集合的引入
List (ArrayList LinkedList)
Set (HashSet LinkedHashSet TreeSet )
Map (HashMap LinkedHashMap TreeMap)
Collections
Iterator
使用泛型
1.為什么使用集合而不是數組?
集合和數組相似點
都可以存儲多個對象,對外作為一個整體存在
數組的缺點
長度必須在初始化時指定,且固定不變
數組采用連續存儲空間,刪除和添加效率低下
數組無法直接保存映射關系
數組缺乏封裝,操作繁瑣
2.集合架構
Java集合框架提供了一套性能優良、使用方便的接口和類,它們位于java.util包中
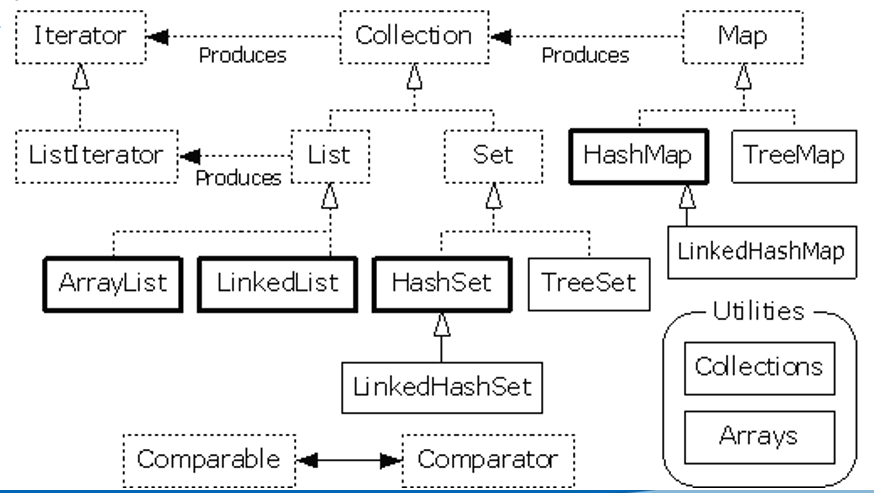
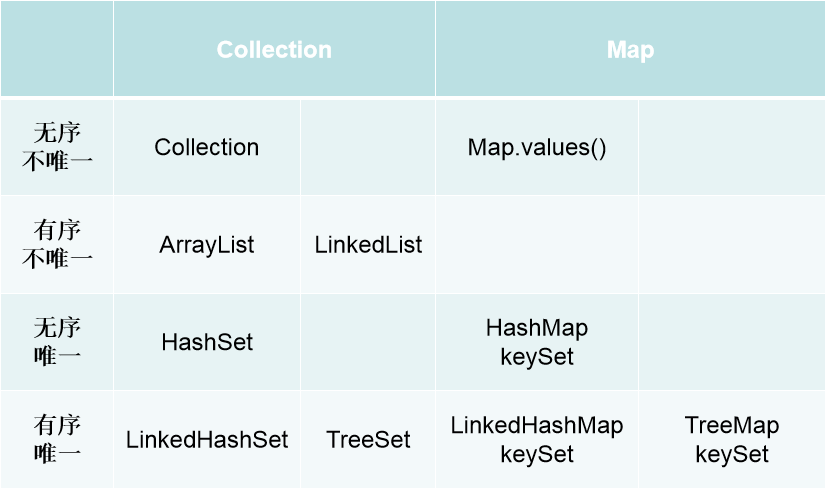
Collection 接口存儲一組不唯一,無序的對象
List 接口存儲一組不唯一,有序(索引順序)的對象
Set 接口存儲一組唯一,無序的對象
Map接口存儲一組鍵值對象,提供key到value的映射
Key 唯一 無序
value 不唯一 無序
2.1?List
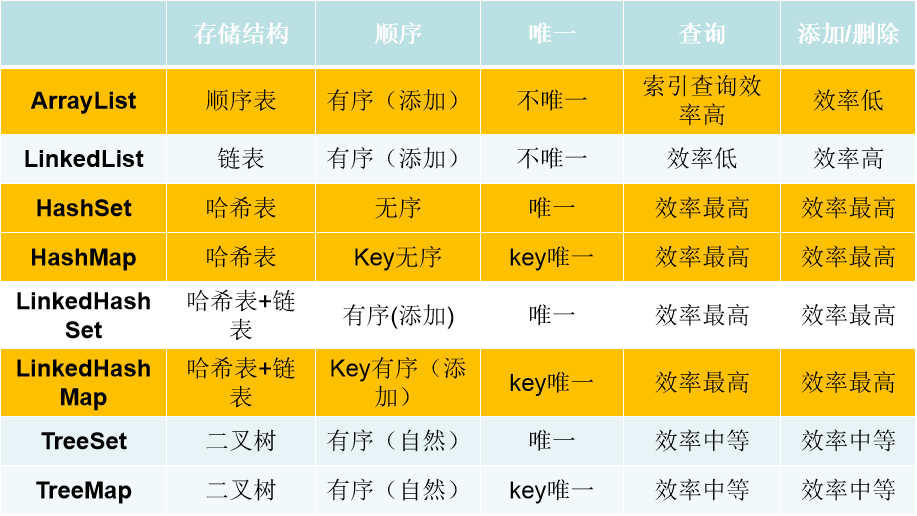
特點:有序? 不唯一(可重復)
ArrayList:ArrayList是一個對數組進行了封裝的容器。使用過程中ArrayList對于數據的查找及遍歷效率較高。
在內存中分配連續的空間,實現了長度可變的數組
優點:遍歷元素和隨機訪問元素的效率比較高
缺點:添加和刪除需大量移動元素效率低,按照內容查詢效率低,
ArrayList常用方法
Add() :向現有集合中添加或插入一個元素
Get() :獲取指定索引位置的元素
Set() :設置指定索引位置的元素值
Clear() :清除所有的元素值
Remove() :刪除指定索引位置的元素
Size() :獲取容器中元素的個數
LinkedList:LinkedList在底層是一雙向鏈表的形式進行實現,LinkedList在執行數據的維護過程中效率較高。LinkedList允許以隊列或棧的方式訪問數據。
采用鏈表存儲方式。
缺點:遍歷和隨機訪問元素效率低下
優點:插入、刪除元素效率比較高(但是前提也是必須先低效率查詢才可。如果插入刪除發生在頭尾可以減少查詢次數)
LinkedList常用方法:
getFirst() :獲取列表中的第一個元素
getLast() :獲取列表中的最后一個元素
peek() :以隊列的方式獲取列表數據(獲取不刪除)
poll() :以隊列的方式獲取列表數據(獲取并刪除)
push() :以棧的方式將數據壓入到列表中
pop() :以出棧的方式訪問元素(獲取并刪除)
其他方法參見ArrayList
List的遍歷方法
for
for-each
Iterator迭代器
集合中內容是否相同
通過equals進行內容比較,而是==引用比較
2.2?Set
特點:無序 唯一(不重復)
HashSet
采用Hashtable哈希表存儲結構(神奇的結構)
優點:添加速度快 查詢速度快 刪除速度快
缺點:無序
HashSet常用方法:
Add() :向集合中添加一個元素
Clear() :清除集合中所有元素
Remove() :按照元素之刪除集合中指定的元素
注意:HashSet中不支持下標方式訪問及修改元素值。
LinkedHashSet
采用哈希表存儲結構,同時使用鏈表維護次序
有序(添加順序)
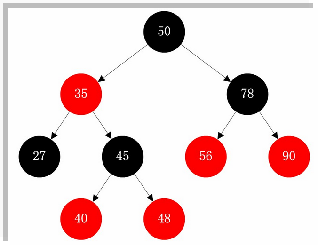
TreeSet
采用二叉樹(紅黑樹)的存儲結構
優點:有序 查詢速度比List快(按照內容查詢)
缺點:查詢速度沒有HashSet快
Set常用方法
Set相對Collection沒有增加任何方法
Set的遍歷方法
for-each
Iterator迭代器
無法使用for進行遍歷(因為無序,所以沒有get(i))
HashSet、HashMap或Hashtable中對象唯一性判斷
重寫其hashCode()和equals()方法
TreeSet中指明排序依據
實現Comparable接口 創建實現Compator接口的類。
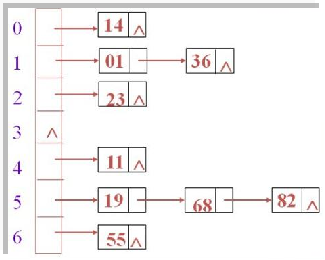
哈希表存儲原理
2.3?Map
特點 key-value映射
HashMap
Key無序 唯一 (Set)
Value 無序 不唯一 (Collection)
LinkedHashMap
有序的HashMap 速度快
TreeMap
有序 速度沒有hash快
問題:Set和Map有關系嗎?
采用了相同的數據結構,只用于map的key存儲數據,就是Set
3.?Collections
專門用來操作集合的工具類
構造方法私有,禁止創建對象
提供一系列靜態方法實現對各種集合的操作
具體操作:搜索、復制、排序、線程安全化等
常用方法
Collections.addAll(list, "aaa","bbb","ccc","ccc");
int index = Collections.binarySearch(list, "ccc");
Collections.copy(list2, list);
Collections.fill(list3, "888");
String max = Collections.max(list4);
String min = Collections.min(list4);
Collections.reverse(list4);
List list5 = Collections.synchronizedList(list4);
4.?Iterator
所有集合類均未提供相應的遍歷方法,而是把把遍歷交給迭代器完成。
迭代器為集合而生,專門實現集合遍歷
Iterator是迭代器設計模式的具體實現
Iterator方法
boolean hasNext(): 判斷是否存在另一個可訪問的元素
Object next(): 返回要訪問的下一個元素
void remove(): 刪除上次訪問返回的對象。
問題:可以使用Iterator遍歷的本質是什么
實現Iterable接口
For-each循環
增強的for循環,遍歷array 或 Collection的時候相當簡便
無需獲得集合和數組長度,無需使用索引訪問元素,無需循環條件
遍歷集合時底層調用Iterator完成操作
For-each缺陷:
數組:
不能方便的訪問下標值
不要在for-each中嘗試對變量賦值,只是一個臨時變量
集合:
與使用Iterator相比,不能方便的刪除集合中的內容
For-each總結:
除了簡單遍歷并讀出其中的內容外,不建議使用增強for
5.泛型
JDK1.4以前類型不明確: 裝入集合的類型都被當作Object對待,從而失去自己的實際類型。 從集合中取出時往往需要轉型,效率低,容易產生錯誤。
泛型:在定義集合的時候同時定義集合中對象的類型
好處: 增強程序的可讀性和安全性
6.術語辨析
集合和數組的比較
Collection和Collections的區別
ArrayList和LinkedList 的聯系和區別
Vector和ArrayList的聯系和區別
HashMap和Hashtable的聯系和區別
集合和數組的比較:
數組不是面向對象的,存在明顯的缺陷,
集合完全彌補了數組的一些缺點,比數組更靈活更實用,
可大大提高軟件的開發效率而且不同的集合框架類可適用于不同場合。具體如下:
1:數組能存放基本數據類型和對象,而集合類中只能放對象。
2 : 數組容量固定且無法動態改變,集合類容量動態改變。
3:數組無法判斷其中實際存有多少元素,length只告訴了array容量
4:集合有多種實現方式和不同適用場合,不像數組僅采用順序表方式
5:集合以類的形式存在,具有封裝、繼承、多態等類的特性,通過簡單的方法和屬性調用即可實現各種復雜操作,大大提高軟件的開發效率
ArrayList和LinkedList 的聯系和區別
聯系: 都實現了List接口 有序 不唯一(可重復)
ArrayList
在內存中分配連續的空間,采用了順序表結構,實現了長度可變的數組
優點:遍歷元素和隨機訪問元素的效率比較高
缺點:添加和刪除需大量移動元素效率低,按照內容查詢效率低,
LinkedList
采用鏈表存儲方式。
缺點:遍歷和隨機訪問元素效率低下
優點:插入、刪除元素效率比較高(但是前提也是必須先低效率查詢才可。如果插入刪除發生在頭尾可以減少查詢次數)
Collection和Collections的區別:
Collection是Java提供的集合接口,存儲一組不唯一,無序的對象。它有兩個子接口List和Set。
Java中還有一個Collections類,專門用來操作集合類 ,它提供一系列靜態方法實現對各種集合的搜索、排序、線程安全化等操作。
Vector和ArrayList的聯系和區別:
實現原理相同,功能相同,都是長度可變的數組結構,很多情況下可以互用
兩者的主要區別如下:
Vector是早期JDK接口,ArrayList是替代Vector的新接口
Vector線程安全,ArrayList重速度輕安全,線程非安全
長度需增長時,Vector默認增長一倍,ArrayList增長50%
HashMap和Hashtable的聯系和區別
實現原理相同,功能相同,底層都是哈希表結構,查詢速度快,在很多情況下可以互用
兩者的主要區別如下:
Hashtable是早期JDK提供的接口,HashMap是新版JDK提供的接口
Hashtable繼承Dictionary類,HashMap實現Map接口
Hashtable線程安全,HashMap線程非安全
Hashtable不允許null值,HashMap允許null值
7.小結
面試大總結之一:Java搞定面試中的鏈表題目)










和OGNL表達式)

_PHP教程)





