? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?sga | |||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||
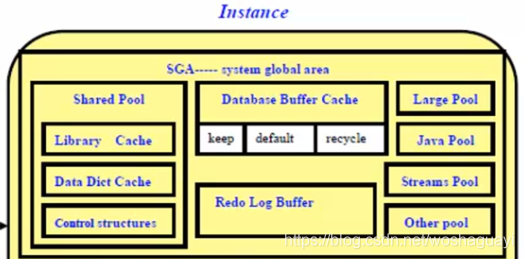
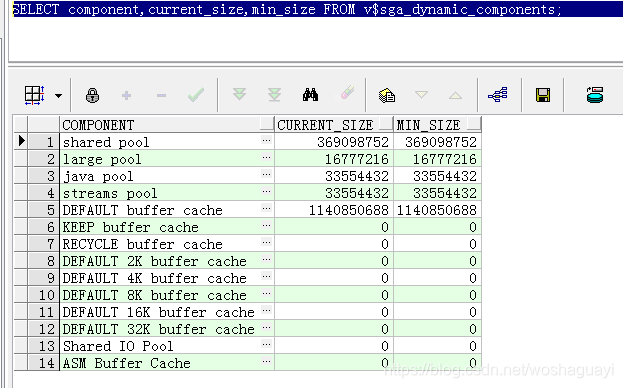
| SGA的管理 | ■有三種方式: ? ? ? ? ? ●8i:SGA的總大小由所有內存組件大小之和決定,不能直接定義SCA大小。對內部組件大小的修改必須在數據庫重起? ? ? ? ? ? ? ? ? ? 后?才能生為,所以叫做SGA的靜態管理。 ? ? ? ? ? ●9i:?SGA總大小由初始化參數SGA_?MAX?SIZE確定,各個內存組件大小之和不能超過這個參數。在這個大小之下,? ? ? ? ? ? ? ? ? ? ? SGA?各個內存組件可以在不重起數據庫的情況下直接修改大小,所以叫做SGA的動態管理。 ? ? ? ? ? ●10g:??SGA大小既可以像9i一樣動態管理,也可以實施SGA的自動管理,只需要設置初始化參數SGA_?TARGET,?SGA? ? ? ? ? ? ? ? ? ? ? ?各個內存組件??三就可以由數據庫自動設置大小,設置的依據來源于系統自動收集的統計信息 ? ?■在9i以后,SGA的內部組件大小可以動態調整,也可以由數據庫自動管理,在設置內存大小的時候,分配的基本單位是粒? ? ? ? ? ? 度(granule)。Granule是一段連續的虛擬內存,大小取決于SGA?_MAX?SIZE的大小 ? ? ? ? ? ?●如果SGA_?MAX?_SIZE小于128M,?Granule為4M,?否則Granule為16M ? ? ? ? ? ?●各個內存組件分配大小必須是Granule的整倍數 ? ? ? ? ? ?●整個SGA最小不小于3個Granule大小 ■9i中的規則如下: ? ? ? ?●linux/unix ? ? ? ? ? ? ?SGA?>128M?granule?16M? ? ? ? ? ●Windows ? ? ? ? ? ? SGA?>128M?granule?8M ■10g中的分配規則為 ? ? ? ? ●?linuxunix ? ? ? ? ●Windows | ||||||||||||||||||||||||||||||
| shared pool | ■用于存儲: ? ?◆最近執行的SQL 語句 ? ?◆最近使用的數據定義 ? ?◆庫緩存 | ||||||||||||||||||||||||||||||
| 庫緩存 | ■存儲最近使用的SQL和PL/SQL語句的信息 ■共享最常用的語句 ■管理上遵循LRU規則 ■包括兩個部分: ? ?◆共享PLSQL區 | ||||||||||||||||||||||||||||||
| 數據字典緩存 | ■存儲在數據庫中最近使用的定義 ■包括數據文件,表,索引,列,用戶,權限和其他的數據庫對象 ■在分析階段,服務器進程查找數據字典去驗證對象的名字以及是否是合法訪問 ■對于查詢和DML語句,如果數據字典的信息在緩存中能夠提高響應時間大小由Shared Pool的大小決定 | ||||||||||||||||||||||||||||||
| SGA中關鍵的內存片段。特別是性能與擴展上。 ■如果以前執行過,則按照以前執行的計劃執行,通常是軟分析[soft parse|或快速軟分析 ? ? ◆通過PCA提交Sql語句>parse語句>soft parse->執行語句- >通過PCA輸出 ■如果沒執行過,oracle 開始分析語句的語法,語義,按照優化器規則獲得最佳執行計劃,并在內存中保存這個語句與之對應 ? ?的執行計劃等相關信息,便于下次快速調用。 ? ?◆通過PGA提交Sql語句parse語句hard parse→分析與得到優化方案[CBOor RB0|→根據優化方案制定執行計劃》執行語句 ? ?◆一-通過PGA輸出 | |||||||||||||||||||||||||||||||
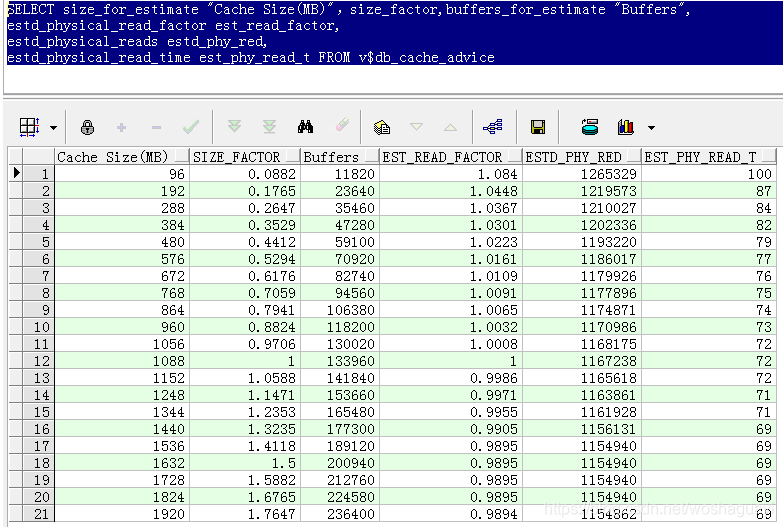
| 數據高速緩存區 | ■暫存從數據文件中獲得的數據塊的數據映像 ■同樣遵循LRU算法管理內存 ? ? ◆DB RECYCLE CACHE SIZE ■只有defualt池可以被sga自動管理
? ? | ||||||||||||||||||||||||||||||
| 重做日志緩沖區 | ■暫存數據庫中所有數據塊的改變 ■內存管理方法是FIFO ■重做日志被用于提供數據恢復功能 ■暫存重做日志的目的是為了提高語句的執行速度 ■大小由參數LOG_ BUFFER決定,但這個內存區不能動態調整大小 | ||||||||||||||||||||||||||||||
| 大池 | ■大池是系統全局區中可選的一個內存區 | ||||||||||||||||||||||||||||||
| java池 | ■是系統全局區中一個可選內存區。 ■用于Java程序的解析 和執行 | ||||||||||||||||||||||||||||||
| ? | ? | ? | |||||||||||||||||||||||||||||
| ? | ? | ? | |||||||||||||||||||||||||||||
 ? ?
? ?




?



















