一、深度學習的發展及其應用
1.1 深度學習的發展歷程
1956年,John McCarthy(約翰·麥卡錫)等人在美國達特茅斯學院(Dartmounth College)開會探討如何使用機器模擬人的智能時,提出了“人工智能”這一概念。
這標志著人工智能學科的誕生,這一年也稱為人工智能元年。
作為人工智能最重要的一個分支,深度學習近年來發展迅速,在國內外都引起了廣泛的關注。


1.2 深度學習的起源階段
1943年,心理學家Warren Mcculloch和數理邏輯學家Walter Pitts在合作的論文中提出并給出了人工神經網絡的概念及人工神神經元的數學模型,從而開創了人類神經網絡研究的時代。
1956年,心理學家Frank Rosenblatt受到這種思想的啟發,認為這個簡單想法足以創造一個可以學習識別物體的機器,并設計了算法和硬件。直到1957年,Frank Rosenblatt在《New York Times》上發表文章《Electronic ‘Brain’ Teaches Itself》,首次提出了可以模型人類感知能力的機器,并稱之為感知機(Perceptron)

感知機是有單層計算單元的神經網絡,由線性元件及閾值元件組成。感知機的邏輯圖如圖

1969年,美國數學家及人工智能先驅Marvin Minsky(馬文·明斯基)在其著作中證明感知器本質上是一種線性模型,只能處理線性分類的問題,這使得神經網絡的研究陷入近20年的停滯。
1.3 深度學習的發展階段
沉寂了多年后,關于神經網絡的研究開始慢慢復蘇。
1986年,Geoffrey Hinton(杰弗里·辛頓)提出一種適用于多層感知器的反向傳播算法———BP算法。
BP算法全稱叫作誤差反向傳播(error Back Propagation,或者也叫作誤差逆傳播)算法。
其算法基本思想為:在前饋網絡中,輸入信號經輸入層輸入,通過隱層計算由輸出層輸出,輸出值與標記值比較,若有誤差,將誤差反向由輸出層向輸入層傳播,在這個過程中,利用梯度下降算法對神經元權值進行調整。
BP算法完美解決了非線性分類的問題,人人工神經網絡再次引起人們廣泛關注。
1989年,Robert Hecht-Nielsen(羅伯特·赫克特-尼爾森)證明了多層感知器的萬能逼近原理。
此博文中介紹的論文是 1990 年?Le Page 組織的一個會議的 Invited paper.
-
一維階梯函數的線性組合能逼近任何連續一維連續函數。
-
Sigmoidal 函數可以逼近階梯函數。因此,一維Sigmoidal函數的線性組合能逼近任何連續函數。
-
把坐標軸在R^{n}中沿各個方向旋轉 (如同CT原理),在每一射線上,構造Sigmoidal函數的線性組合,就可以逼近R^{n}中任何連續函數。
-
優點:用一個簡單到不能再簡單的函數的線性組合和疊合可以逼近任何連續函數。
-
缺點:天下沒有免費的午餐。
-
為了R^{n} 中函數達到精度1/N。需要識別 O(n^{N}) 個參數。這是無法承受的。
-
?無論用階梯函數還是Sigmoidal 函數,關鍵是利用其跳躍部分。因此,在用梯度法時,經常會發生導數不可控。
-
上述兩個致命缺點長期阻礙了神經網絡的發展和應用。深度學習就是圍繞著這些問題來做的。通俗的講,是實現神經網絡逼近能力的技術
由于20世紀80年代計算機的硬件水平有限,運算能力跟不上,導致神經網絡規模增大時使用BP算法出現了“梯度消失”問題,這導致BP算法的發展受到了限制,人工神經網絡的發展再次進入到瓶頸期。
1.4 深度學習的爆發階段
2006年是深度學習元年。這一年,Geoffey Hinton(杰弗里·辛頓)提出了深度學習的概念,并提出了深層網絡訓練中梯度消失問題的解決方案———通過無監督預訓練對權值進行初始化,再加上有監督訓練微調。
1、無監督預訓練是用來訓練的數據不包含輸出目標,需要學習算法自動學習到一些有價值的信息。
2、有監督訓練,又稱監督學習,是一個機器學習中的方法,可以由訓練資料中學到或建立一個模式(函數 / learning model),并依此模式推測新的實例。訓練資料是由輸入物件(通常是向量)和預期輸出所組成。函數的輸出可以是一個連續的值(稱為回歸分析),或是預測一個分類標簽(稱作分類)。
2012年,Geoffey Hinton 課題組為了證明深度學習的潛力,首次參加ImageNet圖像識別比賽,其構建的卷積神經網絡模型AlexNet一舉奪冠,且再分類準確率和分類速度上碾壓第二名SVM(支持向量機模型)。
2014年,Facebook公司基于深度學習技術的DeepFace項目,在人臉識別方面的準確率已經達到97%以上,跟人眼識別的準確率幾乎沒有差別,再一次證明了深度學習算法在圖像識別方面的領先性。
2016年,Google公司基于深度學習開發的AlphaGo以4:1的比分戰勝了國際頂尖圍棋高手李世石,使得深度學習在世界范圍內再次掀起狂潮。

又一年,2017年,世界第一的中國棋手柯潔九段與AlphaGo進行對抗

1.5深度學習的應用領域
1、計算機視覺
1、什么是計算機視覺(Computer vision)?
計算機視覺(Computer Vision),人靠視覺來做飯、越過障礙等等,Computer Vision就是讓計算機有視覺,目的是讓計算機看懂圖像(image)和視頻(video),手機或相機固然可以拍出很精細和細節的照片,比人看的遠,清除,但是李飛飛教授說過:“
hear is the not the same as to listen, To take pictures is not the same as to see”,所以計算機視覺目的是看懂。
看-------看是很簡單的,計算機比人更會看(image, video)
懂-----我認為懂是讓計算機能夠在image和video中,根據人的命令來做相應的動作。就像人看懂一樣,首先人要看到東西(image or video),然后大腦根據東西做出相關動作。由于計算機不能夠像人一樣global地分析image or video,所以我們要做image process :為存儲、除數和表示而對image data進行處理,以便計算機自動理解。自動理解后,我們向其發送指令,它便可以和人一樣。
2、自然語言處理
????? 自然語言處理( Natural Language Processing, NLP)是計算機科學領域與人工智能領域中的一個重要方向。它研究能實現人與計算機之間用自然語言進行有效通信的各種理論和方法。自然語言處理是一門融語言學、計算機科學、數學于一體的科學。因此,這一領域的研究將涉及自然語言,即人們日常使用的語言,所以它與語言學的研究有著密切的聯系,但又有重要的區別。自然語言處理并不是一般地研究自然語言,而在于研制能有效地實現自然語言通信的計算機系統,特別是其中的軟件系統。因而它是計算機科學的一部分
1.6深度學習框架簡介
1、TensorFlow
TensorFlow是一個開放源代碼軟件庫,用于進行高性能數值計算。借助其靈活的架構,用戶可以輕松地將計算工作部署到多種平臺(CPU、GPU、TPU)和設備(桌面設備、服務器集群、移動設備、邊緣設備等)。
ensorFlow 是一個用于研究和生產的開放源代碼機器學習庫。TensorFlow 提供了各種 API,可供初學者和專家在桌面、移動、網絡和云端環境下進行開發。
TensorFlow是采用數據流圖(data flow graphs)來計算,所以首先我們得創建一個數據流流圖,然后再將我們的數據(數據以張量(tensor)的形式存在)放在數據流圖中計算. 節點(Nodes)在圖中表示數學操作,圖中的邊(edges)則表示在節點間相互聯系的多維數據數組, 即張量(tensor)。訓練模型時tensor會不斷的從數據流圖中的一個節點flow到另一節點, 這就是TensorFlow名字的由來。
張量(Tensor):張量有多種. 零階張量為 純量或標量 (scalar) 也就是一個數值. 比如 [1],一階張量為 向量 (vector), 比如 一維的 [1, 2, 3],二階張量為 矩陣 (matrix), 比如 二維的 [[1, 2, 3],[4, 5, 6],[7, 8, 9]],以此類推, 還有 三階 三維的 …
張量從流圖的一端流動到另一端的計算過程。它生動形象地描述了復雜數據結構在人工神經網中的流動、傳輸、分析和處理模式。
在機器學習中,數值通常由4種類型構成:
(1)標量(scalar):即一個數值,它是計算的最小單元,如“1”或“3.2”等。
(2)向量(vector):由一些標量構成的一維數組,如[1, 3.2, 4.6]等。
(3)矩陣(matrix):是由標量構成的二維數組。
(4)張量(tensor):由多維(通常)數組構成的數據集合,可理解為高維矩陣。
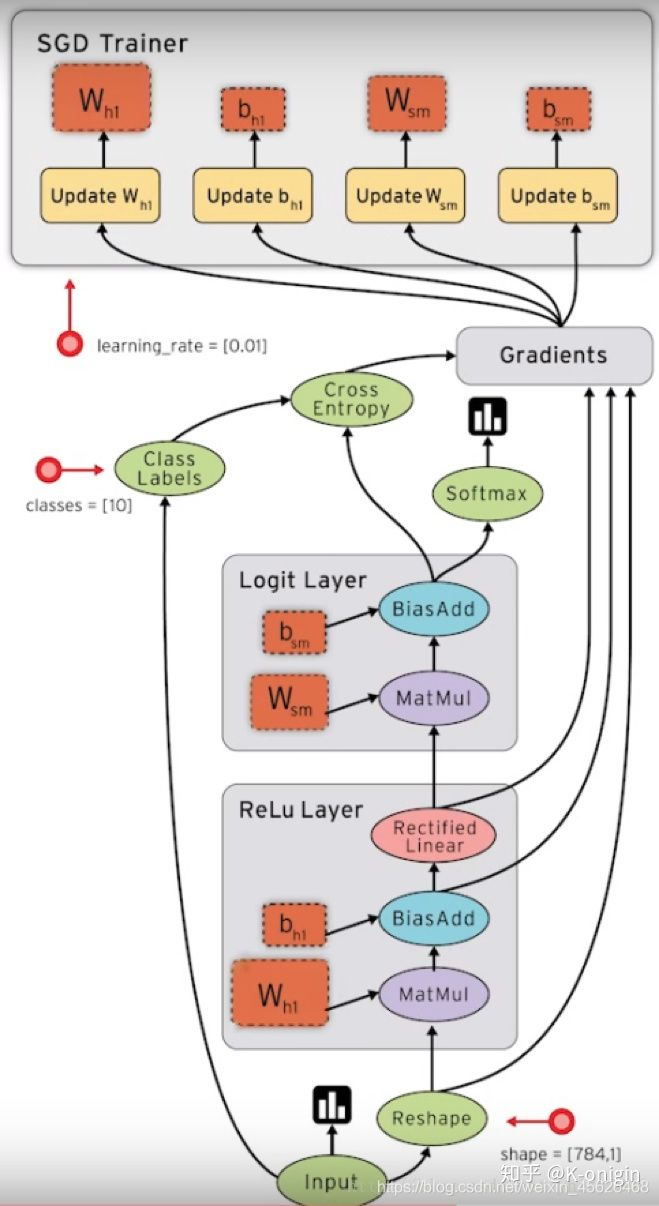
使用TensorFlow的優點主要表現在如下幾個方面:
(1)TensorFlow有一個非常直觀的構架,顧名思義,它有一個“張量流”。用戶可以很容易地看到張量流動的每一個部分(借助TensorBoard,在后面的章節會有所提及)。
(2)TensorFlow可輕松地在CPU/GPU上部署,進行分布式計算。
(3)TensorFlow跨平臺性高,靈活性強。TensorFlow不但可以在Linux、Mac和Windows系統下運行,甚至還可以在移動終端下工作。
當然,TensorFlow也有不足之處,主要表現在它的代碼比較底層,需要用戶編寫大量的代碼,而且很多相似的功能,用戶還不得不“重造輪子”。但“瑕不掩瑜”,TensorFlow還是以雄厚技術積淀、穩定的性能,一騎紅塵,“笑傲”于眾多深度學習框架之巔。
2、Caffe
Caffe是一個深度學習框架,Caffe在BSD許可下開源,使用C++編寫,帶有Python接口。是賈揚清在加州大學伯克利分校攻讀博士期間創建了Caffe項目。項目托管于GitHub,擁有眾多貢獻者。Caffe應用于學術研究項目、初創原型甚至視覺、語音和多媒體領域的大規模工業應用。雅虎還將Caffe與Apache Spark集成在一起,創建了一個分布式深度學習框架CaffeOnSpark。2017年4月,Facebook發布Caffe2,加入了遞歸神經網絡等新功能。2018年3月底,Caffe2并入PyTorch。
特點
Caffe 完全開源,并且在有多個活躍社區溝通解答問題,同時提供了一個用于訓練、測試等完整工具包,可以幫助使用者快速上手。此外 Caffe 還具有以下特點:
模塊性:Caffe 以模塊化原則設計,實現了對新的數據格式,網絡層和損失函數輕松擴展。
表示和實現分離:Caffe 已經用谷歌的 Protocl Buffer定義模型文件。使用特殊的文本文件 prototxt 表示網絡結構,以有向非循環圖形式的網絡構建。
Python和MATLAB結合: Caffe 提供了 Python 和 MATLAB 接口,供使用者選擇熟悉的語言調用部署算法應用。
GPU 加速:利用了 MKL、Open BLAS、cu BLAS 等計算庫,利用GPU實現計算加速。
結構
簡單來講,Caffe 中的數據結構是以 Blobs-layers-Net 形式存在。其中,Blobs 是通過 4 維向量形式(num,channel,height,width)存儲網絡中所有權重,激活值以及正向反向的數據。作為 Caffe 的標準數據格式,Blob 提供了統一內存接口。Layers 表示的是神經網絡中具體層,例如卷積層等,是 Caffe 模型的本質內容和執行計算的基本單元。layer 層接收底層輸入的 Blobs,向高層輸出 Blobs。在每層會實現前向傳播,后向傳播。Net 是由多個層連接在一起,組成的有向無環圖。一個網絡將最初的 data 數據層加載數據開始到最后的 loss 層組合為整體。
3、PyTorch
PyTorch是一個的Python機器學習開源庫,基于Torch,用于自然語言處理等應用程序。
2017年1月,由Facebook人工智能研究院(FAIR)基于Torch推出了PyTorch。它是一個基于Python的可續計算包,提供兩個高級功能:1、具有強大的GPU加速的張量計算(如NumPy)。2、包含自動求導系統的深度神經網絡。
PyTorch的前身是Torch,其底層和Torch框架一樣,但是使用Python重新寫了很多內容,不僅更加靈活,支持動態圖,而且提供了Python接口。它是由Torch7團隊開發,是一個以Python優先的深度學習框架,不僅能夠實現強大的GPU加速,同時還支持動態神經網絡。
PyTorch既可以看作加入了GPU支持的numpy,同時也可以看成一個擁有自動求導功能的強大的深度神經網絡。除了Facebook外,它已經被Twitter、CMU和Salesforce等機構采用
優點:
-
PyTorch是相當簡潔且高效快速的框架
-
設計追求最少的封裝
-
設計符合人類思維,它讓用戶盡可能地專注于實現自己的想法
-
與google的Tensorflow類似,FAIR的支持足以確保PyTorch獲得持續的開發更新
-
PyTorch作者親自維護的論壇 供用戶交流和求教問題
-
入門簡單
4、MXNet
MXNet 是亞馬遜(Amazon)選擇的深度學習庫。它擁有類似于 Theano 和 TensorFlow 的數據流圖,為多 GPU 配置提供了良好的配置,有著類似于 Lasagne 和 Blocks 更高級別的模型構建塊,并且可以在你可以想象的任何硬件上運行(包括手機)。對 Python 的支持只是其冰山一角—MXNet 同樣提供了對 R、Julia、C++、Scala、Matlab,和 Javascript 的接口。
增強了sparse.dot運算符的性能。
MXNet自動設置OpenMP,以便在未設置NUM_OMP_THREADS時使用所有可用的CPU內核以最大限度地提高CPU利用率。
一元運算符和二元運算符可以避免在小型陣列上使用OpenMP,因為使用OpenMP實際上會損害多線程開銷。
在CPU上顯著提高了broadcast_add,broadcast_mul等的性能 。
使用NCCL 2.1版或更新版本時,建議將環境變量NCCL_LAUNCH_MODE設置為PARALLEL。
MXNet可以加速任何數值計算。神經網絡中,每一層由一個線性函數和一個非線性變換組成。
開發環境搭建鏈接:
https://blog.csdn.net/weixin_45626468/article/details/114692986?spm=1001.2014.3001.5501
)
)

)
)
)
)
)
)
)
)
)
)
)
)
)
)
)
)
)