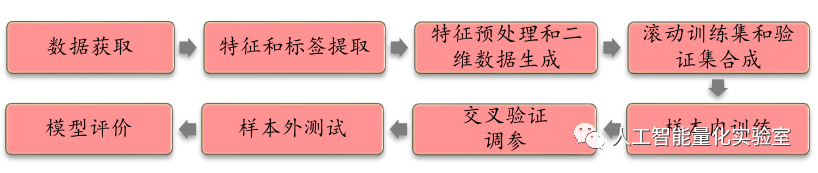
首先,我們先來看一下通過卷積神經網絡選股模型的整體流程,然后再根據每一步流程進行介紹,具體如下圖所示:
1、數據獲取
用于歷史回測數據來自所有A股股票,其中剔除了ST股以及上市3個月的股票,另外,每只股票是做一個樣本。回測的區間是從2011年1月31日到2019年1月31日。
2、特征和標簽提取
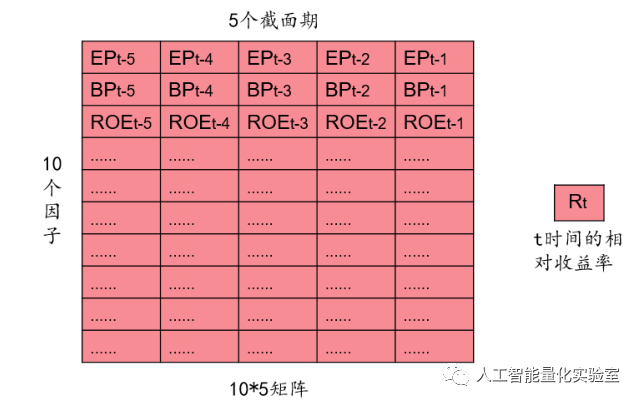
通過CNN進行分類預測時,必然需要進行對特征進行提取并進行標簽的標注工作。其中,樣本特征是根據每個自然月的最后一個交易日計算82個因子值,作為原始特征。由于卷積神經網絡需要提供二維的平面數據,所以這里選取的每個樣本數據考慮了5個歷史截面期,這樣得到的數據就是一個82×5的因子圖片了。下面展示了某個股10個因子,5個歷史截面期時的因子圖片。其中,t表示事件截面的時間周期刻度。這樣,如果在一個時間截面上有3000支股票,那么就可以得到3000張個股的因子圖片了。
對于分類問題,其標簽是根據下個月的排名進行設置,其中收益前30%的股票作為正例,后30%的股票作為負例,以此作為樣本的標簽。
3、特征預處理和二維數據生成
這部分主要包括對因子序列去極值,處理缺失值以及對因子序列進行標準化處理等。然后根據前面的要求的形式,將其轉換為因子圖片,這樣在每個月的截面上,就可以得到所有股票池中的截面數據了。下圖中列出了用到的82中因子的一部分。

4、滾動訓練集和驗證集的合成
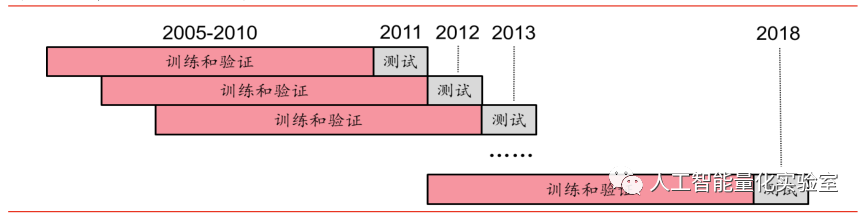
由于按照月度滾動的形式進行訓練,時間開銷會比較大,所以文中采用的是年度滾動的訓練方式。即全體樣本內外數據分為九個階段,例如預測2011年時,將2005年到2010年共72個月的數據合并作為樣本內數據,預測T年時,將T-6到T-1年的72個月合并為樣本內數據,具體如下圖所示。
5、樣本內訓練
使用卷積神經網絡對訓練集的數據進行訓練。
6、交叉驗證調參
隨機選取10%訓練樣本內的數據作為驗證集,每次在驗證集上的loss達到最小時,停止訓練。
7、樣本外測試
在確定最優參數之后,以T月截面期所有樣本預處理后的特征作為模型的輸入,得到對于每個樣本的預測值,并將預測值作為合成后的因子,對單因子進行分層回測。
8、模型評價
通過分層回測和構建的選股策略的結果作為模型評價的標準。









學習如何在Facebook上賣貨...)





![php 驗證碼字體居中,自定義驗證碼圖片的寬高后文本垂直水平居中[帝國cms ShowKey.php]-網站程序網...](http://pic.xiahunao.cn/php 驗證碼字體居中,自定義驗證碼圖片的寬高后文本垂直水平居中[帝國cms ShowKey.php]-網站程序網...)



...)