PyTorch 分布式訓練DDP 單機多卡快速上手
本文旨在幫助新人快速上手最有效的 PyTorch 單機多卡訓練,對于 PyTorch 分布式訓練的理論介紹、多方案對比,本文不做詳細介紹,有興趣的讀者可參考:
[分布式訓練] 單機多卡的正確打開方式:理論基礎
當代研究生應當掌握的并行訓練方法(單機多卡)
DP與DDP
我們知道 PyTorch 本身對于單機多卡提供了兩種實現方式
- DataParallel(DP):Parameter Server模式,一張卡位reducer,實現也超級簡單,一行代碼。
- DistributedDataParallel(DDP):All-Reduce模式,本意是用來分布式訓練,但是也可用于單機多卡。
DataParallel是基于Parameter server的算法,實現比較簡單,只需在原單機單卡代碼的基礎上增加一行:
model = nn.DataParallel(model, device_ids=config.gpu_id)
但是其負載不均衡的問題比較嚴重,有時在模型較大的時候(比如bert-large),reducer的那張卡會多出3-4g的顯存占用。
并且速度也比較慢:
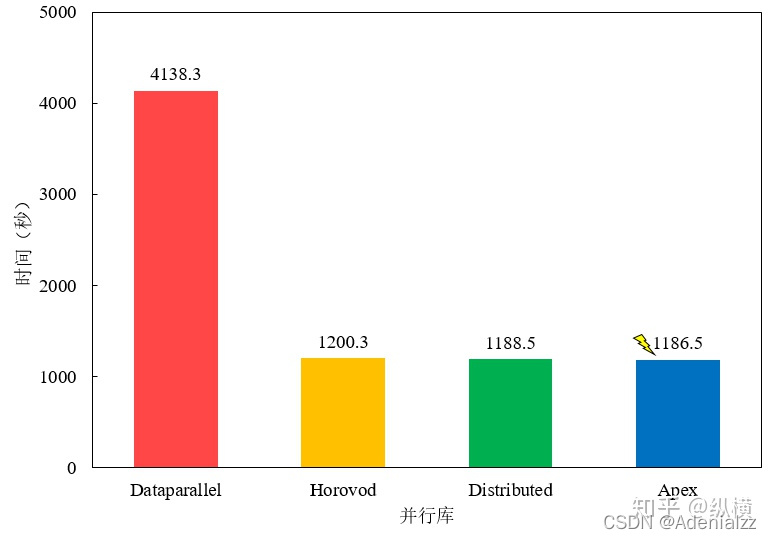
(圖像來自:當代研究生應當掌握的并行訓練方法(單機多卡)[][])
DistributedDataParallel
官方建議用新的DDP,采用all-reduce算法,本來設計主要是為了多機多卡使用,但是單機上也能用。
首先明確幾個概念:
-
rank
多機多卡:代表某一臺機器
單機多卡:代表某一塊GPU
-
world_size
多機多卡:代表有幾臺機器
單機多卡:代表有幾塊GPU
-
local_rank
多機多卡:代表某一塊GPU的編號
單機多卡:代表某一塊GPU的編號
單機單卡訓練代碼
我們先給出一個單機單卡訓練代碼的 demo,簡單地跑一下數據流。麻雀雖小,五臟俱全。這個 demo 包含了我們平時深度學習訓練過程中的完整步驟。包括模型、數據集的定義與實例化,損失函數,優化器的定義,梯度清零、梯度反傳,優化器迭代更新以及訓練日志的打印。
接下來我們將會使用 PyTorch 提供的 DistributedDataParallel 把這個單機單卡的訓練過程改裝為單機多卡并行訓練。
import torch
import torch.nn as nn
from torch.optim import SGD
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
import os
import argparseparser = argparse.ArgumentParser()
parser.add_argument('--gpu_id', type=str, default='0,2')
parser.add_argument('--batchSize', type=int, default=32)
parser.add_argument('--epochs', type=int, default=5)
parser.add_argument('--dataset-size', type=int, default=128)
parser.add_argument('--num-classes', type=int, default=10)
config = parser.parse_args()os.environ['CUDA_VISIBLE_DEVICES'] = config.gpu_id# 定義一個隨機數據集,隨機生成樣本
class RandomDataset(Dataset):def __init__(self, dataset_size, image_size=32):images = torch.randn(dataset_size, 3, image_size, image_size)labels = torch.zeros(dataset_size, dtype=int)self.data = list(zip(images, labels))def __getitem__(self, index):return self.data[index]def __len__(self):return len(self.data)# 定義模型,簡單的一層卷積加一層全連接softmax
class Model(nn.Module):def __init__(self, num_classes):super(Model, self).__init__()self.conv2d = nn.Conv2d(3, 16, 3)self.fc = nn.Linear(30*30*16, num_classes)self.softmax = nn.Softmax(dim=1)def forward(self, x):batch_size = x.shape[0]x = self.conv2d(x)x = x.reshape(batch_size, -1)x = self.fc(x)out = self.softmax(x)return out# 實例化模型、數據集、加載器和優化器
model = Model(config.num_classes)
dataset = RandomDataset(config.dataset_size)
loader = DataLoader(dataset, batch_size=config.batchSize, shuffle=True)
loss_func = nn.CrossEntropyLoss()if torch.cuda.is_available():model.cuda()
optimizer = SGD(model.parameters(), lr=0.1, momentum=0.9)# 若使用DP,僅需一行
# if torch.cuda.device_count > 1: model = nn.DataParallel(model)
# 我們不用DP,而將用DDP# 開始訓練
for epoch in range(config.epochs):for step, (images, labels) in enumerate(loader):if torch.cuda.is_available(): images = images.cuda()labels = labels.cuda()preds = model(images)loss = loss_func(preds, labels)optimizer.zero_grad()loss.backward()optimizer.step()print(f'Step: {step}, Loss: {loss.item()}')print(f'Epoch {epoch} Finished !')
訓練日志輸出為:
Step: 0, Loss: 1.4611507654190063
Step: 1, Loss: 1.4611507654190063
...
Step: 7, Loss: 1.4611507654190063
Epoch 0 Finished !
...
修改代碼
使用 PyTorch 提供的 DistributedDataParallel 將單機單卡的訓練代碼為單機多卡的并行訓練代碼需要以下幾個步驟:
-
初始化
torch.distributed.init_process_group(backend="nccl") local_rank = torch.distributed.get_rank() torch.cuda.set_device(local_rank) device = torch.device("cuda", local_rank) -
設置模型并行
model=torch.nn.parallel.DistributedDataParallel(model) -
設置數據并行
from torch.utils.data.distributed import DistributedSampler sampler = DistributedSampler(dataset) # 這個sampler會自動分配數據到各個gpu上 loader = DataLoader(dataset, batch_size=batch_size, sampler=sampler)
在上面單機單卡的代碼合適位置中增添這么幾行即可。
DDP多卡訓練的啟動
另外需要注意的是,單機多卡的啟動與平時的 python ddp_demo.py 也不一樣,需要:
python -m torch.distributed.launch --nproc_per_node 2 ddp_demo.py --batchSize 64 --epochs 10 --gpu_id 1,2
# 或 torchrun --nproc_per_node=2 ddp_demo.py --batchSize 64 --epochs 10
其中 --nproc_per_node 是我們要使用的顯卡數量。argparse 的參數加在后面即可。
注意 --local_rank 不是由我們手動指定。
DDP多卡訓練的日志輸出
還有,由于 DDP 多卡訓練是多進程進行的,每個進程都會打印一遍日志輸出。即會出現類似這種輸出:
Step: 0, Loss: 1.4611507654190063
Step: 0, Loss: 1.4611507654190063
Step: 1, Loss: 1.4611507654190063
Step: 1, Loss: 1.4611507654190063
...
Step: 7, Loss: 1.4611507654190063
Step: 7, Loss: 1.4611507654190063
Epoch 0 Finished !
Epoch 0 Finished !
...
因此在訓練驗證過程中的日志記錄輸出也要注意:
在啟動器啟動python腳本后,在執行過程中,啟動器會將當前進程的 index 通過參數傳遞給 python,我們可以這樣獲得當前進程的 index:即通過命令行參數 --local_rank 來告訴我們當前進程使用的是哪個GPU,用于我們在每個進程中指定不同的device(也有其他的方式來獲取當前進程)。進程可以簡單理解為運行一個代碼,分布式訓練采用多GPU多進程的方式,即每個進程都要獨立運行一份訓練代碼,由此,為每個GPU分配一個進程進行分布式訓練。通常不需要在每個進程中都有日志或其他信息(模型權重等)的輸出,即可以通過--local_rank來指定打印日志或其他信息(模型權重等)的進程。
查看當前設備
我們可以在訓練循環里加上一行,來查看當前進程時在哪個GPU上進行計算的:
print(f"data: {images.device}, model: {next(model.parameters()).device}")
注意這里我們的 model.parameters() 實際上是 Python 中的一個生成器,因此,需要用 next() 方法來取得其中一個,查看其所在設備。
部分輸出:
Epoch 0 Finished !
data: cuda:0, model: cuda:0
data: cuda:1, model: cuda:1
...
data: cuda:0, model: cuda:0
data: cuda:1, model: cuda:1
data: cuda:0, model: cuda:0
data: cuda:1, model: cuda:1
Epoch 1 Finished !
...
可以看到,在我們的DDP多進程單機多卡訓練中,在兩個設備上都會有訓練數據和模型的分布,并且也都會打印出來。
附錄:完整DDP訓練代碼
# ddp_demo.py
import torch
import torch.nn as nn
from torch.optim import SGD
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSampler
import os
import argparse# 定義一個隨機數據集
class RandomDataset(Dataset):def __init__(self, dataset_size, image_size=32):images = torch.randn(dataset_size, 3, image_size, image_size)labels = torch.zeros(dataset_size, dtype=int)self.data = list(zip(images, labels))def __getitem__(self, index):return self.data[index]def __len__(self):return len(self.data)# 定義模型
class Model(nn.Module):def __init__(self, num_classes):super(Model, self).__init__()self.conv2d = nn.Conv2d(3, 16, 3)self.fc = nn.Linear(30*30*16, num_classes)self.softmax = nn.Softmax(dim=1)def forward(self, x):batch_size = x.shape[0]x = self.conv2d(x)x = x.reshape(batch_size, -1)x = self.fc(x)out = self.softmax(x)return outparser = argparse.ArgumentParser()
parser.add_argument('--gpu_id', type=str, default='0,2')
parser.add_argument('--batchSize', type=int, default=64)
parser.add_argument('--epochs', type=int, default=5)
parser.add_argument('--dataset-size', type=int, default=1024)
parser.add_argument('--num-classes', type=int, default=10)
config = parser.parse_args()os.environ['CUDA_VISIBLE_DEVICES'] = config.gpu_id
torch.distributed.init_process_group(backend="nccl")local_rank = torch.distributed.get_rank()
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)# 實例化模型、數據集和加載器loader
model = Model(config.num_classes)dataset = RandomDataset(config.dataset_size)
sampler = DistributedSampler(dataset) # 這個sampler會自動分配數據到各個gpu上
loader = DataLoader(dataset, batch_size=config.batchSize, sampler=sampler)# loader = DataLoader(dataset, batch_size=config.batchSize, shuffle=True)
loss_func = nn.CrossEntropyLoss()if torch.cuda.is_available():model.cuda()
model = torch.nn.parallel.DistributedDataParallel(model)
optimizer = SGD(model.parameters(), lr=0.1, momentum=0.9)# 開始訓練
for epoch in range(config.epochs):for step, (images, labels) in enumerate(loader):if torch.cuda.is_available(): images = images.cuda()labels = labels.cuda()preds = model(images)# print(f"data: {images.device}, model: {next(model.parameters()).device}")loss = loss_func(preds, labels)optimizer.zero_grad()loss.backward()optimizer.step()print(f'Step: {step}, Loss: {loss.item()}')print(f'Epoch {epoch} Finished !')啟動訓練(以兩張卡為例):
torchrun --nproc_per_node=2 ddp_demo.py --batchSize 64 --epochs 10
Ref:
https://blog.csdn.net/weixin_44966641/article/details/121015241
https://zhuanlan.zhihu.com/p/98535650
https://zhuanlan.zhihu.com/p/384893917






)






)





