Knowledge Distil 相關文章
- 1.FitNets : Hints For Thin Deep Nets (ICLR2015)
- 2.A Gift from Knowledge Distillation:Fast Optimization, Network Minimization and Transfer Learning (CVPR 2017)
- 3.Matching Guided Distillation(ECCV2020)
- 4.A Comprehensive Overhaul of Feature Distillation(ICCV2019)
- 5.Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons (AAAI2019)
- 6.Compressing GANs using Knowledge Distillation
- 7.GhostNet: More Feature from Cheap Operation(CVPR2020)
- 8.Data-Free Adversarial Distillation
- 9.Data-Free Learning of Student Networks (ICCV2020)
1.FitNets : Hints For Thin Deep Nets (ICLR2015)
論文目的:
蒸餾訓練中,為了訓練更加深的網絡,在某個層中設置hint(暗示),再與老師網絡中的hint對比。 這樣做是使訓練更加快,好。
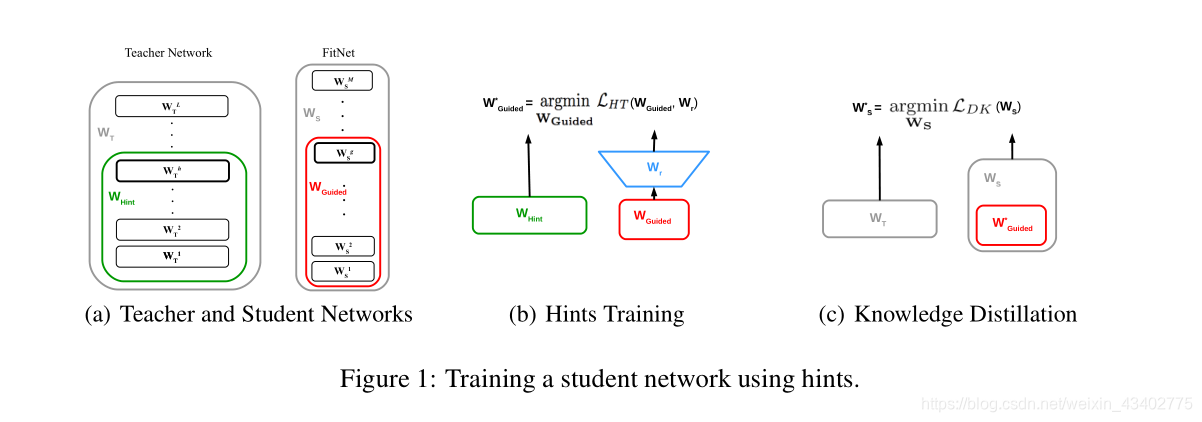

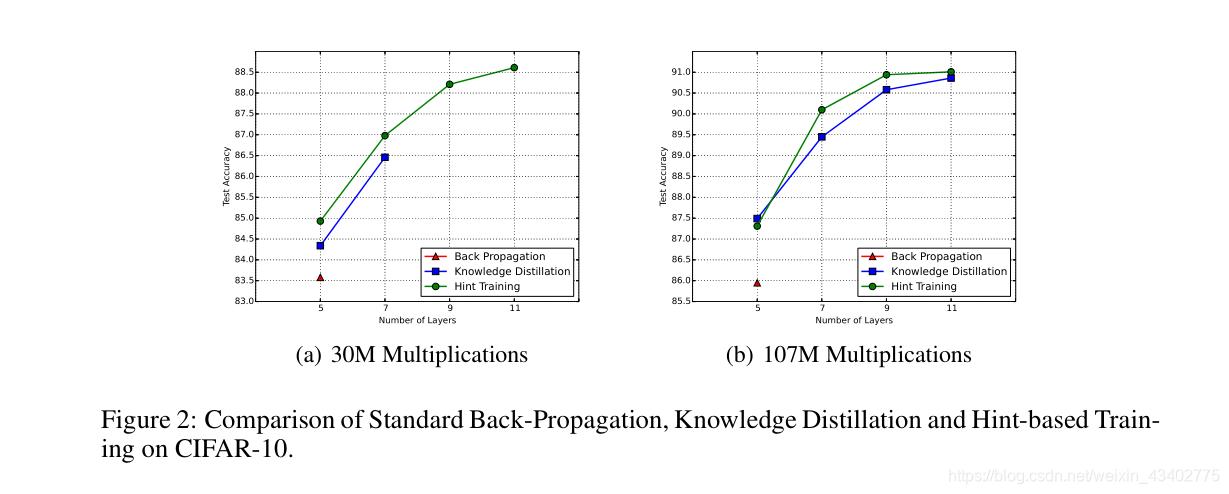
實驗:
分別在 CIFAR-10 和 CIFAR-100 SVHN MNIST AFLW進行了實驗
2.A Gift from Knowledge Distillation:Fast Optimization, Network Minimization and Transfer Learning (CVPR 2017)
論文鏈接
論文目的:
發現蒸餾可以用來
- 對模型快速訓練, 訓練更少的時間就能達到效果。
- 對模型進行初始化,
- 對模型進行轉移學習(老師網絡用于貓狗分類,學生網絡用于馬和斑馬分類)
主要貢獻:
1.提出了一蒸餾訓練方法,認為教學生網絡不同層輸出的feature之間的關系比教學生網絡結果好
The student DNN does not necessarily have to learn the intermediate output when the specific question is input but can learn the solution method when a specific type of question is encountered
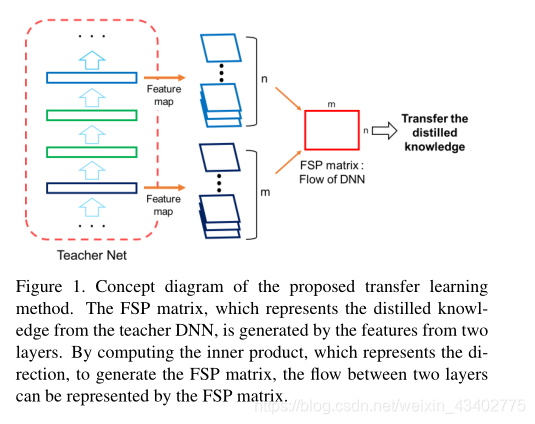
論文內容:
1.定義了FSP matrix矩陣 來表明兩個層之間的關系流
The FSP matrix is generated by the features from two layers

網絡模型
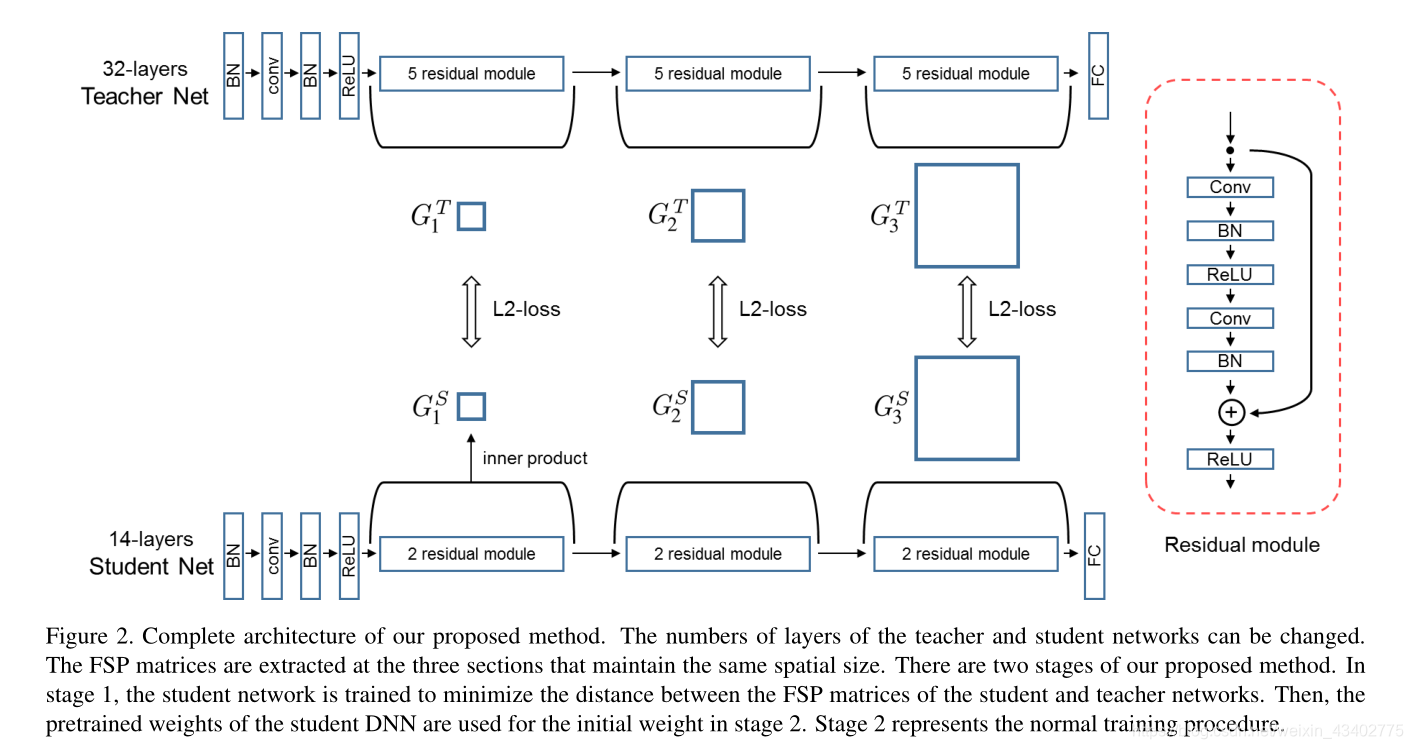

2.訓練過程
先訓練FSPloss ,然后再用數據集訓練學生網絡進行微調。
3.Matching Guided Distillation(ECCV2020)
論文鏈接
論文目的:
提出了一種新方法用于解決老師網絡和學生網絡輸出feature維度不一致問題,進而導致對比的時候有一定誤差。其中,其他老的方法是新增一個卷積,或者attention 去匹配維度。
本文提出三個方法去裁剪老師網絡生成的feature通道數,進而與學生網絡進行匹配,不需要增加一個橋梁(1*1卷積)去解決features不匹配的情況。
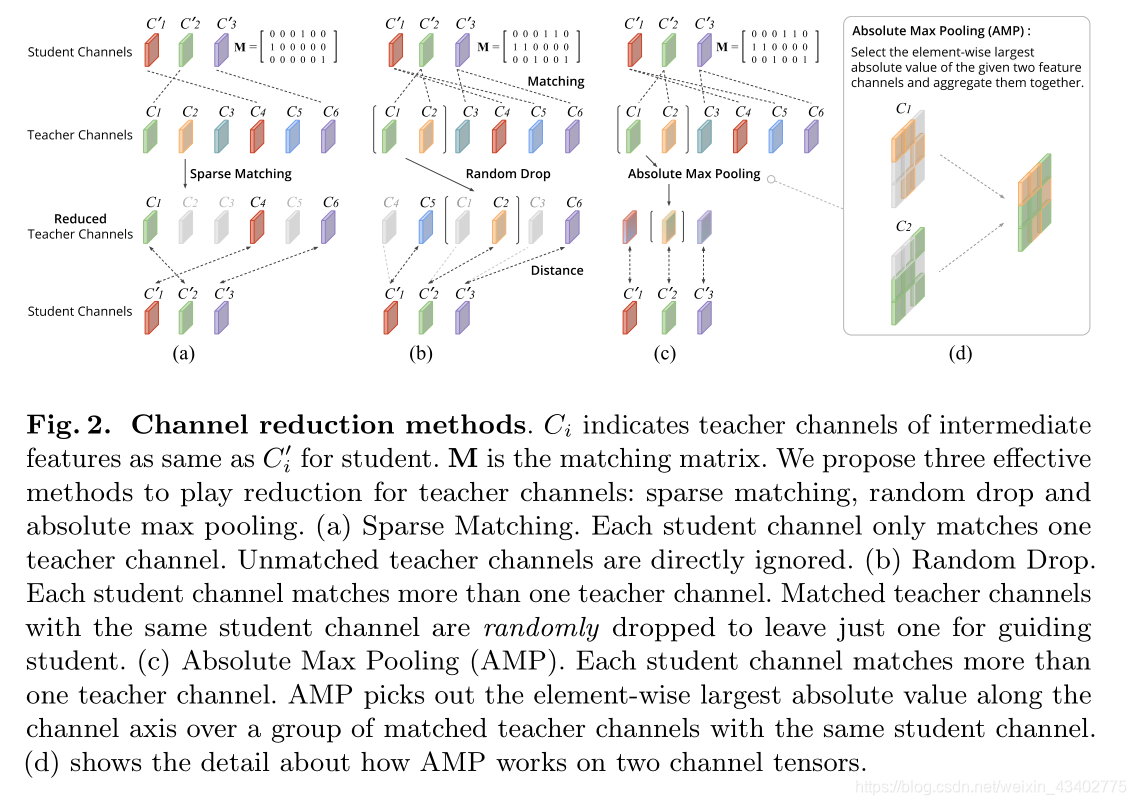
論文內容:
1.通道匹配
尋找一個矩陣M建立S和T特征的聯系,
其中S是預訓練學生網絡輸出的feature
T是預訓練老師網絡輸出的feature
S=MTS = MT S=MT
S∈RS×N,M∈RS×C,T∈RC×NS\in \mathcal{R}^{S \times N},M\in \mathcal{R}^{S \times C},T\in \mathcal{R}^{C\times N}S∈RS×N,M∈RS×C,T∈RC×N
M 還要滿足以下條件

2.通道裁剪
找到M之后進行裁剪,裁剪分為三個方法。
(1)sparse matching

(2)random drop
(3) max pooling
論文不足 :使用的預訓練的student模型,然后再利用teacher微調。其中M是兩者的相關程度,可以直接對teacher生成的feature進行運算,找到有代表性的。
4.A Comprehensive Overhaul of Feature Distillation(ICCV2019)
論文鏈接
論文目的:
設計一種蒸餾方法,對teacher transform, student transform, distillation feature position and distance function 進行了設計
論文內容:
teacher transform 加了a new ReLU activation
student transform 加了1*1conv
distillation feature position 在pre-RELU
distance function 提出了新的 partial L2 distance
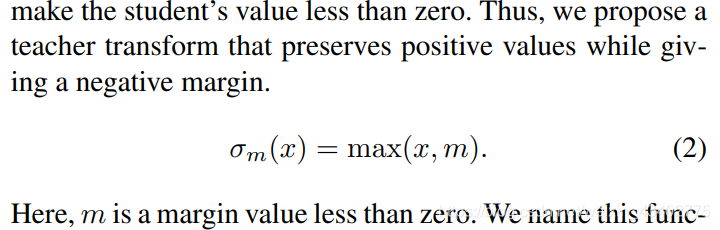
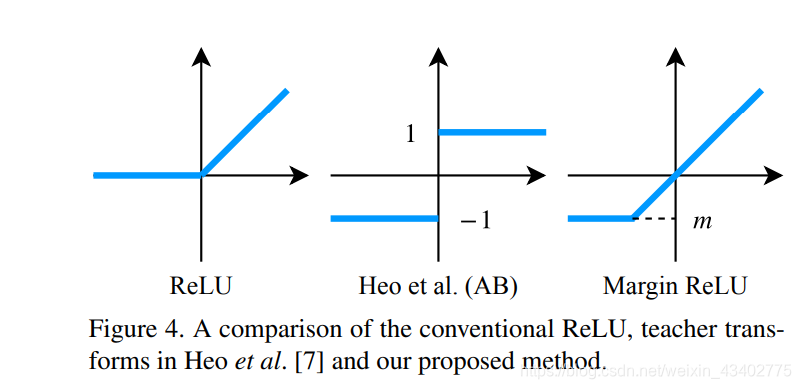
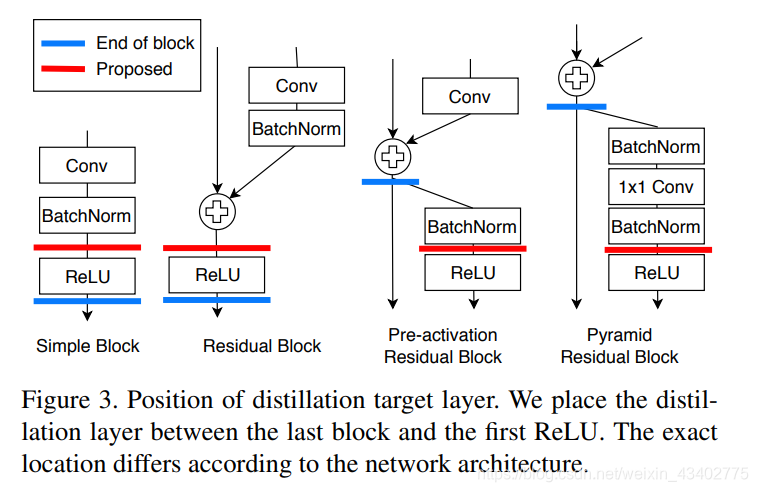

5.Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons (AAAI2019)
提供了一個新思路:讓老師網絡層的神經元的激活平面盡量和學生網絡的一樣
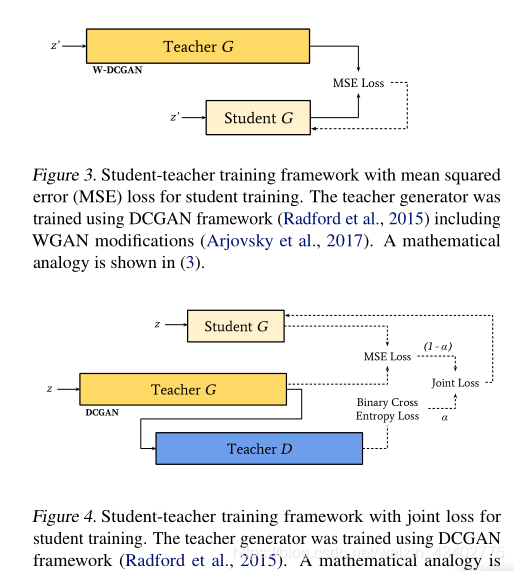
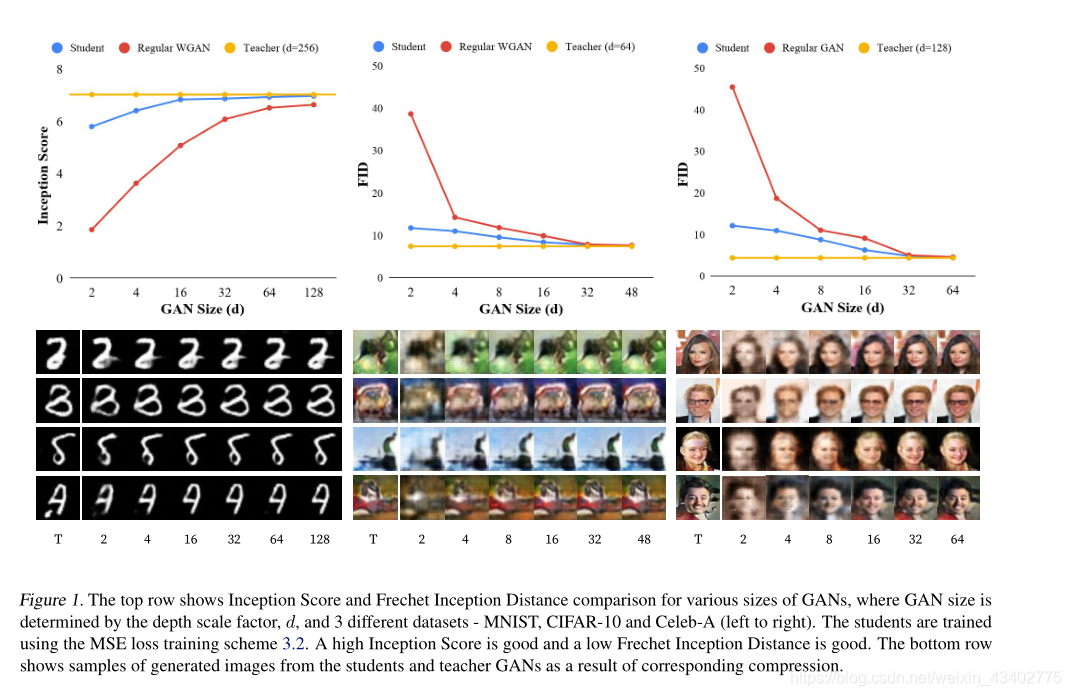
6.Compressing GANs using Knowledge Distillation
論文鏈接
上面幾篇都是對普通的卷積網絡進行壓縮,這個文章是對gan進行壓縮。
貢獻:
1.認為一個超參數的老師網絡去蒸餾有更好的效果
2.全文證明了學生網絡的參數越多,效果越好
論文內容
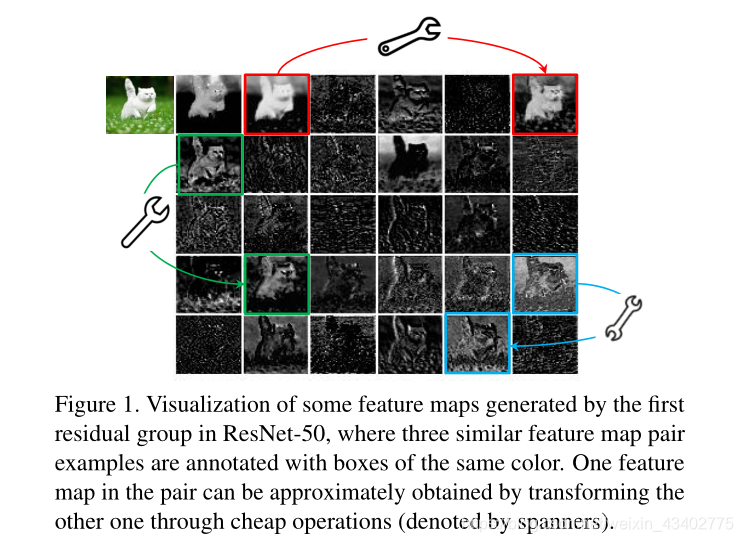
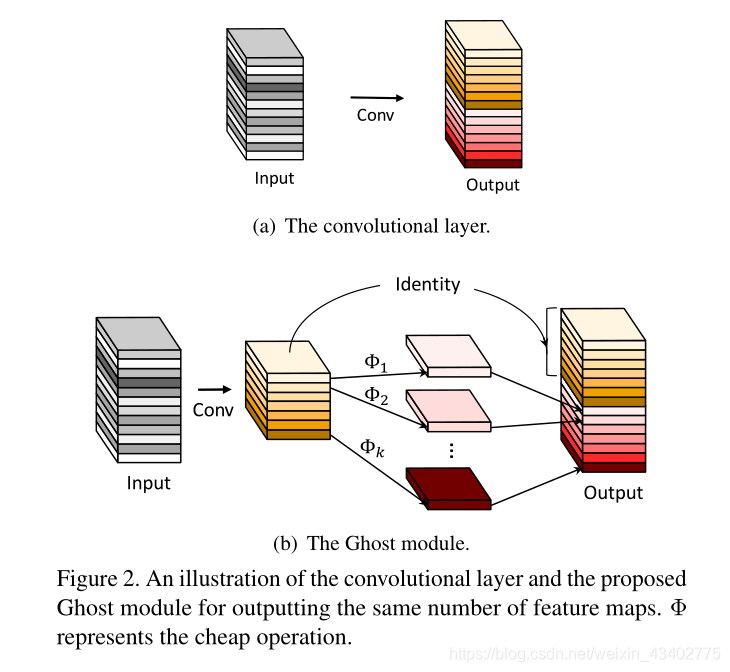
7.GhostNet: More Feature from Cheap Operation(CVPR2020)
主要內容;
使用線性操作,復制更多地feature maps,以此代替卷積操作,這樣可以簡化模型
思想很簡單

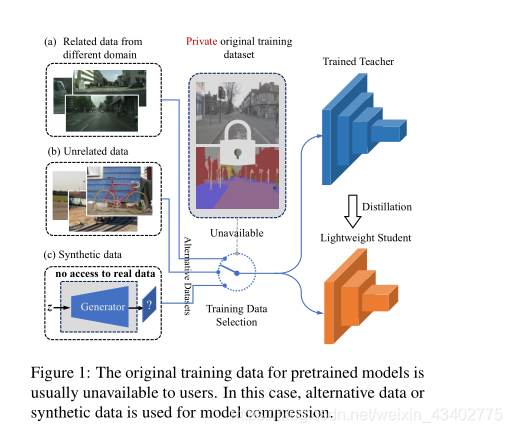
8.Data-Free Adversarial Distillation
動機:
- 原始的訓練數據不存在,
2.訓練S時,使用一些具有代表性特征的數據 (hard sample)
方法:
1.利用G隨機生成數據,盡量拉遠S和T的距離
2.訓練S,使S和T的距離變小
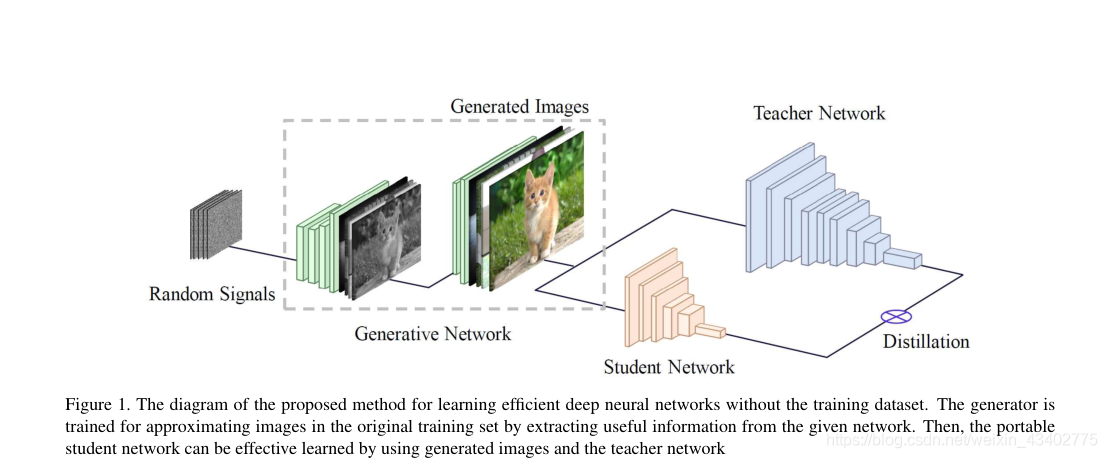
9.Data-Free Learning of Student Networks (ICCV2020)
動機:
1.不使用原數據集
內容:
1.迭代訓練 G 和 S
2.學習原始數據集的分布,更快的生成圖片
3.設置了三個損失函數去限制生成器,生成更加好的圖片



 type的運用)


 和.cuda()的區別)


返回false的解決辦法)









