APScheduler:定時任務框架
安裝
文檔:
https://apscheduler.readthedocs.io/en/stable/userguide.html安裝
$?pip?install?apscheduler>>>?import?apscheduler
>>>?apscheduler.version
'3.6.3'
組件
APScheduler由一下四部分組成
triggers:觸發器,指定定時任務執行的時機,每個任務都有自己的觸發器.job stores:存儲器,持久存儲,默認存儲在內存中.executors:執行器,在定時任務執行時,以進程或線程方式執行scheduler:調度器,包含BackgroundScheduler(后臺運行)和BlockingScheduler(阻塞運行).他會合理安排作業存儲器,執行器,觸發器進行工作.并進行添加和刪除任務等.調度器通常是只有一個的,開發人員很少直接操作觸發器,存儲器,執行器等.因為這些都由調度器自動來實現了.10334
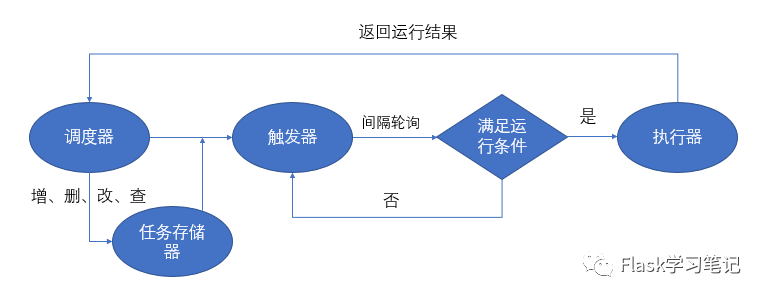
觸發器(triggers)
1.date在特定時間執行
示例:
from?datetime?import?date,?datetime
from?apscheduler.schedulers.blocking?import?BlockingScheduler
sched?=?BlockingScheduler()
def?my_job(text):
???print(text)
#?run_date?接受?date,?datetime?數據類型
sched.add_job(my_job,?'date',?run_date=datetime(2020,?11,?27,?19,?33,?30),?args=['text'])
sched.start()更多:
https://apscheduler.readthedocs.io/en/stable/modules/triggers/date.html
2.interval間隔執行
在固定的時間間隔后觸發事件.參數如下:
weeks周,整形 days一個月中的第幾天,整形 hours時,整形 minutes分,整形 seconds秒,整形 start_date起始時間 end_date結束時間 jitter觸發的時間誤差 from?apscheduler.schedulers.blocking?import?BlockingScheduler
from?datetime?import?datetime
sched?=?BlockingScheduler()
def?job_funciton():
???print('hello?world')
sched.add_job(job_funciton,?trigger='interval',seconds=5)
#?指定小時
#?sched.add_job(job_funciton,?trigger='interval',?hours=2)
#?指定開始,結束時間
#?sched.add_job(job_funciton,?trigger='interval',?start_date='2020-11-27?20:30:00',?end_date='2010-11-27?21:30:00)
sched.start()?
3.crontab
在某個確切的時間周期性觸發事件.
year年 month1-12月day1-31日week1-53周day_of_week一周中的第幾天( 0/Monday)hour0-23minute0-59second0-59start_datedatetime數據類型,或者字符串類型end_date結束時間 timezone時區 jitter觸發的誤差時間 也可以用表達式類型,可以用以下方式:
表達式 字段 描述 * 任何 在每個值都觸發 */a 任何 每隔 a觸發一次 a-b 任何 在 a-b區間內任何一個時間觸發( a必須小于 b) a-b/c 任何 在 a-b區間內每隔 c觸發一次 xth y day 第 x個星期 y觸發 lastx day 最后一個星期 x觸發 last day 一個月中的最后一天觸發 x,y,z 任何 可以把上面的表達式進行組合 from?apscheduler.schedulers.blocking?import?BlockingScheduler
def?job_function():
???print?"Hello?World"
sched?=?BlockingScheduler()
#?Schedules?job_function?to?be?run?on?the?third?Friday
#?of?June,?July,?August,?November?and?December?at?00:00,?01:00,?02:00?and?03:00
sched.add_job(job_function,?'cron',?month='6-8,11-12',?day='3rd?fri',?hour='0-3')
sched.start()
調度器(schedulers)
BlockingScheduler:適用于調度程序是進程中唯一運行的進程,調用start函數會阻塞當前線程,不能立即返回。BackgroundScheduler:適用于調度程序在應用程序的后臺運行,調用start后主線程不會阻塞。AsyncIOScheduler:適用于使用了asyncio模塊的應用程序。GeventScheduler:適用于使用gevent模塊的應用程序。TwistedScheduler:適用于構建Twisted的應用程序。QtScheduler:適用于構建Qt的應用程序。TornadoScheduler:tornado
任務存儲器(job stores)
有2中方式,一種是加載在內存中(默認配置),一種是使用數據庫.使用內存簡單高效,但是程序出現問題,從新運行,會把以前的任務從新再執行一次.數據庫則可以在中斷的地方恢復正常使用.
MemoryJobStore:使用內存MongoDBJobStore:使用mongodbRedisJobStore:使用redisSQLAlchemy:使用SQLAlchemy框架
1.RedisJobStore
RedisJobStore(db=0,?jobs_key='apscheduler.jobs',?run_times_key='apscheduler.run_times',?pickle_protocol=pickle.HIGHEST_PROTOCOL,?**connect_args)有2種創建的方法:
add_jobstore:需要指定redis的相關參數.from?datetime?import?datetime,?timedelta
import?sys
import?os
from?apscheduler.schedulers.blocking?import?BlockingScheduler
from?apscheduler.jobstores.redis?import?RedisJobStore
def?alarm(time):
????print('Alarm!?This?alarm?was?scheduled?at?%s.'?%?time)
if?__name__?==?'__main__':
????scheduler?=?BlockingScheduler()
????scheduler.add_jobstore('redis',?jobs_key='example.jobs',?run_times_key='example.run_times',?host='192.168.0.101',?port=6379,?db=0)
????if?len(sys.argv)?>?1?and?sys.argv[1]?==?'--clear':
????????scheduler.remove_all_jobs()
????alarm_time?=?datetime.now()?+?timedelta(seconds=300)
????scheduler.add_job(alarm,?'date',?run_date=alarm_time,?args=[datetime.now()])
????print('To?clear?the?alarms,?run?this?example?with?the?--clear?argument.')
????print('Press?Ctrl+{0}?to?exit'.format('Break'?if?os.name?==?'nt'?else?'C'))
????try:
????????scheduler.start()
????except?(KeyboardInterrupt,?SystemExit):
????????pass
RedisJobStorefrom?apscheduler.schedulers.blocking?import?BlockingScheduler
from?apscheduler.jobstores.redis?import?RedisJobStore
from?datetime?import?datetime,?timedelta
jobstore?=?{
????'default'?:?RedisJobStore(db=0,?jobs_key='myfunc',?run_times_key='myfunc_time',?host='192.168.0.101',?port=6379)
}
def?my_func(t):
????print('hello?world,?%s'?%t)
if?__name__?==?'__main__':
????sched?=?BlockingScheduler(jobstores=jobstore)
????alarm_time?=?datetime.now()?+?timedelta(seconds=300)
????sched.add_job(my_func,run_date=alarm_time,?args=['ning'])
????sched.start()均可在
redis中查詢到數據.
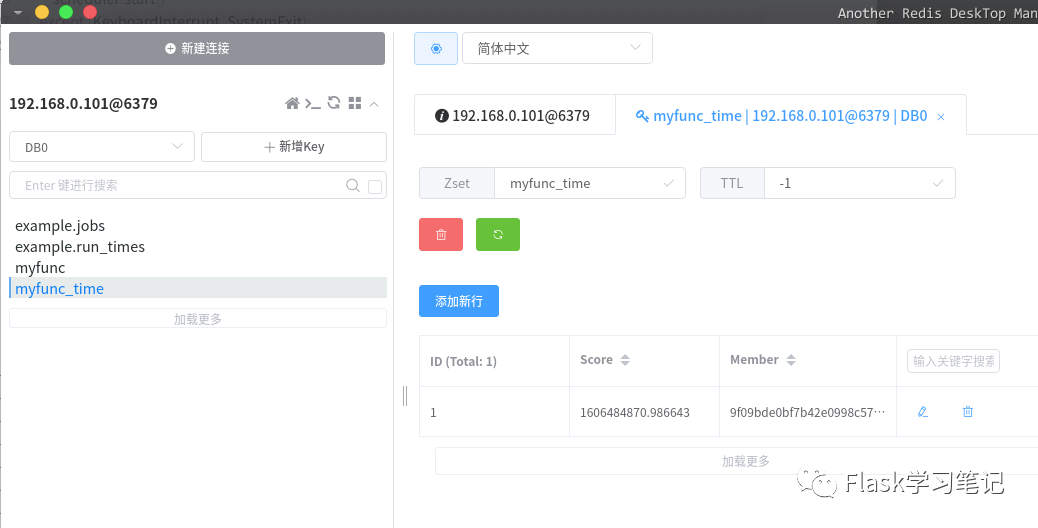
2.SQLAlchemy
使用
ORM框架,演示使用MySqlfrom?apscheduler.schedulers.blocking?import?BlockingScheduler
from?datetime?import?datetime,?timedelta
def?my_func(t):
???print('hello?%s'?%t)
if?__name__?==?"__main__":
???sched?=?BlockingScheduler()
???url?=?'mysql+pymysql://root:2008.Cn123@192.168.0.101:3306/test'
???sched.add_jobstore('sqlalchemy',?url=url,tablename='api_job')
???alarm_time?=?datetime.now()?+?timedelta(seconds=300)
???sched.add_job(my_func,run_date=alarm_time,?args=['ning'])
???sched.start()如果表不存在,會自動創建表.
tablename用于指定表的名稱.在數據庫中可以查看到表
select?*?from?api_job;10336

執行器executors
執行器取決于應用場景,默認是
ThreadPoolExecutor,它可以滿足大部分需求.如果是CPU密集型計算,可以選擇ProcessPoolExecutorclass?apscheduler.executors.pool.ThreadPoolExecutor(max_workers=10)class?apscheduler.executors.pool.ProcessPoolExecutor(max_workers=10)
#?max_worker?指定最多使用線程/進程from?apscheduler.schedulers.background?import?BackgroundScheduler
from?apscheduler.executors.pool?import?ThreadPoolExecutor
executors?=?{
???'default':?ThreadPoolExecutor(20),
}
conf?=?{?#?redis配置
???"host":127.0.0.1,
???"port":6379,
???"db":15,?#?連接15號數據庫
???"max_connections":10?#?redis最大支持300個連接數
}
scheduler?=?BackgroundScheduler(executors=executors)
scheduler.add_jobstore(jobstore='redis',?**conf)?#?添加任務持久化存儲方式,如果未安裝redis可省略此步驟
任務操作
add_job(func, id='xxx', args=None, kwargs=None)添加任務#?添加任務func,?func參數可以使用?'可導入模塊:可調用對象'的方式引入,即可用模塊來引入
#??tree?-L?2
#├──?func
#│???├──?add_func.py
#│???├──?__init__.py
#└──?jobs.py
#?add_func.py
def?add(x,y):
????print(x+y)
????
#?jobs.py
from?apscheduler.schedulers.blocking?import?BlockingScheduler
from?func.add_func?import?add
shced?=?BlockingScheduler()
if?__name__?==?"__main__":
????shced.add_job('func.add_func:add',?args=[1,2],?id='job1')
????shced.start()???除去使用
add_job(),還可以使用裝飾器函數scheduled_job來添加任務.
remove_job(job_id):刪除任務,需要指定job_idpause_job(job_id):暫停任務resume_job(job_id):恢復任務modify_job(job_id, **changes):修改任務屬性print_jobs():作業信息#?方法1
job?=?scheduler.add_job(myfunc,?'interval',?minutes=2)??#?添加任務
job.remove()??#?刪除任務
job.pause()?#?暫定任務
job.resume()??#?恢復任務
#?方法2
scheduler.add_job(myfunc,?'interval',?minutes=2,?id='my_job_id')??#?添加任務????
scheduler.remove_job('my_job_id')??#?刪除任務
scheduler.pause_job('my_job_id')??#?暫定任務
scheduler.resume_job('my_job_id')??#?恢復任務
示例
方法1
from?pytz?import?utc
from?datetime?import?datetime
from?apscheduler.schedulers.background?import?BackgroundScheduler
from?apscheduler.jobstores.mongodb?import?MongoDBJobStore
from?apscheduler.jobstores.sqlalchemy?import?SQLAlchemyJobStore
from?apscheduler.executors.pool?import?ThreadPoolExecutor,?ProcessPoolExecutor
def?tick():
???print('Tick!?The?time?is:?%s'?%?datetime.now())
#?選擇MongoDB作為任務存儲數據庫
jobstores?=?{
???'mongo':?MongoDBJobStore(),
???'default':?SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
#?默認使用線程池
executors?=?{
???'default':?ThreadPoolExecutor(20),
???'processpool':?ProcessPoolExecutor(5)
}
#?默認參數配置
job_defaults?=?{
???'coalesce':?False,??#?積攢的任務是否只跑一次,是否合并所有錯過的Job
???'max_instances':?3,??#?默認同一時刻只能有一個實例運行,通過max_instances=3修改為3個。
???'misfire_grace_time':?30??#?30秒的任務超時容錯
}
scheduler?=?BackgroundScheduler(jobstores=jobstores,?executors=executors,?job_defaults=job_defaults,?timezone=utc)
scheduler.add_job(tick,?'interval',?seconds=3)
scheduler.start()方法2
from?apscheduler.schedulers.background?import?BackgroundScheduler
#?The?"apscheduler."?prefix?is?hard?coded
scheduler?=?BackgroundScheduler({
???'apscheduler.jobstores.mongo':?{
????????'type':?'mongodb'
???},
???'apscheduler.jobstores.default':?{
???????'type':?'sqlalchemy',
???????'url':?'sqlite:///jobs.sqlite'
???},
???'apscheduler.executors.default':?{
???????'class':?'apscheduler.executors.pool:ThreadPoolExecutor',
???????'max_workers':?'20'
???},
???'apscheduler.executors.processpool':?{
???????'type':?'processpool',
???????'max_workers':?'5'
???},
???'apscheduler.job_defaults.coalesce':?'false',
???'apscheduler.job_defaults.max_instances':?'3',
???'apscheduler.timezone':?'UTC',
})方法3
from?pytz?import?utc
from?apscheduler.schedulers.background?import?BackgroundScheduler
from?apscheduler.jobstores.sqlalchemy?import?SQLAlchemyJobStore
from?apscheduler.executors.pool?import?ProcessPoolExecutor
jobstores?=?{
???'mongo':?{'type':?'mongodb'},
???'default':?SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors?=?{
???'default':?{'type':?'threadpool',?'max_workers':?20},
???'processpool':?ProcessPoolExecutor(max_workers=5)
}
job_defaults?=?{
???'coalesce':?False,
???'max_instances':?3
}
scheduler?=?BackgroundScheduler()
#?..這里可以添加任務
scheduler.configure(jobstores=jobstores,?executors=executors,?job_defaults=job_defaults,?timezone=utc)
misfire_grace_time:如果一個job本來14:00有一次執行,但是由于某種原因沒有被調度上,現在14:01了,這個14:00的運行實例被提交時,會檢查它預訂運行的時間和當下時間的差值(這里是1分鐘),大于我們設置的30秒限制,那么這個運行實例不會被執行。合并:最常見的情形是scheduler被shutdown后重啟,某個任務會積攢了好幾次沒執行如5次,下次這個job被submit給executor時,執行5次。將coalesce=True后,只會執行一次
replace_existing: 如果在程序初始化時,是從數據庫讀取任務的,那么必須為每個任務定義一個明確的ID,并且使用replace_existing=True,否則每次重啟程序,你都會得到一份新的任務拷貝,也就意味著任務的狀態不會保存。
![nginx php image,[Docker]應該把 nginx 和 PHP 放在一個 image 里還是分開?](http://pic.xiahunao.cn/nginx php image,[Docker]應該把 nginx 和 PHP 放在一個 image 里還是分開?)




...)













