
一筆業務數據在區塊鏈處理的流程大致分為三個階段:分別是上鏈前處理階段、鏈上處理階段和智能合約處理階段。
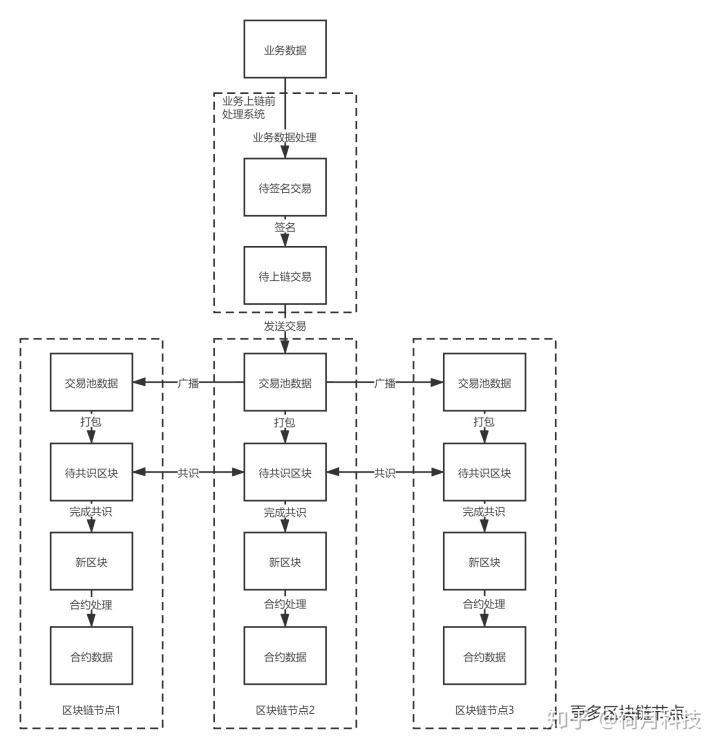
一.上鏈前處理階段
業務數據上鏈前需要將業務數據處理,并且對信息進行簽名。這些過程可以通過對應的工具,比如序列化工具和各種橢圓曲線的簽名工具來完成,不過更多的時候是通過將各種工具集成的SDK來完成,以太坊的web3就是比較典型的上鏈前處理的開發工具。業務數據處理
業務數據可以是任意的內容,比如物流信息、商品交易或物聯網設備上傳的數據或者對應數據的哈希值等等。這些業務數據既可以通過服務器處理,也可通過物聯網設備的邊緣計算系統處理。以存證用的物流數據舉例,首先對業務數據不需要進一步處理或者簡單計算一下哈希值,然后將調用函數的信息加上鏈數據放入交易結構體的相關部分當中即可。簽名前的交易結構體是由鏈決定的,不過一般都包含調用的合約、時間戳、隨機數和調用函數加數據的信息。將簽名前的數據拼裝好之后,會進一步序列化以便消息傳遞。對于一些隱私交易,需要用到同態加密或者零知識證明等算法,此時業務數據則需要經過更復雜的加工過程,比如數字經過處理可以變成一個乘方求模的大數或者橢圓曲線上的點,但是拼裝和序列化等過程還是相同的處理方式。
信息簽名
簽名前的數據處理好之后,對該數據進行一次哈希處理,并對哈希進行簽名。哈希是與數據綁定的一串值,篡改信息會造成哈希值發生變化,因此本身具有防篡改的特性。接下來是對信息的哈希值進行簽名。簽名是一種非對稱加密的方法,可以在不泄露發送者本身的私鑰的情況下,通過公鑰和簽名信息確認發送者持有對應的私鑰。對哈希進行簽名還可將發送者的身份和信息綁定,同時也可防止其他人冒充發送者,因此這樣處理可保證信息的防篡改的同時認證發送者的身份,防止抵賴。
業務上鏈前的處理階段主要是通過工具將業務數據轉換成區塊鏈可讀的方式,同時通過簽名將發送者的身份和發送信息綁定,起到身份認證和防止抵賴的作用,最后再將處理好的信息發送到區塊鏈節點。上鏈前處理是中心化的,這些處理過程并不涉及區塊鏈節點,因此這一階段并不需要節點參與。有些系統,如邊緣計算系統,本身的性能和儲存空間都有限,并不適合做區塊鏈節點,但可以作為業務上鏈前處理的平臺。
二.上鏈處理階段
處理完成的數據發送到區塊鏈節點后,就形成了一筆區塊鏈交易并進入上鏈處理的階段,鏈上處理大體可分為交易廣播和區塊共識流程。
交易廣播
在收到交易后,各節點會將接收到的交易先廣播到其他節點,以便形成一個統一的交易池來為達成共識做準備。交易廣播后聯盟鏈和公鏈對交易會有不同的處理方法。對公鏈來說,任何交易發送者都可將交易發送到鏈上,但是處理能力不是無限的,因此會根據交易的手續費行有選擇的處理,手續費低的交易很可能一直無法得到處理。在一些極端情況下,節點為了提高處理速度甚至會出現不處理任何交易的空塊。對聯盟鏈來說有一定的準入機制,能夠發送交易的應該是合作伙伴,因此處理交易的原則是盡量將能夠處理的交易打包進塊。
區塊共識
區塊主要包含區塊哈希、區塊頭和交易數據的信息,其中區塊頭一般都會包含共識信息、時間戳、區塊高度等,并記錄前一區塊的哈希來指向前一區塊;交易數據包含該區塊里打包交易的哈希,交易需要根據統一的順序排序;在確認區塊頭和哈希之后,就能計算區塊哈希。這樣通過前一區塊哈希和自身哈希相連形成鏈條,修改鏈上的任何一個區塊的內容會后面區塊的前一區塊哈希和修改后的哈希不同,因此區塊具有防篡改的特性。只有修改該區塊和往后所有區塊的內容,且每個節點上都以相同方式修改才能完成修改。共識的主要目的就是以某種約定的方式生成能夠被大部分節點認可的區塊。不同共識方式的區別比較大,但是基本原則就是讓不同節點產生相同的區塊,盡可能保證數據的一致性。對公鏈來說,因為節點的通訊狀況不可控,保證一直出塊的情況下,如果網絡出現問題,將可能無法達成一致,甚至出現分叉的情況。對聯盟鏈來說,共識算法需要盡量使節點的區塊數據保持一致性,因此在一定數量的節點出現網絡問題的情況下將會停止出塊。上鏈處理階段是將業務數據寫入區塊的過程,這個過程就是通常所說的上鏈,這一過程是去中心化的,需要由節點處理。在處理階段時業務數據還是可以按照發送者的意愿寫入不同內容,而進入上鏈階段后的業務數據將無法篡改,不過仍然存在上鏈失敗的可能,因此仍需要關注是否完成上鏈。共識階段完成后,各節點的區塊保持一致。此時的業務數據獲得每個節點承認且可追溯的數據了。
三.智能合約處理階段
上鏈處理完成后,業務數據已經記錄在鏈上了,對于單純存證的業務來說,將業務信息寫入區塊已經完成了這筆業務處理,只需記錄存證業務的交易哈希并在取的時候通過交易哈希查詢即可。但是大部分業務場景都需要進行一定的邏輯處理,因此通過智能合約處理是必須的。智能合約處理包括合約邏輯處理以及修改狀態梅克爾樹等流程。合約邏輯處理
完成上鏈的業務數據很多情況下需要進一步進行邏輯的處理,比如一次最簡單的商品的交易就涉及轉賬,即買家余額減少和賣家余額增加的邏輯流程,這樣的流程雖然可以通過上鏈前的處理來完成,但是上鏈前處理是中心化的流程,對網絡波動和可信度問題都有一定的劣勢,因此通過智能合約進行邏輯處理是比較好的方式。不同鏈平臺對智能合約處理的方式不同,但是和一般的編程語言一樣都有調用函數和傳入參數的過程。并且因為創建智能合約和調用智能合約的過程都是上鏈的,即執行的程序和調用的函數與參數都是經過共識的,因此最終調用智能合約的數據的輸出結果也是相同的。處理完后的結果會寫入合約的狀態數據庫,這個數據庫除了最新狀態也會包含歷史狀態,方便追溯和查詢。
修改狀態梅克爾樹
智能合約的邏輯處理完成后,會修改狀態梅克爾樹。梅克爾樹是一個二叉樹結構,不同的葉通過梅克爾樹鏈接到根,能起到防篡改和索引的作用。通過梅克爾樹的索引,能夠快速定位合約的歷史狀態,可通過查詢某個業務執行的區塊高度的合約數據來獲取當時的執行結果。智能合約處理階段是將業務數據進行邏輯處理,并記錄智能合約狀態的過程,這一過程也需要節點處理。如果合約邏輯處理的操作執行失敗,對狀態梅克爾樹的修改也會撤銷,合約的數據將會回滾到調用前的歷史數據。需要注意的是合約調用失敗和上鏈失敗是有區別的,觸發合約調用的時候交易已經在區塊里留下記錄,而區塊是防篡改的,因此調用失敗并不會擦除區塊里的記錄。如果交易因為數據錯誤或者共識問題而沒有被記錄進區塊,則不會觸發合約處理的過程。





)






...)






