···I^N\} {I1,I2,???IN}作為輸入,并預測3D占據情況 O ∈ R H × W × D × L O ∈ \mathbb{R}^{H×W×D×L} O∈RH×W×D×L作為輸出,其中 H H H、 W W W、 D D D表示體積的分辨率, L L L表示類別數量(包括空)。形式上,3D占據情況的預測可以被表述為:
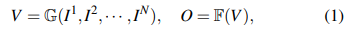
G \mathbb{G} G是一個神經網絡,從 N N N視圖圖像中提取3D體積特征 V ∈ R H × W × D × C V ∈ \mathbb{R}^{H×W×D×C} V∈RH×W×D×C,其中 C C C表示特征維度。 F F F負責將 V V V轉換為占據表示,先前的研究[7],[8]傾向于使用MLP實現每個體素的分類。考慮到所有現有方法都需要完整的3D占據標簽來監督體素級別的分類,我們設計了一個新的概念來實現 F \mathbb{F} F,并僅使用2D像素級標簽來監督 { G , F } \{\mathbb{G},\mathbb{F}\} {G,F}。
3. 整體框架
我們的整體框架如圖2所示。在第4節中,我們首先使用2D到3D網絡 G \mathbb{G} G從多視角RGB圖像中提取3D體積特征 V V V。需要注意的是,我們的框架對于 G \mathbb{G} G的實現不敏感,并且可以靈活地在各種BEV/Occupancy編碼器之間進行切換,比如[18],[19],[29]。接下來在第5節中,我們為每個體素預測體積密度 σ σ σ和語義logits S S S,以生成語義密度場(SDF)。隨后,我們從SDF進行體積渲染,并使用2D標簽優化網絡。最后在第6節中,我們闡述了用于解決自動駕駛場景中稀疏視角問題的體積渲染的輔助射線訓練策略。
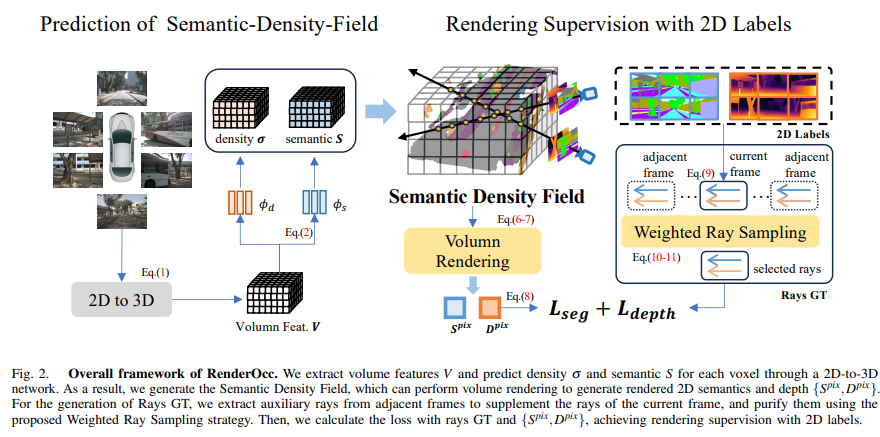
圖2. RenderOcc的整體框架。我們通過2D到3D網絡提取體積特征 V V V,并預測每個體素的密度 σ σ σ和語義 S S S。因此,我們生成了語義密度場,可以執行體積渲染以生成渲染的2D語義和深度 { S p i x , D p i x } \{S^{pix},D^{pix}\} {Spix,Dpix}。對于Rays GT的生成,我們從相鄰幀中提取輔助射線,以補充當前幀的射線,并使用提出的加權射線采樣策略對其進行凈化。然后,我們使用射線GT和 { S p i x , D p i x } \{S^{pix},D^{pix}\} {Spix,Dpix}計算損失,實現了使用2D標簽進行渲染監督。
4. 語義密度場
現有的3D占據方法從多視角圖像中提取體積特征 V V V,并進行體素級分類[29],[30],[9],[6]以生成3D語義占據。為了利用2D像素級監督,我們的RenderOcc創新地將 V V V轉換為一種稱為語義密度場(SDF)的多功能表示。給定一個體積特征圖 V ∈ R H × W × D × C V ∈ \mathbb{R}^{H×W×D×C} V∈RH×W×D×C,SDF通過兩種表示來編碼場景:體積密度 σ ∈ R H × W × D σ ∈ \mathbb{R}^{H×W×D} σ∈RH×W×D和語義logits S ∈ R H × W × D × L S ∈ \mathbb{R}^{H×W×D×L} S∈RH×W×D×L。具體來說,我們簡單地采用兩個MLP { φ d , φ s } \{φ_d,φ_s\} {φd?,φs?}來構建SDF,其公式為
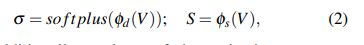
σ σ σ另外還使用softplus激活函數,以確保密度值不會變為負數。基于SDF,我們獲得了從任何視角進行語義渲染的能力,并在訓練過程中獲得了二維監督優化,這將在第5節部分進行解釋
優化后,SDF可以直接轉換為3D占據結果。我們使用 σ σ σ過濾出占據的體素,并根據 S S S確定它們的語義類別。該過程可以形式化如下:

τ τ τ作為 σ σ σ的閾值,用于確定一個體素是否被占據。
5. 利用2D標簽進行渲染監督
我們利用體積渲染來構建表面法線和2D像素之間的橋梁,從而通過2D標簽方便地進行監督。具體來說,我們利用相機的內參和外參參數從當前幀提取3D射線,其中每個2D像素對應于從相機發出的一條3D射線。每條射線 r r r攜帶著對應像素的語義和深度標簽 { S ^ p i x ( r ) , D ^ p i x ( r ) } \{\hat{S}^{pix}(r),\hat{D}^{pix}(r)\} {S^pix(r),D^pix(r)}。同時,我們基于SDF進行體積渲染[40],得到渲染的語義 S p i x ( r ) S^{pix}(r) Spix(r)和深度 D p i x ( r ) D^{pix}(r) Dpix(r),用于計算與2D標簽 { S ^ p i x ( r ) , D ^ p i x ( r ) } \{\hat{S}^{pix}(r),\hat{D}^{pix}(r)\} {S^pix(r),D^pix(r)}的損失。
為了渲染像素的語義和深度,我們在射線 r r r上預定義的范圍內對射線上的 K K K個點 { z k } k = 1 K \{z_k\}^K_{k=1} {zk?}k=1K?進行采樣。然后可以通過計算累積透射率 T T T和終止概率 α α α來得到點 z k z_k zk?的信息。
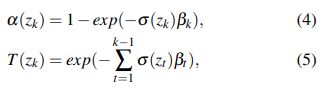
β k = z k + 1 ? z k β_k = z_{k+1} ? z_k βk?=zk+1??zk?是兩個相鄰點之間的距離。最后,我們使用 { z k } \{z_k\} {zk?}查詢SDF,并將它們累積起來,以獲得渲染的語義和深度。
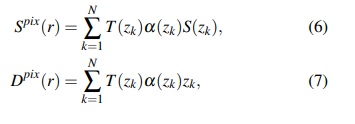
對于損失函數,交叉熵損失 L s e g L_{seg} Lseg?和SILog損失 L d e p t h L_{depth} Ldepth? [41] 被用來監督語義和深度。我們還引入了失真損失[35] 和TV損失[42] 作為SDF的正則化,稱為 L r e g L_{reg} Lreg?。因此,整體損失可以通過計算得到。

6. 輔助光線:增強多視角一致性
通過第III-D節中的2D渲染監督,模型可以從多視角一致性約束中受益,并學會考慮體素之間的空間遮擋關系。然而,在單幀中,周圍攝像機的視角覆蓋非常稀疏,它們的重疊范圍也有限。因此,大多數體素無法同時被具有顯著視角差異的多條光線采樣,這很容易導致局部最優解。因此,我們引入了來自相鄰幀的輔助光線,以補充多視角一致性約束,如圖3所示。
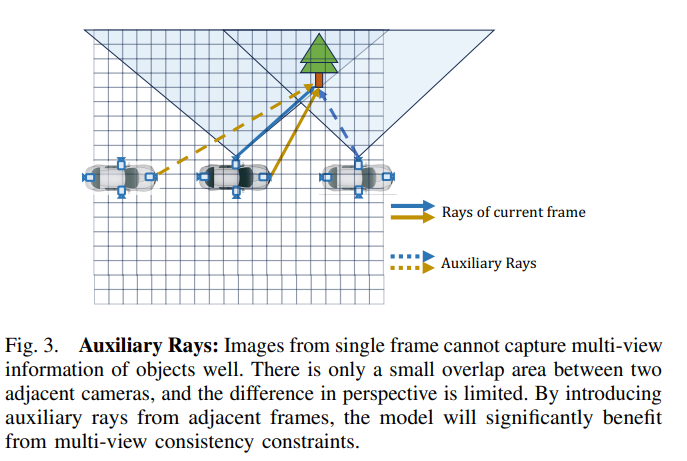
圖3. 輔助光線:單幀圖像無法很好地捕捉物體的多視角信息。相鄰攝像頭之間只有一個小的重疊區域,并且透視差異有限。通過引入相鄰幀的輔助光線,模型將顯著受益于多視角一致性約束。
6.1 輔助光線的生成
具體而言,對于當前幀索引為 t t t,我們選擇附近的 M a u x M_{aux} Maux?個相鄰幀。對于每個相鄰幀,我們分別生成光線,并將它們轉換到當前幀,以獲得最終的輔助光線 r a u x r_{aux} raux?:
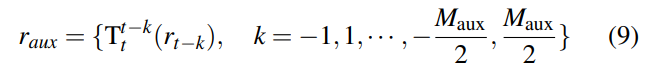
![[HADOOP]數據傾斜的避免和處理](http://pic.xiahunao.cn/[HADOOP]數據傾斜的避免和處理)




)


)










