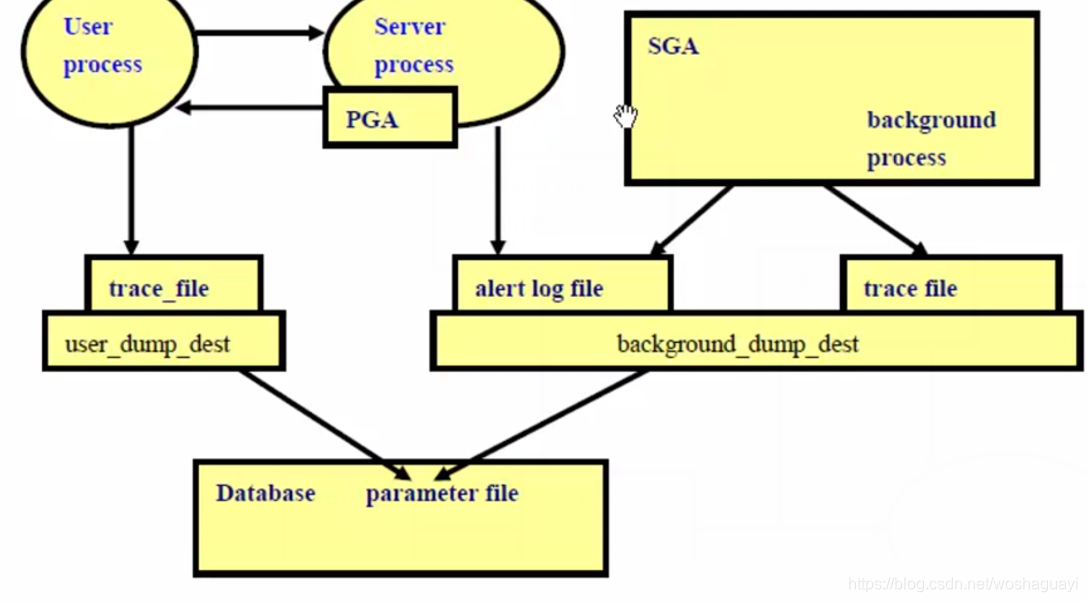
| 日志分類 | redo?log?files聯機日志或重做日志
archived?log?files歸檔日志??1184198alert?log?files??告警日志 ?trace?files??user_?_dump_?_dest??用戶信息日志如跟蹤會話日志
background?dump_?dest進程日志還有其他一-些不常用的日志 ? v$database的log_mode 數據庫歸檔模式
v$archived_log 控制文件中已經歸檔的日志文件信息
v$archive_dest 所有歸檔目標
v$archive_processes 已啟動的歸檔進程狀態
v$archive_redolog ???已經備份的歸檔日志信息 ??
? ? |
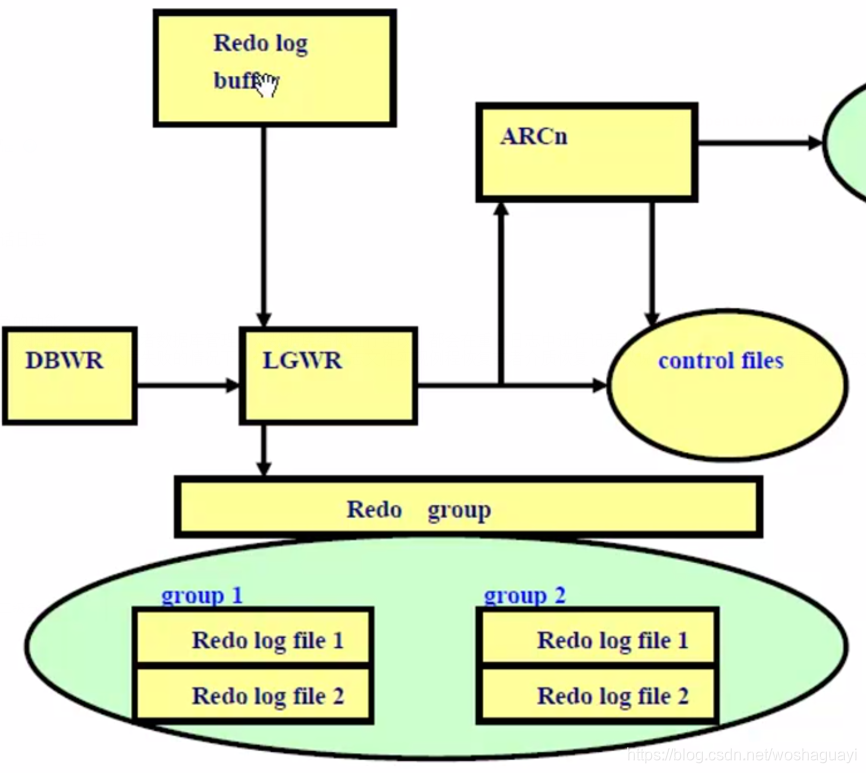  |
| redo log files?重做日志分為在線重做日志和歸檔重做日志。
? online Redo log files--在線重做日志,又稱聯機重做日志,指Oracle以SQL腳本的形式實時記錄數據庫的數據更新,換句話說,實時保 ? ? ? ? ? ? 存已執行的SQL腳本到在線日志文件中(按特定的格式)。
? Archive Redo log files--歸檔重做日志,簡稱歸檔日志,指當條件滿足時,Oracle將在線重做日志以文件形式保存到硬盤(持久化)。
? ? ? ? 重做日志文件是數據庫中一種非常重要的日志文件,也是其一一個很有特色的功能。
? ? ? ? 重做日志文件會記錄對于數據庫的任何操作,如利用DML語句或者DDL語句對數據進行更改,或者數據庫管理員對數據庫結構進行更改,都會在重做日志中進行記錄。
? ? ? ? 當數據被意外的刪除或者修改,我們可以利用重新日志文件進行恢復;當出現例程失敗或者介質失敗的情況下,也可以利用日志文件實現例程恢復或者介質恢復。所以說,我們若能夠管理好重做日志文件的話,對于保障數據 ? ? ? ? 庫數據的安全是非常重要的。 ? ? ? 聯機重做日志有以下特性:
? ? ? ? ? 1.記錄所有對數據的改變
? ? ? ? ? 2.提供恢復機制
? ? ? ? ? 3.能夠被分組 ? ? ? ? ? 4.至少需要兩個日志組 ?當前歸檔日志組寫滿后,Oracle會切換到下一日志組,繼續寫入,就這樣循環切換;當處于歸檔模式下,切換至原已寫滿的日志組,若該日志組歸檔完畢則覆蓋寫入,若沒有則只能使用日志緩沖區,等待歸檔完畢之后才能覆蓋寫入。當然,處于非歸檔模式下是直接覆蓋寫入的 ?Oracle提供了2個視圖用于維護在線重做日志:V$LOG 和? V$LOGFILE,我們可以通過這兩個視圖查看和修改在線日志 |
| 工作機制 | 1.聯機重做日志文件是循環使用的.
2.當一個聯機重做日志文件被寫滿了,LGWR將移到下個聯機重做日志文件組.被稱為日志切換,同時發生檢查點,信息將被寫入控制文件
3.redo?log是二進制文件
4.日志文件的組織模式是組組下是成員至少兩個組
5.組和組是平等的關系
6.實例同-?-時刻只能向-一個組寫日志
7.-個組寫滿了,寫下一個組,這個過程叫WiTCH自動切換和手工切換
8.日志切換產生checkpoint有增量檢測和完全檢測兩種
9.完全檢測:一致性?SHUTDOWN時;alter?system?checkpoint, 結果為:所有的臟數據塊寫入文件,改寫文件頭的信息
參數log._?checkpoints_to_alert=true?決定檢測點的信息寫入報警日志,如果將日志文件轉出到DUMP中 select?*?from?v$log;
select to_char(first_time, 'yyyy-mm-dd') day2 ?from v$log_history?group?by?day2,
alter?session?set?events?'immediate?trace?name?redohdr?level?n';增加|減少日志組的成員,
select to_number('fffffffffff','xxxxxxxxxxxxxxxxxx')from dual; |
| Redo寫的觸發條件: | 1,每三秒鐘超時(timeout):
當LGWR處于空閑狀態時,它依賴于rdbms?rpc?message等待事件,處于休眠狀態,直到三秒時間到,如果這個時候LGWRf發現有Redo信息需要寫出的話,那么LGWR將執行寫的操作,log?file?parallel?write等待事件將會出現。
2.閥值的達到:
Redo?log?buffer?1/3滿;
Redo?log?buffer擁有1MB的臟數據; 參數_?log?_io _size的設置很重要,一般為?log_buffer?的1/3大小
3.用戶提交:
當一個transaction?提交的時候,在Redo?stream?中將記錄一-個?提交標志。在這些Redo被寫到磁盤上之前,這個transaction是不能恢復的。所以,在transaction返回成功標志之前,必須等待LGWR寫的完成。進程通知LGWR寫,并且以log?file?sync事件開始休眠。超時為1秒
4.在DBWn寫之前:
如果DBWR將要寫出的數據的高RBA超過LGWR的on-diskRBA,則DBWR將通知LGWR執行寫的操作,在Oracle8i之前,此時DBWR將等待Log?file?sync事件。從Oracle8i開始,DBWR把這些block(將要寫出的block,這種block的高RBA超過了LGWR的on-diskRBA)放入defer隊列中,同時通知LGVR執行Redo寫出。
注:
logbufferspace等待事件說明logbuffer空間不夠用了。 |
| redo日志文件管理 | ?規劃原則:分散放開到不同的硬盤,日志所在盤的IO要足夠,IO讀寫都要快增加減少日志成員或組日志狀態與監視處理日志異常[日志不一-致,日志丟失,日志損壞]
?增加減少日志成員或組:
alter?database?add?logfle?group?<?member(<dir>' <dir>)?size?<?;alter?database?add?logfile?member?dir'?to?group?<?D;alter?database?drop?logfile?‘dir';
alter?database?drop?logfile?group? |
| redo日志文件的狀態 | UNUSED:表示從未對聯機重做日志文件組進行寫入。這是剛添加的聯機重做日志文件的狀態 |
| CURRENT:表示當前的聯機重做日志文件組。這說明該聯機重做日志文件組是活動的 |
| ACTIVE:表示聯機重做日志文件組是活動的,但是并非當前聯機重做日志文件組。崩潰恢復需要該狀態。它可用于塊恢復。它可能已歸檔,也可能未歸檔 |
| CLEARING:表示在執行ALTER?DATABASE?CLEAR?LOGFILE命令后正在將該日志重建為一個空日志。日志清除后,其狀態更改為 |
| ?CLEARING_?CURRENT:表示正在清除當前日志文件中的已關閉線程。如果切換時發生某些故障,如寫入新日志標頭時發生了輸入/輸出(I/O)?錯誤,則日志可能處于此狀態。 |
| ?INACTIVE:表示例程恢復不再需要聯機重做文件日志組。它可能已歸檔,也可能未歸檔。
注:處于active的日志文件組無法刪除,因為這個日志文件組可能會在實例恢復的時候使用。
我們可以使用alter database checkpoint命令手動的創建一個檢查點,來是active的日志文件組變成inactive的日志文件組,這一點在擴容日志文件組(先刪除再添加)的時候會用到!
可以使用alter system switch logfile命令手動的切換日志文件組
另外在說一下active和inactive的一些區別,其實這兩種狀態的重做日志都是已經歸檔的,不同的只是,active狀態的重做日志文件組是在實例恢復的時候被需要的,因為有一些事務雖然已經提交了,但是這些記錄的更改還沒有寫到datafile中,如果這個時候實例一旦失敗(斷電或者其他的突發情況),在進行實例恢復的時候會需要這些active狀態的日志文件組,每過一段時間,當系統負載不是很大的時候,Oracle會嘗試將內存中的數據寫入到datafile中,這個時候active的日志文件組就會變成inactive狀態,我們可以使用alter database checkpoint強制來執行這個過程;而inactive是在實例恢復的時候不被需要的日志文件組。 |
| V$logfile的status | INVALID:表明該文件不可訪問STALE:表示文件內容不完全 stale表示文件內容不完全 deleted表示文件已經不再使用 空白表示文件在使用中 |
| ? | 要確定一個數據庫例程的聯機重做日志文件的合適數量,您必須測試不同的配置。在某些情況下,數據庫例程可能只需要兩個組。在其它情況下,數據庫例程可能需要更多的組以保證各個組始終可供LGWR使用。例如,如果LGWR跟蹤文件或警報文件中的消息表明LGWR經常不得不因為檢查點操作尚未完成或者組尚未歸檔而等待,您就需要添加組。
??????盡管Oracle服務器允許多元備份的組可以包含不同數量的成員,但應該盡量建立對稱配置。不對稱配置應只是非常情況(?如磁盤故障)的臨時結果。
??????聯機重做日志文件的位置:?.
??????對聯機重做日志文件進行多元備份時,請將組內的成員放置在不同磁盤上。這樣,即使一個成員不可用而其它成員可用,該例程也不會關閉。將歸檔日志文件和聯機重做日志文件分放在不同磁盤上,以減少ARCn和LGWR后臺進程之間的爭用。
??????數據文件和聯機重做日志文件應當放置在不同的磁盤上以減少LGWR和DBWn的爭用,并降低發生介質故障時同時丟失數據文件和聯機重做日志文件的風險。
??????調整聯機重做日彎文件的大小:
??????聯機重做日志文件最小為50?KB,最大文件大小視操作系統而定。不同組的成員可以有不同的大小:但是,大小不同的組不會帶來任何好處。
??????只有當需要更改聯機重做日志組的成員大小時,才需要大小不同的組作為臨時結果。在,?有不同的大小:但是,大小不同的組不會帶來任何好處 |
| ? | -添加新的重做日志文件組,group 4 可以缺省,大小最好10M到50M之間
select * from v$logfile;
alter database add logfile group 4
'F:\APP\HANLIN\ORADATA\ORCL\REDO04.LOG' size 20M;
多個成員
alter database add logfile group 6
('F:\APP\HANLIN\ORADATA\ORCL\REDO06_A.LOG',
'F:\APP\HANLIN\ORADATA\ORCL\REDO06_B.LOG')size 20M;
————————————————
下面語句只修改數據字典和控制文件,不刪除實際文件
alter database drop logfile group 4;
下面語句清空重做日志文件
alter database clear logfile group 4;alter database add logfile member
'F:\APP\HANLIN\ORADATA\ORCL\REDO04_B.LOG' to group 4;
刪除日志成員(只修改數據字典和控制文件,不刪除實際文件)
alter database drop logfile member
'F:\APP\HANLIN\ORADATA\ORCL\REDO04_B.LOG'
更改重做日志文件的位置或名稱的步驟:
shutdown;
復制日志文件,修改日志文件名稱
startup mount;
--舉例兩個成員的路徑和名稱修改
alter database rename file
'成員1j舊路徑\新文件名','成員2舊路徑\新文件名'
to
''成員1新路徑\新文件名,'成員2新路徑\新文件名';
alter database open;
? |
| ? | alter?system?set?1og_?archive_?dest_?2?=’SERVICE=standby1'?;alter?system?set?1og_?_archive_?format?=’arch_?_%t_?_%s_?_%r.?arc'?;
co1?dest_?name?format?a20;col?destination?format?a30;
select?dest_?_name,?status,?archiver,?destination,?1og_?_sequence,?reopen_?_secs,?transmit_?_mode,?processfrom?vSarchive_?dest;
selectname,?sequence#,?registrar,?standby_?dest,?archived,?status?from?v$archived_?1og;
v$archived_?1ogvSarchive_?destv$1og_?historyv$database
vSarchive_?processes
??????-->從控制文件中獲得歸檔的相關信息-->歸檔路徑及狀態
??????-->控制文件中日志的歷史信息-->查看數據庫是否處于歸檔狀態-->歸檔相關的后臺進程信息
select?*?from?v$logfile;
select?member,?bytes/1024/1024?from?v$1og?a,?v$logfile?bwhere?a.?group#=b.?group#
select?NAME,?STATUS?from?v$archived_?1og; 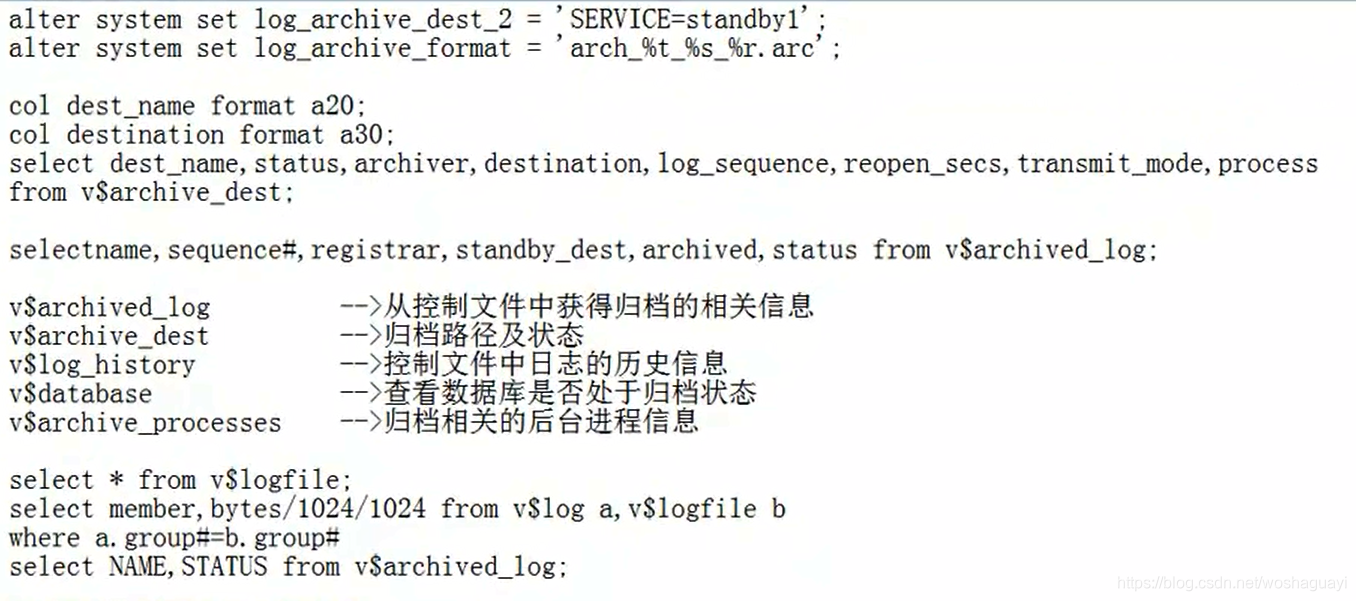
|
| ? | Log?buffer大小設置
??????9i以前,-?-般是3M
??????在10g中ORACLE會自動調整它的值,他遵循這樣一個原則,’Fixed?SGA?Size'?+’Redo?Buffers'?是granule?size的整數倍;select?*?from?vSsgainfo?where.?name?in?('?Fixed?SGA?Size'?,’Redo?Buffers'?,’Granule?Size’?)?;--在10.2.0.3中Log?Buffer?默認值是14M,在10.2.0.?4中,默認值是15Mselect?*?from?vSversion?where?rownum<2;8、LGWR觸發條件:Write-?Ahead-Log:?日志寫入優先
??????1.用戶提交
??????2.有1/3重做日志緩沖區未被寫入磁盤
??????3.有大于1M的重做日志緩沖區未被寫入磁盤4.每隔3秒鐘
??????5.?DBWR需要寫入的數據的SCN大于LGWR記錄的SCN,DBWR觸?發LGWR寫入9、L0G優化建議
??????在OLTP?系統上,REDO?LOG文件的寫操作主要是小型的,比較頻繁,一般的寫大小在幾K,而每秒鐘產生的寫I0次數會達到幾十次,數百次甚至_上千次。因此REDO?LOG文件適合存放于IOPS?較高的轉速較快的磁盤上,I0PS僅能達到數百次的SATA盤不適合存放REDO?LOG文件。另外由于REDO?LOG文件的寫入是串行的,因此對于REDO?LOG文件所做的底層條帶化處理,對于REDO?LOG寫性能的提升是十分有限的。10、REDO?LOG切換的時間應該盡可能的不低于10-20分鐘
select?to_?char?(FIRST?_TIME,’?yyy-mm-dd?hh24:mi:ss'?)?f.?_time,?SEQUENCE#?from?vS1og_?history11、日志相關的一-些操作
alter?database?add?logfile?group?5_?’/opt/?orac1e/?oradata/?dbtest/redo05_?1.?1og’?SIZE?10Malter?database?add?1ogfile?member'?/?opt/?oracle/?oradata/?dbtest/redo04_?3.?1og’to?group?4alter?database?drop?logfile?group?5
alter?database?drop?logfile?('?/opt/oracle/?oradata/?dbtest/redo05_?1.?1og'?,’/opt/?oracle/?oradata/?dbtest/redo05_?2.?1og'?)\\ ? 
|



















