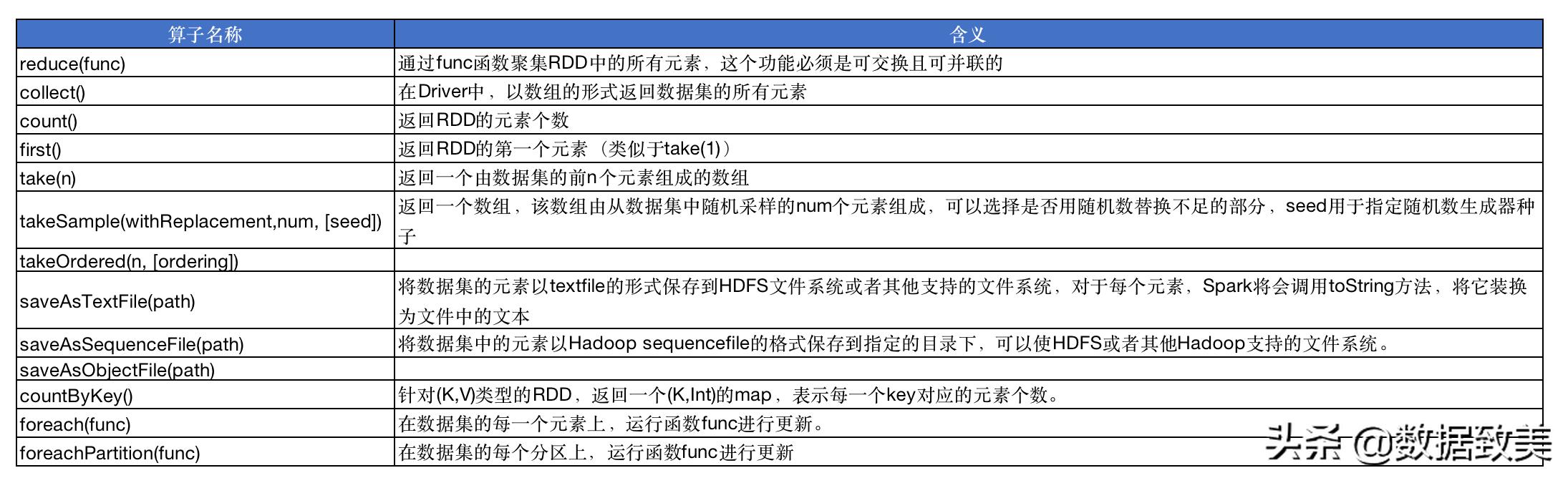
常用Action類算子列表
- reduce(func): 通過func函數來對RDD中所有元素進行聚合運算,先運算分區內數據,再運算分區間數據。
scala> val rdd1 = sc.makeRDD(1 to 100)rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[4] at makeRDD at :24# 對1到100進行求和scala> rdd1.reduce(_+_)res4: Int = 5050
- collect(): 在驅動程序Driver中或存儲到HDFS等存儲工具中,以數組的形式返回數據集的所有元素。
scala> val rdd1 = sc.makeRDD(1 to 10)rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[5] at makeRDD at :24scala> rdd1.collect()res5: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> val rdd1 = sc.makeRDD(1 to 100)rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[6] at makeRDD at :24scala> rdd1.count()res6: Long = 100
scala> val rdd1 = sc.makeRDD(5 to 20)rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[7] at makeRDD at :24scala> rdd1.first()res7: Int = 5
- take(num): 返回RDD中前num個元素組成的數據,當num=1時,相當于first()
scala> val rdd1 = sc.makeRDD(1 to 10)rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[8] at makeRDD at :24scala> rdd1.take(5)res8: Array[Int] = Array(1, 2, 3, 4, 5)
- takeOrdered(n): 返回原RDD排序(默認升序排)后,前n個元素組成的數組。
scala> val rdd1 = sc.makeRDD(Array(1,4,6,2,5,8,3,6,9))rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at makeRDD at :24scala> rdd1.takeOrdered(5)res9: Array[Int] = Array(1, 2, 3, 4, 5)
- aggregate(zeroValue)(seqOp, combOp): 與key-value類型RDD的轉換算子aggregateByKey類似,同樣是三個參數:初始值zeroValue,分區內函數seqOp,分區間函數combOp,只不過它是一個action算子,觸發執行。
scala> val rdd1 = sc.makeRDD(Array(1,2,3,4,5,6),2)rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[11] at makeRDD at :24scala> import scala.math._import scala.math._scala> rdd1.aggregate(4)(max(_,_),_+_)res10: Int = 14
- countByKey(): 前面count執行算子是計算RDD中元素個數,countByKey是針對(K,V)類型的RDD,返回一個(K,Int)類型的map,表示每一個key對應的元素個數。
scala> val rdd1 = sc.parallelize(Array(("a",100),("a",200),("a",300),("b",1),("b",10),("c",1000)))rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[12] at parallelize at :27# Key為"a"的有3個,key為"b"的有兩個,key為以的有"1"個,與value無關scala> rdd1.countByKey()res11: scala.collection.Map[String,Long] = Map(b -> 2, a -> 3, c -> 1)
- countByValue(): 對RDD中的(k,v)整體進行計數
scala> val rdd1 = sc.parallelize(Array(("a",100),("a",200),("a",200),("b",10),("b",10),("c",1000)))rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[15] at parallelize at :27scala> rdd1.countByValue()res12: scala.collection.Map[(String, Int),Long] = Map((c,1000) -> 1, (a,200) -> 2, (b,10) -> 2, (a,100) -> 1)
- foreach(func): 遍歷原RDD元素經過func函數運算過后的結果集
scala> val rdd1 = sc.makeRDD(1 to 10)rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[19] at makeRDD at :27scala> rdd1.foreach(println)12345678910
- foreachPartition(func): 按分區遍歷原RDD元素經過func函數運算過后的結果, 尤其在這里有插入數據的動作時,需要頻繁地創建連接與關閉連接,所以一個分區一個分區的處理效率高,減少gc
scala> val rdd1 = sc.makeRDD(1 to 10, 3)rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[23] at makeRDD at :27# 一個分區只創建一次連接scala> rdd1.foreachPartition(iter => {println("打開數據庫連接");iter.foreach(x=>{println("拼拉sql, 插入數據庫");x});println("關閉數據庫連接")})打開數據庫連接拼拉sql, 插入數據庫拼拉sql, 插入數據庫拼拉sql, 插入數據庫關閉數據庫連接打開數據庫連接拼拉sql, 插入數據庫拼拉sql, 插入數據庫拼拉sql, 插入數據庫拼拉sql, 插入數據庫關閉數據庫連接打開數據庫連接拼拉sql, 插入數據庫拼拉sql, 插入數據庫拼拉sql, 插入數據庫關閉數據庫連接




是啥意思?...)














