本篇內容包括:數據庫瓶頸、分庫分表以及分庫分表相關問題
一、數據庫瓶頸
不管是IO瓶頸,還是CPU瓶頸,最終都會導致數據庫的活躍連接數增加,進而逼近甚至達到數據庫可承載活躍連接數的閾值。在業務Service來看就是,可用數據庫連接少甚至無連接可用。接下來就可以想象了吧(并發量、吞吐量、崩潰)。
1、IO瓶頸
第一種:磁盤讀IO瓶頸,熱點數據太多,數據庫緩存放不下,每次查詢時會產生大量的IO,降低查詢速度 -> 分庫和垂直分表。
第二種:網絡IO瓶頸,請求的數據太多,網絡帶寬不夠 -> 分庫。
2、CPU瓶頸
第一種:SQL問題,如SQL中包含 join,group by,order by,非索引字段條件查詢等,增加 CPU 運算的操作 -> SQL優化,建立合適的索引,在業務 Service 層進行業務計算。
第二種:單表數據量太大,查詢時掃描的行太多,SQL效率低,CPU率先出現瓶頸 -> 水平分表
二、分庫分表
1、水平分庫
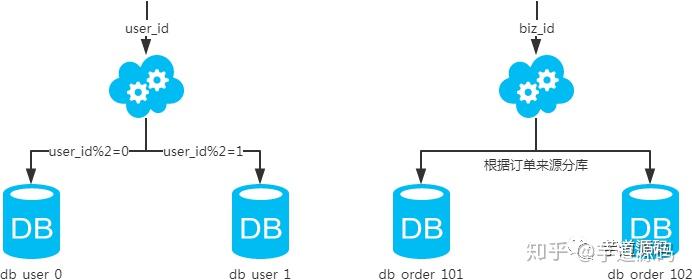
- 概念:以字段為依據,按照一定策略(hash、range等),將一個庫中的數據拆分到多個庫中。
- 結果:
- 每個庫的結構都一樣;
- 每個庫的數據都不一樣,沒有交集;
- 所有庫的并集是全量數據;
場景:系統絕對并發量上來了,分表難以根本上解決問題,并且還沒有明顯的業務歸屬來垂直分庫。
分析:庫多了,io和cpu的壓力自然可以成倍緩解。
2、水平分表
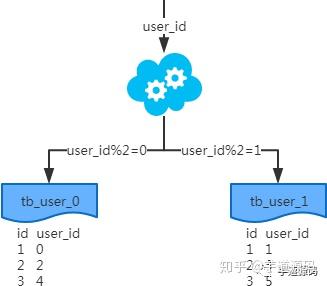
- 概念:以字段為依據,按照一定策略(hash、range等),將一個表中的數據拆分到多個表中。
- 結果:
- 每個表的結構都一樣;
- 每個表的數據都不一樣,沒有交集;
- 所有表的并集是全量數據;
場景:系統絕對并發量并沒有上來,只是單表的數據量太多,影響了SQL效率,加重了CPU負擔,以至于成為瓶頸。
分析:表的數據量少了,單次SQL執行效率高,自然減輕了CPU的負擔。
3、垂直分庫

- 概念:以表為依據,按照業務歸屬不同,將不同的表拆分到不同的庫中。
- 結果:
- 每個庫的結構都不一樣;
- 每個庫的數據也不一樣,沒有交集;
- 所有庫的并集是全量數據;
場景:系統絕對并發量上來了,并且可以抽象出單獨的業務模塊。
分析:到這一步,基本上就可以服務化了。例如,隨著業務的發展一些公用的配置表、字典表等越來越多,這時可以將這些表拆到單獨的庫中,甚至可以服務化。再有,隨著業務的發展孵化出了一套業務模式,這時可以將相關的表拆到單獨的庫中,甚至可以服務化。
4、垂直分表
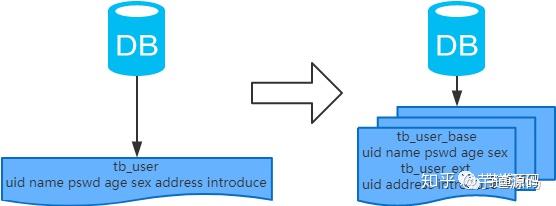
- 概念:以字段為依據,按照字段的活躍性,將表中字段拆到不同的表(主表和擴展表)中。
- 結果:
- 每個表的結構都不一樣;
- 每個表的數據也不一樣,一般來說,每個表的字段至少有一列交集,一般是主鍵,用于關聯數據;
- 所有表的并集是全量數據;
場景:系統絕對并發量并沒有上來,表的記錄并不多,但是字段多,并且熱點數據和非熱點數據在一起,單行數據所需的存儲空間較大。以至于數據庫緩存的數據行減少,查詢時會去讀磁盤數據產生大量的隨機讀IO,產生IO瓶頸。
分析:可以用列表頁和詳情頁來幫助理解。垂直分表的拆分原則是將熱點數據(可能會冗余經常一起查詢的數據)放在一起作為主表,非熱點數據放在一起作為擴展表。這樣更多的熱點數據就能被緩存下來,進而減少了隨機讀IO。拆了之后,要想獲得全部數據就需要關聯兩個表來取數據。但記住,千萬別用join,因為join不僅會增加CPU負擔并且會講兩個表耦合在一起(必須在一個數據庫實例上)。關聯數據,應該在業務Service層做文章,分別獲取主表和擴展表數據然后用關聯字段關聯得到全部數據。
三、分庫分表相關問題
1、分表后的ID怎么保證唯一性的呢?
因為我們主鍵默認都是自增的,那么分表之后的主鍵在不同表就肯定會有沖突了。有幾個辦法考慮:
- 設定步長,比如1-1024張表我們分別設定1-1024的基礎步長,這樣主鍵落到不同的表就不會沖突了。
- 分布式ID,自己實現一套分布式ID生成算法或者使用開源的比如雪花算法這種
- 分表后不使用主鍵作為查詢依據,而是每張表單獨新增一個字段作為唯一主鍵使用,比如訂單表訂單號是唯一的,不管最終落在哪張表都基于訂單號作為查詢依據,更新也一樣。
2、分表后非sharding_key的查詢怎么處理呢?
- 可以做一個mapping表,比如這時候商家要查詢訂單列表怎么辦呢?不帶user_id查詢的話你總不能掃全表吧?所以我們可以做一個映射關系表,保存商家和用戶的關系,查詢的時候先通過商家查詢到用戶列表,再通過user_id去查詢。
- 打寬表,一般而言,商戶端對數據實時性要求并不是很高,比如查詢訂單列表,可以把訂單表同步到離線(實時)數倉,再基于數倉去做成一張寬表,再基于其他如es提供查詢服務。
- 數據量不是很大的話,比如后臺的一些查詢之類的,也可以通過多線程掃表,然后再聚合結果的方式來做。或者異步的形式也是可以的。



















