在并發編程中,我們通常會遇到以下三個問題:原子性問題,可見性問題,有序性問題。那么它們產生的原因和在Java中解決的辦法又是什么呢?
一、內存模型的相關概念
? 計算機在執行程序時,每條指令都是在CPU中執行的,而執行指令過程中,勢必涉及到數據的讀取和寫入。由于程序運行過程中的臨時數據是存放在主存(物理內存)當中的,這時就存在一個問題,由于CPU執行速度很快,而從內存讀取數據和向內存寫入數據的過程跟CPU執行指令的速度比起來要慢的多,因此如果任何時候對數據的操作都要通過和內存的交互來進行,會大大降低指令執行的速度。因此在CPU里面就有了高速緩存。
也就是,當程序在運行過程中,會將運算需要的數據從主存復制一份到CPU的高速緩存當中,那么CPU進行計算時就可以直接從它的高速緩存讀取數據和向其中寫入數據,當運算結束之后,再將高速緩存中的數據刷新到主存當中。
簡單的例子,比如下面的這段代碼:
i = i + 1;
當線程執行這個語句時,會先從主存當中讀取i的值,然后復制一份到高速緩存當中,然后CPU執行指令對i進行加1操作,然后將數據寫入高速緩存,最后將高速緩存中i最新的值刷新到主存當中。
這個代碼在單線程中運行是沒有任何問題的,但是在多線程中運行就會有問題了。在多核CPU中,每條線程可能運行于不同的CPU中,因此每個線程運行時有自己的高速緩存
比如同時有2個線程執行這段代碼,假如初始時i的值為0,那么我們希望兩個線程執行完之后i的值變為2。但是事實會是這樣嗎?
可能存在下面一種情況:初始時,兩個線程分別讀取i的值存入各自所在的CPU的高速緩存當中,然后線程1進行加1操作,然后把i的最新值1寫入到內存。此時線程2的高速緩存當中i的值還是0,進行加1操作之后,i的值為1,然后線程2把i的值寫入內存。
最終結果i的值是1,而不是2。
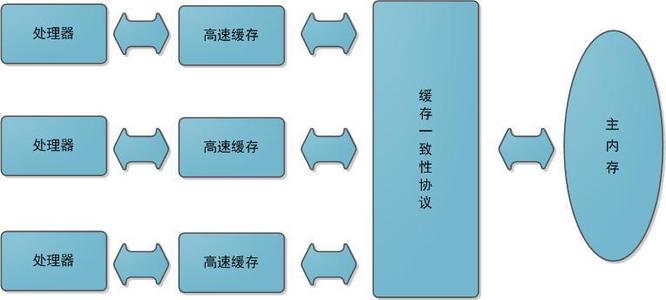
這就是著名的緩存一致性問題。通常稱這種被多個線程訪問的變量為共享變量。
為了解決緩存不一致性問題,通常來說有以下2種解決方法:
1)通過在總線加LOCK#鎖的方式
在早期的CPU當中,是通過在總線上加LOCK#鎖的形式來解決緩存不一致的問題。因為CPU和其他部件進行通信都是通過總線來進行的,如果對總線加LOCK#鎖的話,也就是說阻塞了其他CPU對其他部件訪問(如內存),從而使得只能有一個CPU能使用這個變量的內存。比如上面例子中如果一個線程在執行 i = i +1,如果在執行這段代碼的過程中,在總線上發出了LCOK#鎖的信號,那么只有等待這段代碼完全執行完畢之后,其他CPU才能從變量i所在的內存讀取變量,然后進行相應的操作。這樣就解決了緩存不一致的問題。
2)通過緩存一致性協議
加LOCK#鎖的方式會有一個問題,由于在鎖住總線期間,其他CPU無法訪問內存,導致效率低下。
所以就出現了緩存一致性協議。最出名的就是Intel 的MESI協議,MESI協議保證了每個緩存中使用的共享變量的副本是一致的。它核心的思想是:當CPU寫數據時,如果發現操作的變量是共享變量,即在其他CPU中也存在該變量的副本,會發出信號通知其他CPU將該變量的緩存行置為無效狀態,因此當其他CPU需要讀取這個變量時,發現自己緩存中緩存該變量的緩存行是無效的,那么它就會從內存重新讀取。
二、并發編程的三個概念存在的問題
1、 線程切換帶來的原子性問題:
Java中的一條語句,在翻譯為機器碼之后,可能對應的是多個指令。
比如:i++這個操作至少需要3條指令;
- 把 i 的值從內存=加載到寄存器;
- 執行+1操作;
- 把值寫入內存;
假如 i=0,兩個線程同時執行該操作,可能線程1執行完第一步,就切換到線程2執行,本來兩個線程各執行一次后 i 的值應該為 2 ,此時就出現 兩次遞增操作后值為 1 的現象;
2、緩存導致的可見性問題:
Java內存模型規定所有的變量存儲在主內存中。每個線程都有自己的工作內存,線程在工作內存中保存了使用到的主內存中變量的副本拷貝,線程對變量的操作必須在工作內存中進行,不能直接讀寫主內存中的變量。不同線程之間無法訪問對方工作內存的變量。線程之間共享變量值的傳遞均需要通過主內存來完成。
當線程1對共享變量A進行修改之后,線程2的工作內存中A可能還不是最新的值。這時候線程1的操作對線程2就不具有可見性。
3、編譯優化帶來的有序性問題:
為了充分利用處理器的性能,處理器會對輸入的代碼進行亂序執行。在計算之后將亂序執行的結果重組,并保證該結果和順序執行的結果一致,但是并不保證程序中各個語句的計算順序和輸入代碼的順序一致。Java虛擬機也有類似的指令重排序優化。
比如:Object obj = new Object(),
這條語句對應的指令為:
- 分配一塊內存M;
- 在M上初始化 Object 對象;
- 將M的地址賦值給 obj;
計算機經過優化后可能先執行第三步,再第二步,如果執行完第三步后切換到別的線程,若此時訪問該變量則會發生空指針異常;
三、Java內存模型
在前面談到了一些關于內存模型以及并發編程中可能會出現的一些問題。下面我們來看一下Java內存模型,研究一下 Java內存模型 為我們提供了哪些保證以及在java中提供了哪些方法和機制來讓我們在進行多線程編程時能夠保證程序執行的正確性。
在Java虛擬機規范中試圖定義一種Java內存模型(Java Memory Model,JMM)來屏蔽各個硬件平臺和操作系統的內存訪問差異,以實現讓Java程序在各種平臺下都能達到一致的內存訪問效果。那么Java內存模型規定了哪些東西呢,它定義了程序中變量的訪問規則,往大一點說是定義了程序執行的次序。
注意:為了獲得較好的執行性能,Java內存模型并沒有限制執行引擎使用處理器的寄存器或者高速緩存來提升指令執行速度,也沒有限制編譯器對指令進行重排序。也就是說,在java內存模型中,也會存在緩存一致性問題和指令重排序的問題。
Java內存模型規定所有的變量都是存在主存當中(類似于前面說的物理內存),每個線程都有自己的工作內存(類似于前面的高速緩存)。線程對變量的所有操作都必須在工作內存各自的緩存中中進行,而不能直接對主存進行操作。并且每個線程不能訪問其他線程的工作內存。
舉個簡單的例子:在java中,執行下面這個語句:
i = 10
執行線程必須先在自己的工作線程中對變量i所在的緩存行進行賦值操作,然后再寫入主存當中。而不是直接將數值10寫入主存當中。
那么Java語言本身對原子性、可見性以及有序性提供了哪些保證呢?
-
原子性:一個操作或者多個操作 要么全部執行并且執行的過程不會被任何因素打斷,要么就都不執行。
-
概念:多個線程訪問同一個變量時,一個線程修改了這個變量的值,其他線程能夠立即看得到修改的值。
-
概念:Java程序中,如果在本線程中觀察,所有的操作都是有序的;如果在另一個線程觀察,所有的操作都是無序的。前半句指的是線程內表現為串行的語義,后半句指的是指令重排序和主內存和工作內存同步延遲的問題。



















