官網:http://spark.apache.org
一、Spark是什么
Spark是一種快速、通用、可擴展的大數據分析引擎,2009年誕生于加州大學伯克利分校AMPLab,2010年開源,2013年6月成為Apache孵化項目,2014年2月成為Apache頂級項目。項目是用Scala進行編寫。
目前,Spark生態系統已經發展成為一個包含多個子項目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLib、SparkR等子項目,Spark是基于內存計算的大數據并行計算框架。除了擴展了廣泛使用的 MapReduce 計算模型,而且高效地支持更多計算模式,包括交互式查詢和流處理。Spark 適用于各種各樣原先需要多種不同的分布式平臺的場景,包括批處理、迭代算法、交互式查詢、流處理。通過在一個統一的框架下支持這些不同的計算,Spark 使我們可以簡單而低耗地把各種處理流程整合在一起。而這樣的組合,在實際的數據分析 過程中是很有意義的。不僅如此,Spark 的這種特性還大大減輕了原先需要對各種平臺分 別管理的負擔。
大一統的軟件棧,各個組件關系密切并且可以相互調用,這種設計有幾個好處:
1、軟件棧中所有的程序庫和高級組件 都可以從下層的改進中獲益。
2、運行整個軟件棧的代價變小了。不需要運 行 5 到 10 套獨立的軟件系統了,一個機構只需要運行一套軟件系統即可。系統的部署、維護、測試、支持等大大縮減。
3、能夠構建出無縫整合不同處理模型的應用。
二、Spark的內置項目
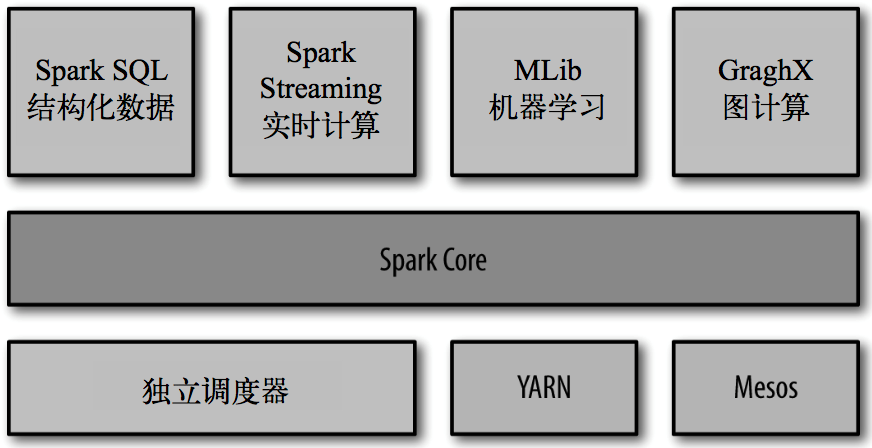
- Spark Core: 實現了 Spark 的基本功能,包含任務調度、內存管理、錯誤恢復、與存儲系統 交互等模塊。Spark Core 中還包含了對彈性分布式數據集(resilient distributed dataset,簡稱RDD)的 API 定義。
- Spark SQL: 是 Spark 用來操作結構化數據的程序包。通過 Spark SQL,我們可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)來查詢數據。Spark SQL 支持多種數據源,比 如 Hive 表、Parquet 以及 JSON 等。
- Spark Streaming: 是 Spark 提供的對實時數據進行流式計算的組件。提供了用來操作數據流的 API,并且與 Spark Core 中的 RDD API 高度對應。
- Spark MLlib: 提供常見的機器學習(ML)功能的程序庫。包括分類、回歸、聚類、協同過濾等,還提供了模型評估、數據 導入等額外的支持功能。
- 集群管理器: Spark 設計為可以高效地在一個計算節點到數千個計算節點之間伸縮計 算。為了實現這樣的要求,同時獲得最大靈活性,Spark 支持在各種集群管理器(cluster manager)上運行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自帶的一個簡易調度 器,叫作獨立調度器。
Spark得到了眾多大數據公司的支持,這些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、騰訊、京東、攜程、優酷土豆。當前百度的Spark已應用于鳳巢、大搜索、直達號、百度大數據等業務;阿里利用GraphX構建了大規模的圖計算和圖挖掘系統,實現了很多生產系統的推薦算法;騰訊Spark集群達到8000臺的規模,是當前已知的世界上最大的Spark集群。
三、Spark特點
-
快
與Hadoop的MapReduce相比,Spark基于內存的運算要快100倍以上,基于硬盤的運算也要快10倍以上。Spark實現了高效的DAG執行引擎,可以通過基于內存來高效處理數據流。計算的中間結果是存在于內存中的。 -
易用
Spark支持Java、Python和Scala的API,還支持超過80種高級算法,使用戶可以快速構建不同的應用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在這些shell中使用Spark集群來驗證解決問題的方法。 -
通用
Spark提供了統一的解決方案。Spark可以用于批處理、交互式查詢(Spark SQL)、實時流處理(Spark Streaming)、機器學習(Spark MLlib)和圖計算(GraphX)。這些不同類型的處理都可以在同一個應用中無縫使用。Spark統一的解決方案非常具有吸引力,畢竟任何公司都想用統一的平臺去處理遇到的問題,減少開發和維護的人力成本和部署平臺的物力成本。 -
兼容性
Spark可以非常方便地與其他的開源產品進行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作為它的資源管理和調度器,器,并且可以處理所有Hadoop支持的數據,包括HDFS、HBase和Cassandra等。這對于已經部署Hadoop集群的用戶特別重要,因為不需要做任何數據遷移就可以使用Spark的強大處理能力。Spark也可以不依賴于第三方的資源管理和調度器,它實現了Standalone作為其內置的資源管理和調度框架,這樣進一步降低了Spark的使用門檻,使得所有人都可以非常容易地部署和使用Spark。此外,Spark還提供了在EC2上部署Standalone的Spark集群的工具。
四、 Spark適用場景
我們大致把Spark的用例分為兩類:數據科學應用和數據處理應用。也就對應的有兩種人群:數據科學家和工程師。
1、數據科學任務
主要是數據分析領域,數據科學家要負責分析數據并建模,具備 SQL、統計、預測建模(機器學習)等方面的經驗,以及一定的使用 Python、 Matlab 或 R 語言進行編程的能力。
2、數據處理應用
工程師定義為使用 Spark 開發 生產環境中的數據處理應用的軟件開發者,通過對接Spark的API實現對處理的處理和轉換等任務。






JVM監控工具介紹)












